标签:field jar fbv length tar char soc 表操作 $.ajax
django:大而全的全的框架,重武器;内置很多组件:ORM、admin、Form、ModelForm、中间件、信号、缓存、csrf等
flask: 微型框架、可扩展强,如果开发简单程序使用flask比较快速,
如果实现负责功能就需要引入一些组件:flask-session/flask-SQLAlchemy/wtforms/flask-migrate/flask-script/blinker
这两个框架都是基于wsgi协议实现的,默认使用的wsgi模块不一样。
还有一个显著的特点,他们处理请求的方式不同:
django: 通过将请求封装成Request对象,再通过参数进行传递。
flask:通过上下文管理实现。
延伸:
- django组件
- flask组件,用途
- wsgi
- 上下文管理
wsgi 》》点我
新知识
web服务网关接口,一套协议。 实现了wsgi协议的模块本质上就是编写了socket服务端,用来监听用户请求,如果有请求到来,则将请求进行一次封装, 然后将【请求】交给 web框架来进行下一步处理。 目前接触: wsgiref (dajngo) werkzurg (flask) uwsgi from wsgiref.simple_server import make_server def run_server(environ, start_response): """ environ: 封装了请求相关的数据 start_response:用于设置响应头相关数据 """ start_response(‘200 OK‘, [(‘Content-Type‘, ‘text/html‘)]) return [bytes(‘<h1>Hello, web!</h1>‘, encoding=‘utf-8‘), ] if __name__ == ‘__main__‘: httpd = make_server(‘‘, 8000, run_server) httpd.serve_forever()
Django源码:
class WSGIHandler(base.BaseHandler): request_class = WSGIRequest def __init__(self, *args, **kwargs): super(WSGIHandler, self).__init__(*args, **kwargs) self.load_middleware() def __call__(self, environ, start_response): # 请求刚进来之后 # set_script_prefix(get_script_name(environ)) signals.request_started.send(sender=self.__class__, environ=environ) request = self.request_class(environ) response = self.get_response(request) response._handler_class = self.__class__ status = ‘%d %s‘ % (response.status_code, response.reason_phrase) response_headers = [(str(k), str(v)) for k, v in response.items()] for c in response.cookies.values(): response_headers.append((str(‘Set-Cookie‘), str(c.output(header=‘‘)))) start_response(force_str(status), response_headers) if getattr(response, ‘file_to_stream‘, None) is not None and environ.get(‘wsgi.file_wrapper‘): response = environ[‘wsgi.file_wrapper‘](response.file_to_stream) return response
a. wsgi, 创建socket服务端,用于接收用户请求并对请求进行初次封装。
b. 中间件,对所有请求到来之前,响应之前定制一些操作。
c. 路由匹配,在url和视图函数对应关系中,根据当前请求url找到相应的函数。
d. 执行视图函数,业务处理【通过ORM去数据库中获取数据,再去拿到模板,然后将数据和模板进行渲染】
e. 再经过所有中间件
f. 通过wsgi将响应返回给用户。
图
所有的请求做统一操作时,用中间件
中间件点我
所有方法: - process_request - process_view - process_template_response , 当视图函数的返回值对象中有render方法时,该方法才会被调用。 - process_response - process_excaption
- 登录验证,为什么:如果不适用就需要为每个函数添加装饰器,太繁琐。 - 权限处理,为什么:用户登录后,将权限放到session中,然后再每次请求时需要判断当前用户是否有权访问当前url,这检查的东西就可以放到中间件中进行统一处理。 - 还有一些内置: - csrf,为什么 - session,为什么 - 全站缓存 ,为什么 - 另外,还有一个就是处理:跨域 (前后端分离时,本地测试开发时使用的。)
目标:防止用户直接向服务端发起POST请求。
方案:先发送GET请求时,将token保存到(csrftoken保存位置):cookie、Form表单中(保存位置隐藏的input标签),以后再发送请求时只要携带过来即可。
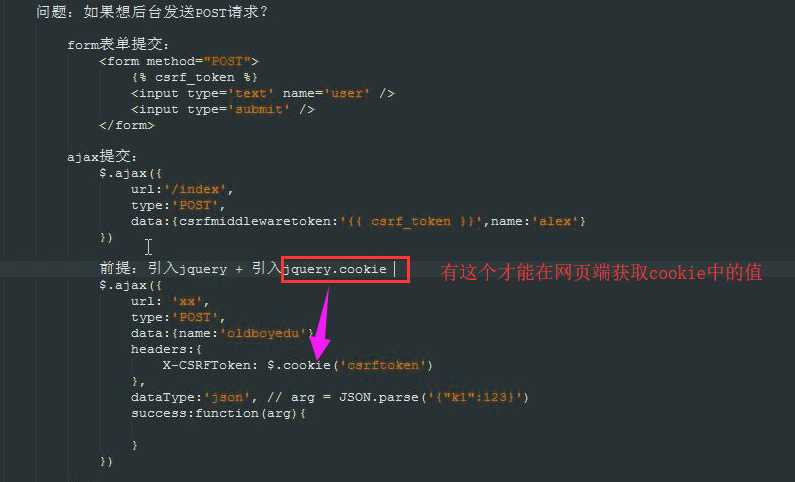
问题:如何向后台发送POST请求?
