标签:可见 向量 ext 数据集 反向 案例 重构 描述 text
这几天继续学习一篇论文,Hinton的A Fast Learning Algorithm for Deep Belief Nets。这篇论文一开始读起来是相当费劲的,学习了好几天才了解了相关的背景,慢慢的思路也开始清晰起来。DBN算法就是Wake-Sleep算法+RBM,但是论文对Wake-Sleep算法解释特别少。可能还要学习Wake-Sleep和RBM相关的的知识才能慢慢理解,今天先说说A Fast Learning Algorithm for Deep Belief Nets这篇论文。
1,我们展示了如何使用“互补的先验”来消除解释的影响,这使得在紧密连接的置信网络中很难有许多隐藏的层。
2,利用互补的先验知识,我们推导出一种快速、贪婪的算法,可以学习深入的、有向的置信网络一层一层,提供了最上层的两层,形成一个无定向的联想记忆。
3,快速、贪婪算法用于初始化一个较慢的学习过程,该过程用一个对比版本的wake-sleep算法对权重进行微调。
4,经过微调后,一个带有三个隐藏层的网络形成了一个非常好的生成模型,它是手写数字图像和它们的标签的联合分布。
5,这种生成模型给出的数字分类比最好的鉴别学习算法更好。
6,这些数字所在的低维度的流形,是由顶级联想记忆的自由能景观中的长沟壑建模的,通过使用直接连接来显示联想记忆,很容易就能发现这些沟壑。
1,在密集的、有导向的置信网络中,学习是困难的,因为它有许多隐藏的层,因为在给定一个数据向量时很难推断隐藏活动的条件分布。
2,我们描述了一个模型,其中最上面的两个隐藏层形成一个无定向的联想记忆(见图1),其余的隐藏层形成一个有向的非循环图,将联想记忆中的表示转换成可观察的变量,如图像的像素。这种混合模式具有一些吸引人的特点:
(1)有一种快速、贪婪的学习算法,可以快速找到一组相当好的参数,即使是在具有数百万参数和许多隐藏层的深度网络中。
(2)学习算法是无监督的,但可以通过学习生成标签和数据的模型来应用于标记数据。
(3)有一种微调算法,它学习了一种优秀的生成模型,该模型在手写数字的MNIST数据库中优于鉴别方法。
(4)生成模型可以很容易地解释深层隐藏层中的分布式表示。
(5)形成一个规则所需要的推理既快速又准确。
(6)学习算法是局部的。对突触强度的调整仅依赖于突触前神经元和突触后神经元的状态。
(7)沟通是很简单的。神经元只需要交流它们的随机二进制状态。
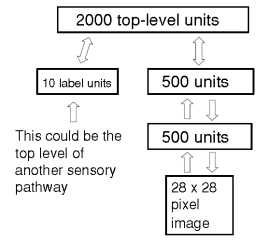
图1:用于模拟数字图像和数字标签的联合分布的网络。在这篇文章中,每个训练案例都包含一个图像和一个显式的类标签,但是在进展中的工作已经表明,如果“标签”被一个多层路径所替代,那么同样的学习算法也可以被使用,因为它的输入是来自多个不同的光谱图,它们说的是孤立的数字。然后,网络学习生成由一个图像和一个相同数字类的光谱图组成的对。
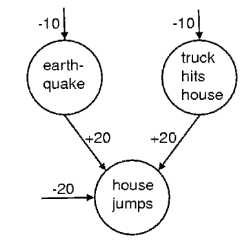
图2:一个简单的逻辑置信网络,包含两个独立的、罕见的原因,当我们观察房子的跳跃时,它会变得高度的反相关。在地震节点上的。-10的偏差意味着,在没有任何观察的情况下,这个节点要比on的可能性大e10倍。如果地震节点是on,而卡车节点是off,则跳转节点的总输入值为0,这意味着它甚至有可能处于on状态。这是一种更好的解释,解释了为什么房子跳得比e-20的概率高。如果两个隐藏的原因都不活跃,则适用。但是,打开两个隐藏的原因来解释观察结果是一种浪费,因为两者发生的概率都是e-10×e-10 = e-20。当地震节点被打开时,它会“解释”卡车节点的证据。
第2节介绍了“互补”的概念,这一概念正好抵消了“解释消失”现象,这使得在有导向的模型中推理困难。给出了一个具有互补先验的有向信念网络的例子。
logistic置信网络(Neal, 1992)由随机二进制单元组成。当网络用于生成数据时,打开单元i的概率是它的直系上代j,和权值,wi j,从上代的直接连接上的逻辑函数。
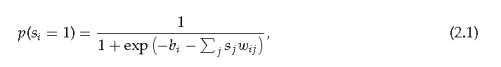
我们可以从无限生成数据直接在图3中,从一个随机的配置在一个无限深隐层,然后执行一个自上而下的“祖先”在每个变量的二进制状态选择一层从伯努利分布由自上而下的输入来自其活跃的“父母”在上面的层。
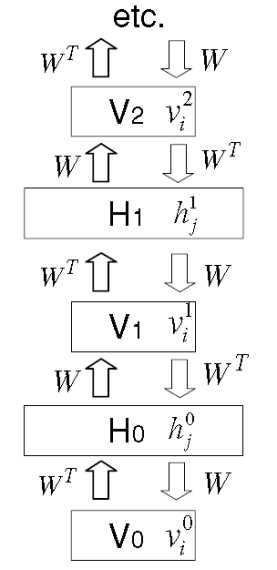
图3:一个带着权重的无限的逻辑信念网。向下的箭头表示生成模型。向上的箭头不是模型的一部分。当数据向量被夹在V0上时,它们表示用于从网络的每个隐层中推断样本的参数。
我们可以从真实的后验中取样,我们可以计算出数据的对数概率的导数。让我们先计算一个生成权的导数wi j00,从H0的一个单位j,到第i层V0的单位i(见图3)。在一个逻辑推理网络中,一个数据向量V0的最大似然学习规则是:

