标签:文档 聚集 sql png cluster insert 方式 size 缓存
数据库和文件系统最大的区别在于:数据库是支持事务的
InnoDB存储引擎:
MySQL5.5.8之后默认的存储引擎,主要面向OLTP(联机事务处理,面向基本的、日常的事务处理)
支持事务,支持外键、支持行锁(有的情况下也会锁住整个表)、非锁定读(默认读取操作不会产生锁)
通过使用MVCC来获取高并发性,并且实现sql标准的4种隔离级别,默认为可重复读级别
使用一种被称成next-key locking的策略来避免幻读(phantom)现象
还提供了插入缓存(insert buffer)、二次写(double write)、自适应哈希索引(adaptive hash index)、预读(read ahead)等高性能技术。
表数据采用聚集方式,每张表的存储都按主键的顺序进行存放。
MyISAM存储引擎:
不支持事务、支持全文索引,表锁设计,主要面向一些OLAP(联机分析处理,数据仓库的主要应用)。
它的缓冲池只缓冲索引文件,而不缓冲数据文件.
该存储引擎表由MYD和MYI组成,MYD用来存放数据文件,MYI用来存放索引文件.
NDB:
是一个集群存储引擎,其特点是数据全部放在内存中。
因此主键查找速度极快,并通过添加NDB数据库存储节点可以线性提高数据库性能,是高可用,高性能的集群系统。
Memory:
将表中的数据存放在内存中,如果数据库重启或发生崩溃,表中的数据都将消失。
它非常适合存储临时数据的临时表.默认采用哈希索引。
只支持表锁,并发性较差。
Innodb存储引擎支持以下几种常见的索引:
B+树索引
全文索引
哈希索引
自适应哈希索引特性:InnoDB存储引擎会根据表的使用情况自动为表生成哈希索引,不能人为干预是否在表中生成哈希索引。
B+树索引并不能找到一个给定键值的具体行。B+树索引能找到的只是被查找数据行所在的页。然后数据库通过把页读入到内存,再在内存中进行查找,最后得到要查找的数据。
为磁盘或其他存取辅助设备设计的一种平衡查找树。
所有记录点按大小顺序存放在同一层的叶子节点上。
各叶子节点由指针进行连接。
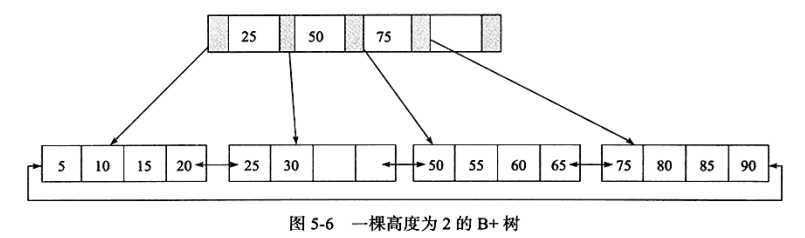
B+索引在数据库中有一个特点是高扇出性
B+树的高度一般在2~4层,这也就是说查找某一键值的行记录时最多只需要2到4次IO。
扇入:指直接调用该模块的上级模块的个数。
扇出:是指该模块直接调用的下级模块的个数。
B+树索引可以分为聚集索引(clustered index)和辅助索引(secondary index),但是不管是聚集还是辅助索引,其内部都是B+树的,即高度平衡的,叶子节点存放着所有的数据。
聚集索引和辅助索引不同的是,叶子节点存放的是否是一整行的信息。
聚集索引:
聚集索引就是按照每张表的主键构造一棵B+树。
叶子节点中存放的是整张表的行记录数据,叶子节点也成称为数据页。
索引组织表中数据也是索引的一部分。同B+树数据结构一样,每个数据页通过一个双向链表来进行链接。
聚集索引能够特别快的访问针对范围值的查询。
很多文档写着:聚集索引按照顺序,物理地存储数据。
但是这本书上写的是:聚集索引的存储并不是物理上连续的,而是逻辑上连续的。(我也不知道哪个是对的)
这其中的两点:一是前面说过的页通过双向链表链接,页是按照主键的顺序排序;
另一点是每个页中的记录也是通过双向链表进行维护的,物理存储上可以同样不按照主键存储。
聚集索引的另外一个好处是,它对于主键的排序查找和范围查找速度非常快。
辅助索引(非聚集索引):
叶子节点并不包含行记录的全部数据。
叶子节点除了包含键值外,每个叶子节点中的索引行中还包含了一个书签(bookmark)。
该书签用来告诉innodb存储引擎哪里可以找到与索引相对于的行数据。
辅助索引的存在并不影响数据在聚集索引中的组织,因此每张表上可以有多个辅助索引。
当通过辅助索引来寻找数据时,innodb存储引擎会遍历辅助索引并通过页基本的指针获得指向主键索引的主键,然后再通过主键索引来找到一个完整的行记录。
标签:文档 聚集 sql png cluster insert 方式 size 缓存
原文地址:https://www.cnblogs.com/mengchunchen/p/9060825.html