新知识
form表单提交: <form method="POST"> {% csrf_token %} <input type=‘text‘ name=‘user‘ /> <input type=‘submit‘ /> </form> ajax提交: $.ajax({ url:‘/index‘, type:‘POST‘, data:{csrfmiddlewaretoken:‘{{ csrf_token }}‘,name:‘alex‘} }) 前提:引入jquery + 引入jquery.cookie (此模块可以完成从cookie中取出csrftoken) $.ajax({ url: ‘xx‘, type:‘POST‘, data:{name:‘oldboyedu‘}, headers:{ X-CSRFToken: $.cookie(‘csrftoken‘) }, #在请求头中加上这个信息 注意名字必须是 X-CSRFToken: dataType:‘json‘, // arg = JSON.parse(‘{"k1":123}‘) success:function(arg){ } })
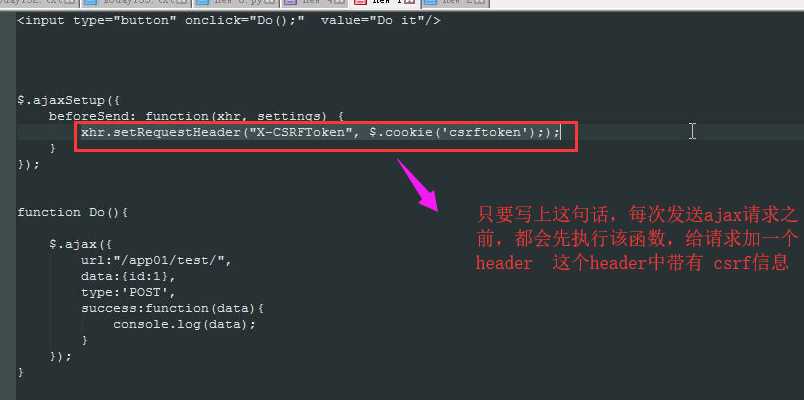
<body> <input type="button" onclick="Do1();" value="Do it"/> <input type="button" onclick="Do2();" value="Do it"/> <input type="button" onclick="Do3();" value="Do it"/> <script src="/static/jquery-3.3.1.min.js"></script> <script src="/static/jquery.cookie.js"></script> //导入jquery.cookie <script> $.ajaxSetup({ //在以后每一个发送ajax请求之前,每次发送之前 都会执行该函数
beforeSend: function(xhr, settings) { xhr.setRequestHeader("X-CSRFToken", $.cookie(‘csrftoken‘)); } }); function Do1(){ $.ajax({ url:"/index/", data:{id:1}, type:‘POST‘, success:function(data){ console.log(data); } }); } function Do2(){ $.ajax({ url:"/index/", data:{id:1}, type:‘POST‘, success:function(data){ console.log(data); } }); } function Do3(){ $.ajax({ url:"/index/", data:{id:1}, type:‘POST‘, success:function(data){ console.log(data); } }); } </script> </body>
FBV: def index(request): pass CBV: class IndexView(View): # 如果是crsf相关,必须放在此处 def dispach(self,request): # 通过反射执行post/get @method_decoretor(装饰器函数) def get(self,request): pass def post(self,request): pass 路由:IndexView.as_view()
FBV和CBV的区别?