其中<·>表示采样状态的平均值,而v0 i是如果从采样的隐藏状态中随机地重建可见向量,则可以打开单元i的概率。计算后验分布在第二个隐藏层,V1,从采样二进制州第一隐层,H0,是完全一样的过程重构数据,所以V1我是伯努利随机变量样本概率?v0我。因此,学习规则可以写成:

v1i对h0j的依赖性在方程2.3的推导中是无问题的,因为v0i是基于h0j的期望。由于权重被复制,因此,通过对各层之间的生成权的导数相加,得到生成权的完整导数:
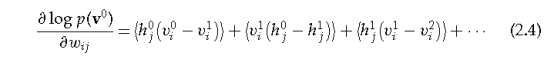
除第一次和最后一次取消外,所有的成对产品都退出了公式3.1的玻尔兹曼机器学习规则。
第3节展示了受限的玻尔兹曼机器与有束缚权的无限定向网络之间的等价性。
图3中的无限定向网络与受限制的玻尔兹曼机(RBM)是等价的。RBM有一层隐藏单元,它们之间没有相互连接,并且没有定向的、对称的连接到一层可见单元。
为了在RBM中执行最大似然学习,我们可以使用两个相关性之间的差异。对于每一个权重,wi j,在一个可见的单位i和一个隐藏的单位j之间,我们测量关联<v0i h0j>当一个数据向量被夹持在可见的单位上时,隐藏的状态被从它们的条件分布中取样,这是阶乘。然后,利用交替的吉布斯抽样,我们运行了图4中所示的马尔可夫链,直到它到达其平稳分布并测量相关 <v∞i h∞j>。训练数据的对数概率的梯度是:

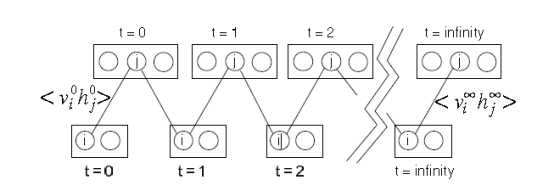
图4:这幅图描述了一个使用交替的吉布斯采样的马尔可夫链。在吉布斯采样的一个完整步骤中,顶层的隐藏单元都是通过应用等式2.1得到的,从底层的可见单元的当前状态得到的输入进行并行更新;然后,在当前隐藏状态下,所有可见单元都是并行更新的。所有的更新都是平行于当前隐藏状态。初始化链通过设置可见单元的二进制状态与数据向量相同。将可见单元的二进制状态设置为与数据向量相同,从而初始化链。一个可见的和一个隐藏单元的活动之间的相关性是在隐藏单元的第一次更新之后和在链的末端再次测量的。这两种关联的不同提供了学习信号来更新连接上的权重。
将数据的对数概率最大化,完全等同于将数据的分布、P0和由模型定义的均衡分布(P∞θ)之间的kullbackleibler散度,KL(P0||P∞θ)。在对比发散学习(Hinton, 2002)中,我们运行的马尔可夫链仅仅是n个完整的步骤,这是第二个相关的。对比发散学习最小化了两种相对熵:

