标签:输出 没有 com image 使用 并且 计算 提高 定义
随着网络深度增加,会出现一种退化问题,也就是当网络变得越来越深的时候,训练的准确率会趋于平缓,但是训练误差会变大,这明显不是过拟合造成的,因为过拟合是指网络的训练误差会不断变小,但是测试误差会变大。为了解决这种退化现象,ResNet被提出。我们不再用多个堆叠的层直接拟合期望的特征映射,而是显式的用它们拟合一个残差映射。假设期望的特征映射为H(x),那么堆叠的非线性层拟合的是另一个映射,也就是F(x)=H(x)-x。假设最优化残差映射比最优化期望的映射更容易,也就是F(x)=H(x)-x比F(x)=H(x)更容易优化,则极端情况下,期望的映射要拟合的是恒等映射,此时残差网络的任务是拟合F(x)=0,普通网络要拟合的是F(x)=x,明显前者更容易优化。
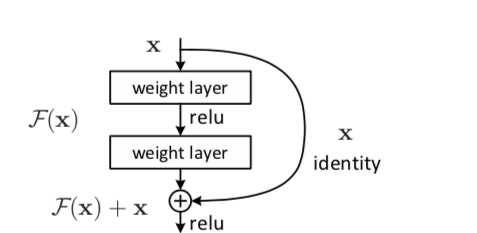
定义一个残差块的形式为y=F(x,Wi)+x,其中x和y分别为残差块的输入和输出向量,F(x,Wi)是要学习的残差映射,在上图中有2层,F=W2σ(W1X),σ是Relu激活函数,在这个表达式中为了方便起见,省略了偏置,这里的shortcut connections是恒等映射,之所以用恒等映射是因为这样没有引进额外的参数和计算复杂度。残差函数F的形式是灵活的,残差块也可以有3层,但是如果残差块只有一层,则y=W1x+x,它只是一个线性层,3层的残差块如下如所示。
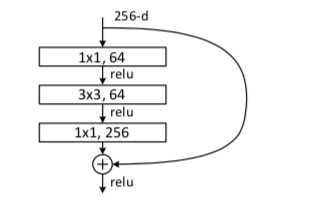
一般的我们称上图这种3层残差块为‘bottleneck block‘,这里1x1的卷积起到了降维的作用,并且引入了更多的非线性变换,明显的增加了残差块的深度,能提高残差网络的表示能力。
残差网络与普通网络不同的地方就是引入了跳跃连接,这可以使上一个残差块的信息没有阻碍的流入到下一个残差块,提高了信息流通,并且也避免了由与网络过深所引起的消失梯度问题和退化问题。
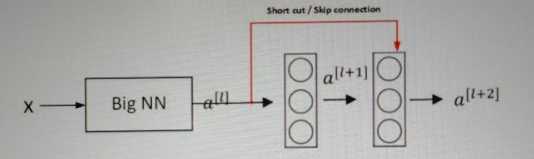
假设有一个大型的神经网络Big NN,它的输入为X,输出激活值为al,则如果我们想要增加这个网络的深度,再给这个网络额外的加两层,最后的输出为al+2,可以把这两层看做一个残差块,并且带有捷径连接,整个网络中使用的激活函数为Relu.
al+2=g(zl+2+al),其中zl+2=Wl+2al+1+bl+1,若Wl+2=0,bl+1=0,则al+2=g(al),当al>=0时,al+2=al。这相当于是建立起了al和al+2的线性关系,相当于是忽略了al之后的两层神经层,实现了隔层线性传递,模型本身也就能够容忍更深层的网络,并且这个额外的残差块也不会影响它的性能.
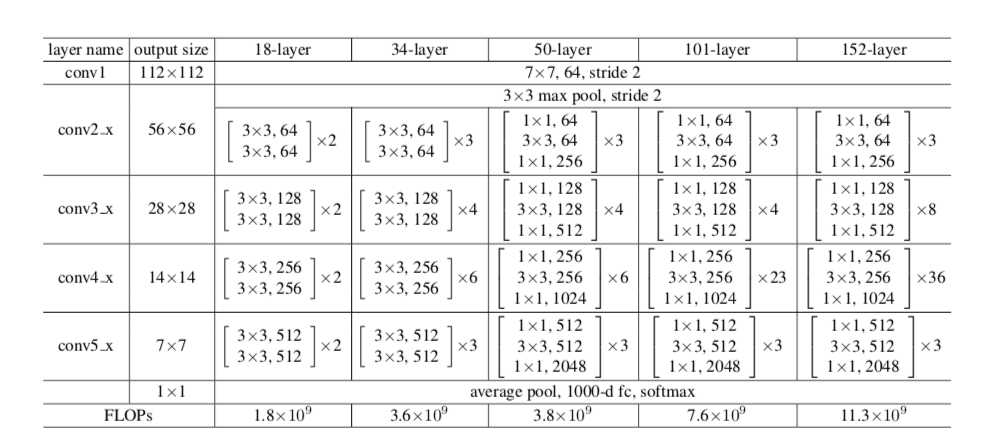
上图一共是5中残差网络的结构,深度分别是18,34,50,101,152.首先都通过一个7x7的卷积层,接着是一个最大池化,之后就是堆叠残差块,其中50,101,152层的残差网络使用的残差块是瓶颈结构,各网络中残差块的个数从左到右依次是8,16,16,33,50。最后在网络的结尾通常连接一个全局平均池化.全局平均池化的好处是没有参数需要最优化防止过拟合,对输入输出的空间变换更具有鲁棒性,加强了特征映射与类别的一致性。
残差网络事实上是由多个浅的网络融合而成,它没有在根本上解决消失的梯度问题,只是避免了消失的梯度问题,因为它是由多个浅的网络融合而成,浅的网络在训练时不会出现消失的梯度问题,所以它能够加速网络的收敛.
标签:输出 没有 com image 使用 并且 计算 提高 定义
原文地址:https://www.cnblogs.com/czy4869/p/9052895.html