- 没什么区别,因为他们的本质都是函数。CBV的.as_view()返回的view函数,view函数中调用类的dispatch方法,在dispatch方法中通过反射执行get/post/delete/put等方法。
- CBV比较简洁,GET/POST等业务功能分别放在不同get/post函数中。FBV自己做判断进行区分。
在cbv中加装饰器:
1.装饰器
from django.views import View from django.utils.decorators import method_decorator def auth(func): def inner(*args,**kwargs): return func(*args,**kwargs) return inner class UserView(View): @method_decorator(auth) def get(self,request,*args,**kwargs):
2.处理csrf的问题
from django.views.decorators.csrf import csrf_exempt from django.utils.decorators import method_decorator # 方式1 # @method_decorator(csrf_exempt,name="dispatch") class UserView(View): #方式二 #也可以自定义以dispatch()方法 @method_decorator(csrf_exempt) #加上这句就可以不验证post请求的csrf内容 def dispatch(self, request, *args, **kwargs): #写上一个print 方法 print(‘Hollow‘) #运行的内容继承dispatch 接收返回值 res=super(UserView, self).dispatch(request, *args, **kwargs) #将返回值返回 return res #定义两个类,get post这两个 def get(self,request): print(‘get11111‘) return HttpResponse(‘getOK‘) def post(self,request): return HttpResponse(‘postOK‘)
a. 增删改查
b. 常用
order_by
group_by
limit
练表/跨表
c. 靠近原生SQL (如何在orm中执行原生sql)
- extra def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={‘new_id‘: "select col from sometable where othercol > %s"}, select_params=(1,)) Entry.objects.extra(where=[‘headline=%s‘], params=[‘Lennon‘]) Entry.objects.extra(where=["foo=‘a‘ OR bar = ‘a‘", "baz = ‘a‘"]) Entry.objects.extra(select={‘new_id‘: "select id from tb where id > %s"}, select_params=(1,), order_by=[‘-nid‘]) - raw def raw(self, raw_query, params=None, translations=None, using=None): # 执行原生SQL models.UserInfo.objects.raw(‘select * from userinfo‘) # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 models.UserInfo.objects.raw(‘select id as nid,name as title from 其他表‘) # 为原生SQL设置参数 models.UserInfo.objects.raw(‘select id as nid from userinfo where nid>%s‘, params=[12,]) # 将获取的到列名转换为指定列名 name_map = {‘first‘: ‘first_name‘, ‘last‘: ‘last_name‘, ‘bd‘: ‘birth_date‘, ‘pk‘: ‘id‘} Person.objects.raw(‘SELECT * FROM some_other_table‘, translations=name_map) # 指定数据库 models.UserInfo.objects.raw(‘select * from userinfo‘, using="default") - 原生 from django.db import connection, connections cursor = connection.cursor() # cursor = connections[‘default‘].cursor() cursor.execute("""SELECT * from auth_user where id = %s""", [1]) row = cursor.fetchone() # fetchall()/fetchmany(..)
