标签:方法 .com 重载方法 out change 编写 ota rect 多个
学习目标:
搜索流程详解
1、架构图
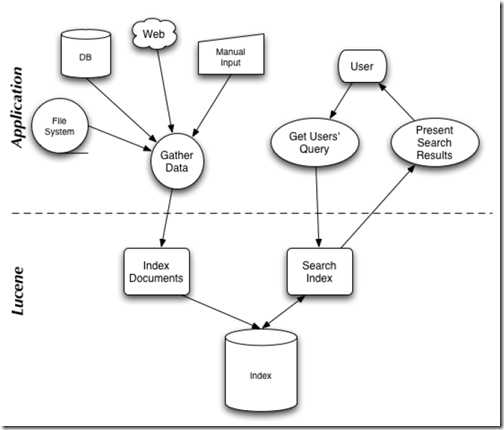
2、Lucene搜索API 图示
3、Lucene搜索代码示例
public class SearchBaseFlow { public static void main(String[] args) throws IOException, ParseException { //使用的分词器 Analyzer analyzer = new IKAnalyzer4Lucene7(true); //索引存储目录 Directory directory = FSDirectory.open(Paths.get("f:/test/indextest")); //索引读取器 IndexReader indexReader = DirectoryReader.open(directory); //索引搜索器 IndexSearcher indexSearcher = new IndexSearcher(indexReader); //要搜索的字段 String filedName = "name"; //查询生成器(解析输入生成Query查询对象) QueryParser parser = new QueryParser(filedName, analyzer); //通过parse解析输入(分词),生成query对象 Query query = parser.parse("Thinkpad"); //搜索,得到TopN的结果(结果中有命中总数,topN的scoreDocs(评分文档(文档id,评分))) TopDocs topDocs = indexSearcher.search(query, 10); //前10条 //获得总命中数 System.out.println(topDocs.totalHits); //遍历topN结果的scoreDocs,取出文档id对应的文档信息 for (ScoreDoc sdoc : topDocs.scoreDocs) { //根据文档id取存储的文档 Document hitDoc = indexSearcher.doc(sdoc.doc); //取文档的字段 System.out.println(hitDoc.get(filedName)); } //使用完毕,关闭、释放资源 indexReader.close(); directory.close(); } }
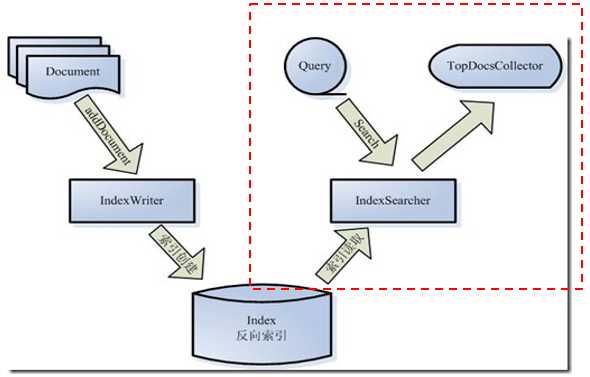
搜索核心API详解
1、核心API图示:
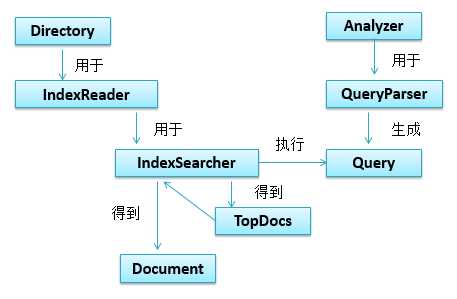
2、IndexReader 索引读取器
Open一个读取器,读取的是该时刻点的索引视图。如果后续索引发生改变,需重新open一个读取器。获得索引读取器的方式:
IndexReader分为两类:

注意:IndexReader是线程安全的。
IndexReader 主要API:
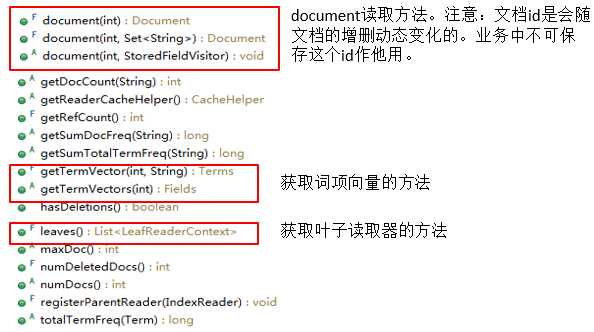
LeafReader 主要API:

3、IndexSearcher 索引搜索器
注意:IndexSearcher是线程安全的。
4、IndexSearcher 索引搜索器API
搜索 API:
获取文档 API:

TopDocs 搜索命中的结果集 (Top-N)

TopFieldDocs 按字段排序的搜索命中结果集

ScoreDoc

Query查询详解
QueryParser详解
标签:方法 .com 重载方法 out change 编写 ota rect 多个
原文地址:https://www.cnblogs.com/morn21/p/9047118.html