值得注意的是,Pnθ依赖于当前的模型参数,以及当参数变化被对比发散学习忽略时,Pnθ的变化的方式。这个问题不会出现在P0中,因为训练数据不依赖于参数。
我们现在证明了RBMs和有关联权的无限定向网之间的等价性,这表明了一种有效的多层网络学习算法,在这个算法中,权重没有被束缚。
第4节介绍了一种快速、贪婪的构建多层定向网络的算法。使用一个变量绑定,它表明,随着每一个新层的加入,整个生成模型会得到改进。贪婪算法在重复使用相的“弱”学习者时,有一些相似之处,但不是重新加权每一个数据向量,以确保下一步学习新的东西,而是重新呈现它。“弱”的学习者被用来构造深定向的网本身就是一个无定向的图形模型。
图5显示了一个多层生成模型,其中顶部两层通过无定向连接进行交互,所有其他连接都是定向的。
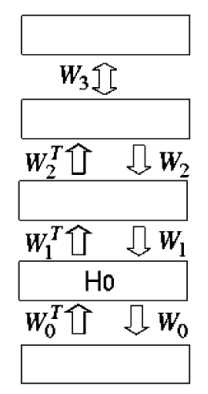
图5:混合网络。前两层有无定向连接,并形成联想记忆。下面的层有定向的、自顶向下的生成连接,可以用来将关联内存的状态映射到图像。也有定向的、自底向上的识别连接,用于从下面一层的二进制活动中推断一个层的阶乘表示。在贪婪的初始学习中,识别连接与生成连接联系在一起。
如果RBM是原始数据的完美模型,更高级别的“数据”将已经被更高级别的权重矩阵完美地表示了惋惜。然而,一般来说,RBM不能完美地实现原始数据,我们可以使用以下贪婪算法使生成模型更好:
1.学习W0假设所有的权矩阵都被束缚。
2.冻结W0并承诺使用WT0来推断在第一个隐藏层中变量的状态下的阶乘,即使在更高级别的权重的后续变化意味着这个推理方法不再正确。
3.将所有的高权重矩阵捆绑在一起,但从W0开始,学习使用WT0生成的更高级别“数据”的RBM模型,以转换原始数据。如果这种贪婪算法改变了较高的权重矩阵,就可以保证改进生成模型。
在多层生成模型下,单个数据向量v0的负对数概率受变分自由能的约束,这是近似分布下的期望能量,Q(h0|v0),减去该分布的熵。对于一个有向模型,配置v0, h0的“能量”是
由。
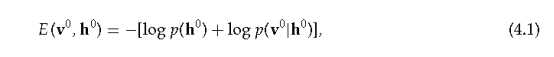
所以
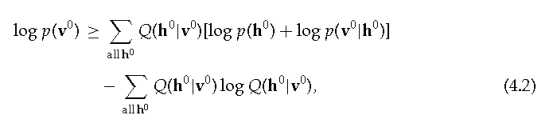
其中h0是第一个隐层中单位的二元配置,p(h0)是在当前模型下h0的先验概率(由h0上的权值定义),Q(·|v0)是在第一个隐含层中的二进制配置上的任何概率分布。当且仅当Q(·|v0)是真正的后验分布时,约束就变成了等式。
当所有权重矩阵都被捆绑在一起时,将WT0应用到一个数据向量上所产生的阶乘分布是真正的后验分布,因此在贪婪算法的第2步,logp (v0)等于边界。第2步冻结Q(·|v0)和p(v0|h0),并将这些项固定,绑定的导数与导数相同。

为了保证生成模型可以通过大量的学习层来改进,可以很方便地考虑所有层都是相同大小的模型,这样就可以将更高级别的权值初始化到从下面一层的权重中分离出来的值。然而,同样的贪婪算法,即使是不同的大小,也可以应用。
第5节展示了快速、贪婪算法产生的权重如何使用“向上向下”算法进行微调。这是wake-sleep算法(Hinton, Dayan, Frey, & Neal, 1995)的一种对比版本,它不受“模式-平均值”问题的困扰,因为这些问题会导致wake-sleep算法学习较差的识别权重。
附录B为图1中所示的网络使用matlabstyle伪代码指定了向上向下算法的详细信息。为了简单起见,在权值上没有惩罚,没有动量,所有参数的学习速率相同。同时,训练数据也减少到一个单一的情况。
第6节展示了一个具有三个隐藏层的网络的模式识别性能,以及在MNIST的手写数字上大约有170万的权重。当没有提供几何知识并且没有特殊的预处理时,网络的推广性能是1万位数的官方测试集的1.25%的错误,这超过了最好的反向传播网络在不为这个特定的应用程序手工制作时所获得的1.5%的误差。它也比Decoste和Schoelkopf(2002)报告的支持向量机在同一任务上所报告的1.4%的错误稍微好一些。
6.1培训网络
手写数字的MNIST数据库包含6万个训练图像和1万个测试图像。
在训练最顶层的权重(在关联内存中)时,标签是作为输入的一部分提供的。这些标签由10个单位的“softmax”组中的一个单元组成。当这一组的活动从上面一层的活动中重建时,只有一个单元被允许处于活动状态,而选择单元i的概率为。