d. 高级一点
- F
- Q
- select_related
- prefech_related
e. 其他:

################################################################## # PUBLIC METHODS THAT ALTER ATTRIBUTES AND RETURN A NEW QUERYSET # ################################################################## def all(self) # 获取所有的数据对象 def filter(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def exclude(self, *args, **kwargs) # 条件查询 # 条件可以是:参数,字典,Q def select_related(self, *fields) 性能相关:表之间进行join连表操作,一次性获取关联的数据。 model.tb.objects.all().select_related() model.tb.objects.all().select_related(‘外键字段‘) model.tb.objects.all().select_related(‘外键字段__外键字段‘) def prefetch_related(self, *lookups) 性能相关:多表连表操作时速度会慢,使用其执行多次SQL查询在Python代码中实现连表操作。 # 获取所有用户表 # 获取用户类型表where id in (用户表中的查到的所有用户ID) models.UserInfo.objects.prefetch_related(‘外键字段‘) from django.db.models import Count, Case, When, IntegerField Article.objects.annotate( numviews=Count(Case( When(readership__what_time__lt=treshold, then=1), output_field=CharField(), )) ) students = Student.objects.all().annotate(num_excused_absences=models.Sum( models.Case( models.When(absence__type=‘Excused‘, then=1), default=0, output_field=models.IntegerField() ))) def annotate(self, *args, **kwargs) # 用于实现聚合group by查询 from django.db.models import Count, Avg, Max, Min, Sum v = models.UserInfo.objects.values(‘u_id‘).annotate(uid=Count(‘u_id‘)) # SELECT u_id, COUNT(ui) AS `uid` FROM UserInfo GROUP BY u_id v = models.UserInfo.objects.values(‘u_id‘).annotate(uid=Count(‘u_id‘)).filter(uid__gt=1) # SELECT u_id, COUNT(ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 v = models.UserInfo.objects.values(‘u_id‘).annotate(uid=Count(‘u_id‘,distinct=True)).filter(uid__gt=1) # SELECT u_id, COUNT( DISTINCT ui_id) AS `uid` FROM UserInfo GROUP BY u_id having count(u_id) > 1 def distinct(self, *field_names) # 用于distinct去重 models.UserInfo.objects.values(‘nid‘).distinct() # select distinct nid from userinfo 注:只有在PostgreSQL中才能使用distinct进行去重 def order_by(self, *field_names) # 用于排序 models.UserInfo.objects.all().order_by(‘-id‘,‘age‘) def extra(self, select=None, where=None, params=None, tables=None, order_by=None, select_params=None) # 构造额外的查询条件或者映射,如:子查询 Entry.objects.extra(select={‘new_id‘: "select col from sometable where othercol > %s"}, select_params=(1,)) Entry.objects.extra(where=[‘headline=%s‘], params=[‘Lennon‘]) Entry.objects.extra(where=["foo=‘a‘ OR bar = ‘a‘", "baz = ‘a‘"]) Entry.objects.extra(select={‘new_id‘: "select id from tb where id > %s"}, select_params=(1,), order_by=[‘-nid‘]) def reverse(self): # 倒序 models.UserInfo.objects.all().order_by(‘-nid‘).reverse() # 注:如果存在order_by,reverse则是倒序,如果多个排序则一一倒序 def defer(self, *fields): models.UserInfo.objects.defer(‘username‘,‘id‘) 或 models.UserInfo.objects.filter(...).defer(‘username‘,‘id‘) #映射中排除某列数据 