标签:clust 运行 com inf 分区表 ignore microsoft 获得 优势
基于表的分区功能为简化分区表的创建和维护过程提供了灵活性和更好的性能。追溯到逻辑分区表和手动分区表的功能.
为了改善大型表以及具有各种访问模式的表的可伸缩性和可管理性。
大型表除了大小以数百 GB 计算,甚至以 TB 计算的指标外,还可以是无法按照预期方式运行的数据表,运行成本或维护成本超出预定要求。例如发生性能问题、阻塞问题、备份。
在test库 添加四个文件组
1 --第一步:创建四个文件组 2 alter database test add filegroup ByIdGroup1 3 alter database test add filegroup ByIdGroup2 4 alter database test add filegroup ByIdGroup3 5 alter database test add filegroup ByIdGroup4
--第二步: 创建四个ndf文件,对应到各文件组中,FILENAME文件存储路径 ALTER DATABASE test ADD FILE( NAME=‘File1‘, FILENAME=‘C:\Program Files\Microsoft SQL Server\MSSQL10.MSSQLSERVER\MSSQL\DATA\testFile1.ndf‘, SIZE=5MB, FILEGROWTH=5MB) TO FILEGROUP ByIdGroup1 ALTER DATABASE test ADD FILE( NAME=‘File2‘, FILENAME=‘E:\testFile2.ndf‘, SIZE=5MB, FILEGROWTH=5MB) TO FILEGROUP ByIdGroup2 ALTER DATABASE test ADD FILE( NAME=‘File3‘, FILENAME=‘E:\testFile3.ndf‘, SIZE=5MB, FILEGROWTH=5MB) TO FILEGROUP ByIdGroup3 ALTER DATABASE test ADD FILE( NAME=‘File4‘, FILENAME=‘E:\testFile4.ndf‘, SIZE=5MB, FILEGROWTH=5MB) TO FILEGROUP ByIdGroup4
执行完成后,查看如下图所示:
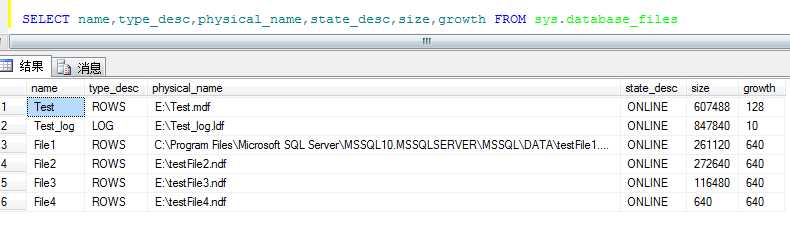
--第三步:创建分区函数(每个分区的边界值) CREATE PARTITION FUNCTION pf_UpByMemberID(int) AS RANGE LEFT FOR VALUES (N‘9707‘,N‘9708‘,N‘9709‘,N‘10600‘)
执行完后如下图所示:
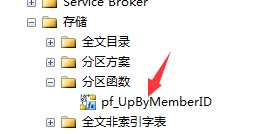
--第四步:创建分区方案
CREATE PARTITION SCHEME ps_UpByMemberID
AS PARTITION pf_UpByMemberID TO ([PRIMARY], [ByIdGroup1],[ByIdGroup2],[ByIdGroup3],[ByIdGroup4])
执行完后如下图所示:
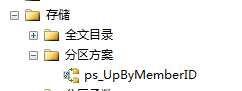
--第五步:创建分区表
右击要分区的表-->存储-->创建分区-->选择分区列(这里UpByMemberID)-->选择分区函数-->分区方案
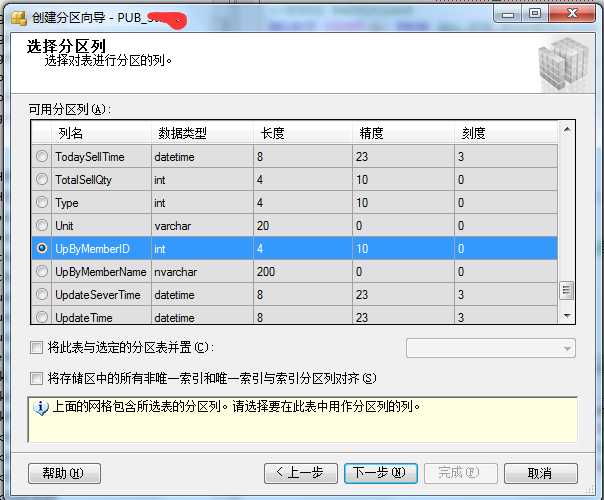
--第六步创建分区索引
/*
create <索引分类> index <索引名称>
on <表名>(列名)
on <分区方案名>(分区依据列名)
*/
CREATE NONCLUSTERED INDEX ixUpByMemberID ON [dbo].PUB_StockTestbak
(
[UpByMemberID]
)WITH (SORT_IN_TEMPDB = OFF, IGNORE_DUP_KEY = OFF, DROP_EXISTING = OFF, ONLINE = OFF)
ON [ps_UpByMemberID]([UpByMemberID])
sql server 分区的优势:
标签:clust 运行 com inf 分区表 ignore microsoft 获得 优势
原文地址:https://www.cnblogs.com/MrHSR/p/9045381.html