其中xi是单元i接收到的总输入,奇怪的是,学习规则不受softmax组中单元之间的竞争影响,所以突触不需要知道哪个单元在与哪个单元竞争。竞争会影响一个单元打开的概率,但它只是影响学习的概率

图6:网络出错的125个测试案例。每个案例都被网络的猜测所标记。真正的类是按标准扫描顺序排列的。
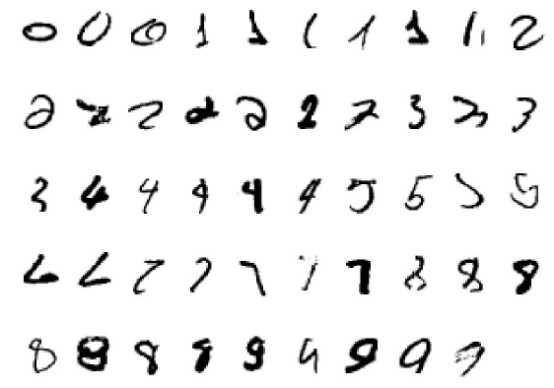
图7:所有49个网络猜测正确的案例,但有第二个测试,其概率在最佳猜测概率的0.3以内。真正的类是按标准扫描顺序排列的。
通过对训练数据进行稍微转换的数据集补充数据集,可以大幅度降低错误率。
一种测试网络的方法是使用一个随机向上传递的图像来固定在联想记忆的下一层的500个单元的二进制状态。这种测试方法给出的错误率几乎比上面报告的比率高1%。
表1:MNIST数字识别任务中各种学习算法的错误率。

一种更好的方法是先在联想记忆的下一层修复500个单元的二进制状态,然后依次打开每个标签单元,然后计算得到的510个分量的二进制向量的完全自由能。
第7节展示了当网络运行时,在不受视觉输入限制的情况下,会发生什么。该网络有一个完整的生成模型,因此很容易研究它的思想——我们只是从它的高级表示中生成一个图像。
为了从模型中生成样本,我们在顶级联想存储器中执行交替的吉布斯抽样,直到马尔可夫链收敛到均衡分布。然后,我们使用这个分布的样本作为输入到下面的层,并通过生成的连接通过一个向下传递来生成一个图像。如果我们在吉布斯采样期间将标签单元夹到一个特定的类中,我们可以从模型的类条件分布中看到图像。图8显示了每一个类的图像序列,它们允许在样本之间进行1000次的吉布斯抽样。

图8:每个行显示10个来自生成模型的样本,并带有一个特定的标签。顶级的联想记忆是在样本之间的1000次交替的吉布斯抽样。
我们还可以通过提供一个随机的二进制图像作为输入来初始化前两层的状态。图9显示了关联内存的类条件状态是如何在允许自由运行的情况下演化的,但是标签被夹住了。

图9:每一行显示10个来自生成模型的样本,并带有一个特定的标签。顶级的联想记忆是由一个随机的二值图像(每个像素的概率是0.5)来初始化的。第一列显示了从这个初始的高层状态向下传递的结果。后续的列是由20个迭代的交替的吉布斯抽样在联想记忆中产生的。
我们已经证明,可以一次一层地学习一层深厚、紧密相连的置信网络。为了演示我们快速、贪婪的学习算法的威力,我们使用它来初始化一个更慢的微调算法的权重,该算法学习了一种优秀的数字图像和它们的标签的生成模型。
主要优点,与区别性模型相比:
1,生成模型可以在不需要标签反馈的情况下学习低层次的特性,而且他们可以学习更多的参数,而不需要过度拟合。在甄别学习中,每一个训练用例都只限定了指定标签所需要的信息量。对于生成模型,每个训练用例通过指定输入所需的比特数来约束参数。
2,通过从模型中生成网络,我们很容易看到它所学习到的东西。
3,可以通过生成图像来解释深层隐藏层中的非线性、分布式表示。
4,区分学习方法的高级分类性能只适用于不可能学习好的生成模型的领域。这一系列的领域正在被摩尔定律侵蚀。
[1]Hinton, G. E., Osindero, S. & Teh, Y.-W. A fast learning algorithm for deep belief nets. Neural Comp. 18, 1527–1554 (2006).
作者:hangliu 出处:http://www.cnblogs.com/hangliu/ 欢迎转载或分享,但请务必声明文章出处。
论文笔记(2):A fast learning algorithm for deep belief nets.
标签:可见 向量 ext 数据集 反向 案例 重构 描述 text
原文地址:https://www.cnblogs.com/hangliu/p/9043579.html