def only(self, *fields): #仅取某个表中的数据 models.UserInfo.objects.only(‘username‘,‘id‘) 或 models.UserInfo.objects.filter(...).only(‘username‘,‘id‘) def using(self, alias): 指定使用的数据库,参数为别名(setting中的设置) ################################################## # PUBLIC METHODS THAT RETURN A QUERYSET SUBCLASS # ################################################## def raw(self, raw_query, params=None, translations=None, using=None): # 执行原生SQL models.UserInfo.objects.raw(‘select * from userinfo‘) # 如果SQL是其他表时,必须将名字设置为当前UserInfo对象的主键列名 models.UserInfo.objects.raw(‘select id as nid from 其他表‘) # 为原生SQL设置参数 models.UserInfo.objects.raw(‘select id as nid from userinfo where nid>%s‘, params=[12,]) # 将获取的到列名转换为指定列名 name_map = {‘first‘: ‘first_name‘, ‘last‘: ‘last_name‘, ‘bd‘: ‘birth_date‘, ‘pk‘: ‘id‘} Person.objects.raw(‘SELECT * FROM some_other_table‘, translations=name_map) # 指定数据库 models.UserInfo.objects.raw(‘select * from userinfo‘, using="default") ################### 原生SQL ################### from django.db import connection, connections cursor = connection.cursor() # cursor = connections[‘default‘].cursor() cursor.execute("""SELECT * from auth_user where id = %s""", [1]) row = cursor.fetchone() # fetchall()/fetchmany(..) def values(self, *fields): # 获取每行数据为字典格式 def values_list(self, *fields, **kwargs): # 获取每行数据为元祖 def dates(self, field_name, kind, order=‘ASC‘): # 根据时间进行某一部分进行去重查找并截取指定内容 # kind只能是:"year"(年), "month"(年-月), "day"(年-月-日) # order只能是:"ASC" "DESC" # 并获取转换后的时间 - year : 年-01-01 - month: 年-月-01 - day : 年-月-日 models.DatePlus.objects.dates(‘ctime‘,‘day‘,‘DESC‘) def datetimes(self, field_name, kind, order=‘ASC‘, tzinfo=None): # 根据时间进行某一部分进行去重查找并截取指定内容,将时间转换为指定时区时间 # kind只能是 "year", "month", "day", "hour", "minute", "second" # order只能是:"ASC" "DESC" # tzinfo时区对象 models.DDD.objects.datetimes(‘ctime‘,‘hour‘,tzinfo=pytz.UTC) models.DDD.objects.datetimes(‘ctime‘,‘hour‘,tzinfo=pytz.timezone(‘Asia/Shanghai‘)) """ pip3 install pytz import pytz pytz.all_timezones pytz.timezone(‘Asia/Shanghai’) """ def none(self): # 空QuerySet对象 #################################### # METHODS THAT DO DATABASE QUERIES # #################################### def aggregate(self, *args, **kwargs): # 聚合函数,获取字典类型聚合结果 from django.db.models import Count, Avg, Max, Min, Sum result = models.UserInfo.objects.aggregate(k=Count(‘u_id‘, distinct=True), n=Count(‘nid‘)) ===> {‘k‘: 3, ‘n‘: 4} def count(self): # 获取个数 def get(self, *args, **kwargs): # 获取单个对象 def create(self, **kwargs): # 创建对象 def bulk_create(self, objs, batch_size=None): # 批量插入 # batch_size表示一次插入的个数 objs = [ models.DDD(name=‘r11‘), models.DDD(name=‘r22‘) ] models.DDD.objects.bulk_create(objs, 10) def get_or_create(self, defaults=None, **kwargs): # 如果存在,则获取,否则,创建 # defaults 指定创建时,其他字段的值 obj, created = models.UserInfo.objects.get_or_create(username=‘root1‘, defaults={‘email‘: ‘1111111‘,‘u_id‘: 2, ‘t_id‘: 2}) def update_or_create(self, defaults=None, **kwargs): # 如果存在,则更新,否则,创建 # defaults 指定创建时或更新时的其他字段 obj, created = models.UserInfo.objects.update_or_create(username=‘root1‘, defaults={‘email‘: ‘1111111‘,‘u_id‘: 2, ‘t_id‘: 1}) def first(self): # 获取第一个 def last(self): # 获取最后一个 def in_bulk(self, id_list=None): # 根据主键ID进行查找 id_list = [11,21,31] models.DDD.objects.in_bulk(id_list) def delete(self): # 删除 def update(self, **kwargs): # 更新 def exists(self):
- request/bs4 - requests模块 - 参数: - url - headers - cookies - data - json - params - proxy - 返回值: - content - iter_content - text - encoding="utf-8" - cookie.get_dict() - bs4 - 解析:html.parser -> lxml - find - find_all - text - attrs - get - 其他: 常见请求头: - user-agent - host - referer - cookie - content-type 套路: - 先给你cookie,然后再给你授权。 - 凭证 轮询+长轮询 - scrapy - 高性能相关,单线程并发发送Http请求 - twisted - gevent - asyncio 本质:基于IO多路复用+非阻塞的socket客户端实现 问题:异步非阻塞? 问题:什么是协程? - scrapy框架 - scrapy执行流程(包含所有组件) - 记录爬虫爬取数据深度(层级),request.meta[‘depth‘] - 传递cookie - 手动 - 自动:meta={‘cookiejar‘:True} - 起始URL - 持久化:pipelines/items - 去重 - 调度器 - 中间件 - 下载中间件 - agent - proxy - 爬虫中间件 - depth - 扩展+信号 - 自定义命令 - scrapy-redis组件,本质:去重、调度器任务、pipeline、起始URL放到redis中。 - 去重,使用的redis的集合。 - 调度器, - redis列表 - 先进先出队列 - 后进先出栈 - redis有序集合 - 优先级队列 PS:深度和广度优先 - pipelines - redis列表 - 起始URL - redis列表 - redis集合 补充: 自定义encoder实现序列化时间等特殊类型: json.dumps(xx,cls=MyEncoder) - scrapy

登录验证
权限处理 (session中封装了用户的权限信息,根据取出的权限判断用户能看到什么,不能看到什么)
CSRF
session
cors跨域 : 解决方法
方法三
- 对用户请求的数据进行校验
- 生成HTML标签

方法一:重写构造方法
from django.shortcuts import render,HttpResponse from app01 import models def index(request): # return HttpResponse("...") return render(request,‘index.html‘,{‘x‘:123}) from django.forms import Form from django.forms import fields class UserForm(Form): name = fields.CharField(label=‘用户名‘,max_length=32) email = fields.EmailField(label=‘邮箱‘) ut_id = fields.ChoiceField( # choices=[(1,‘二笔用户‘),(2,‘闷骚‘)] choices=[] ) def __init__(self,*args,**kwargs): super(UserForm,self).__init__(*args,**kwargs) self.fields[‘ut_id‘].choices = models.UserType.objects.all().values_list(‘id‘,‘title‘) def user(request): if request.method == "GET": form = UserForm() return render(request,‘user.html‘,{‘form‘:form})
方法二: 使用ModelChoiceField 并且给数据库类中添加__str__类
from django.forms import Form from django.forms import fields from django.forms.models import ModelChoiceField #用这个类来给页面渲染出标签 class UserForm(Form): name = fields.CharField(label=‘用户名‘,max_length=32) email = fields.EmailField(label=‘邮箱‘) #这里渲染出从数据库中查出的数据 要这要写 ut_id = ModelChoiceField(queryset=models.UserType.objects.all())
数据库中要有此字段
class UserType(models.Model): title = models.CharField(max_length=32) def __str__(self): #这个也要写上 return self.title
orm中的方法(笔记中有新内容,复习下方法)
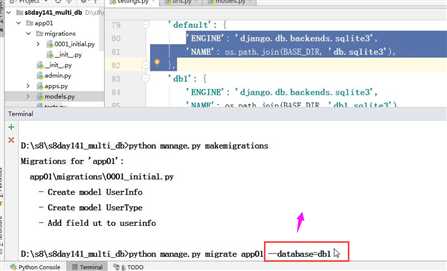
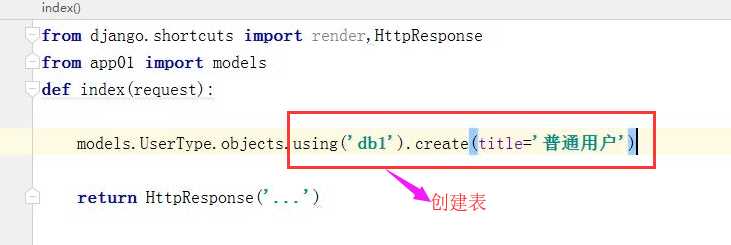
将数据保存入指定的数据库中去 使用magrate来制定(传统方式)
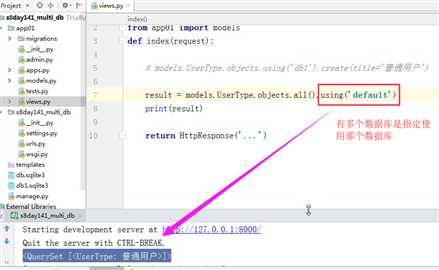
读写分离方法二
setting中的配置
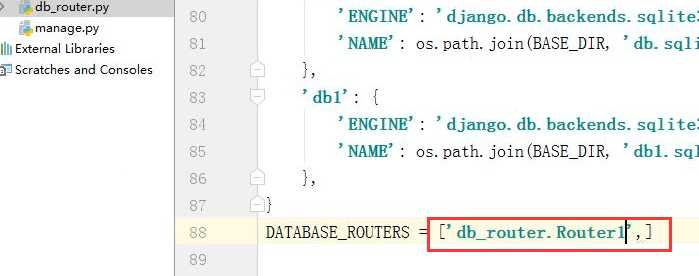
代码:
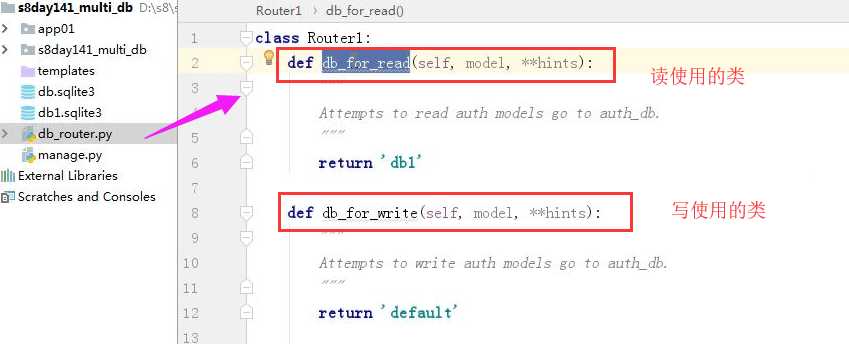
db_router.py中的代码, 此类中规定读和写用的数据库
class Router1: def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ return ‘db1‘ def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ return ‘default‘
settings.py中关于数据库的配置
DATABASES = { ‘default‘: { ‘ENGINE‘: ‘django.db.backends.sqlite3‘, ‘NAME‘: os.path.join(BASE_DIR, ‘db.sqlite3‘), }, ‘db1‘: { ‘ENGINE‘: ‘django.db.backends.sqlite3‘, ‘NAME‘: os.path.join(BASE_DIR, ‘db1.sqlite3‘), }, } DATABASE_ROUTERS = [‘db_router.Router1‘,] 使用: models.UserType.objects.create(title=‘VVIP‘) result = models.UserType.objects.all() print(result)
方法二升级版:粒度更细的方法(粒度到每一张表的读写的配置)

(如果有多个app想让不同的app数据放到不同的数据库)
代码
# 第一步: python manage.py makemigraions # 第二步: app01中的表在default数据库创建 python manage.py migrate app01 --database=default # 第三步: app02中的表在db1数据库创建 python manage.py migrate app02 --database=db1
手动操作
(已知usertype是app01中的表)
(已知Users是app02中的表)
m1.UserType.objects.using(‘default‘).create(title=‘VVIP‘) m2.Users.objects.using(‘db1‘).create(name=‘VVIP‘,email=‘xxx‘)
自动操作
class Router1: def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ if model._meta.app_label == ‘app01‘: return ‘default‘ else: return ‘db1‘ def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ if model._meta.app_label == ‘app01‘: return ‘default‘ else: return ‘db1‘
settings中的配置
DATABASE_ROUTERS = [‘db_router.Router1‘,]
class Router1: def allow_migrate(self, db, app_label, model_name=None, **hints): """ All non-auth models end up in this pool. """ if db==‘db1‘ and app_label == ‘app02‘: return True elif db == ‘default‘ and app_label == ‘app01‘: return True else: return False # 如果返回None,那么表示交给后续的router,如果后续没有router,则相当于返回True def db_for_read(self, model, **hints): """ Attempts to read auth models go to auth_db. """ if model._meta.app_label == ‘app01‘: return ‘default‘ else: return ‘db1‘ def db_for_write(self, model, **hints): """ Attempts to write auth models go to auth_db. """ if model._meta.app_label == ‘app01‘: return ‘default‘ else: return ‘db1‘
三: 类中有一个allow_migrate方法来管控是否允许某些app中数据进行迁移到对应的数据库 (笔记代码)
注意:如果返回None表示交给后续的router 如果后续没有router 相当于返回的True(所以一般返回 TURE 或False 不要用None)
a. 什么是websocket?
websocket是给浏览器新建一套协议。协议规定:浏览器和服务端连接之后不断开,以此可以完成:服务端向客户端主动推送消息。
websocket协议额外做的一些前天操作:
- 握手,连接前进行校验
- 发送数据加密
b. websocket本质
- socket
- 握手,魔法字符串+加密
- 加密,payload_len=127/126/<=125 -> mask key
标签:field jar fbv length tar char soc 表操作 $.ajax
原文地址:https://www.cnblogs.com/wangkun122/p/9039259.html
