标签:arch 数据结构 支持 ref bubuko 核心 images hive 过程
支持向量就是离分隔超平面最近的那些点。分隔超平面是将数据集分开来的决策边界。
支持向量机将向量映射到一个更高维的空间里,在这个空间里建立有一个最大间隔超平面。在分开数据的超平面的两边建有两个互相平行的超平面。建立方向合适的分隔超平面使两个与之平行的超平面间的距离最大化。其假定为,平行超平面间的距离或差距越大,分类器的总误差越小。
我们希望找到离分隔超平面最近的点,确保他们离分隔面的距离尽可能远,误差尽可能小。
与logistics不同的是支持向量机采用的类别标签是-1和+1,因为-1和+1只相差一个符号,方便数学上的处理。
分隔超平面的形式可以写成,一个点到到分隔超平面的的法线或垂线的长度为成,我们的目标是找出间隔最大化时的w和b,间隔通过来计算,即目标式可写作:
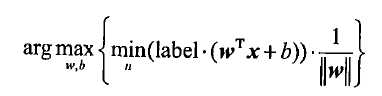
其中||w||为二阶范数,也就是各项目平方和的平方根:
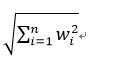
但对乘积优化是特别麻烦的,所以我们可以将超平面写成数据点的形式:
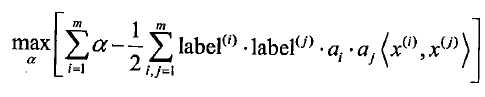
约束条件为:
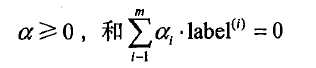
可得w与b:
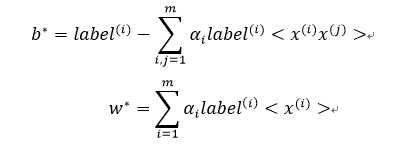
但是大部分情况下数据都不会是100%线性可分的,因此我们加入松弛变量,约束条件变为:
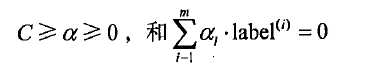
其中求解过程是比较复杂的,如果像我一样接触这类计算机语言不久,可以不用太纠结于算法的计算过程,清楚原理也可以读懂程序。接下来就是完整SMO算法程序实现。
先用testSet.txt中的数据简单了解一下支持向量机算法。
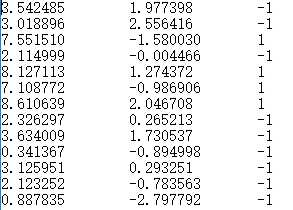
部分testSet.txt中的数据
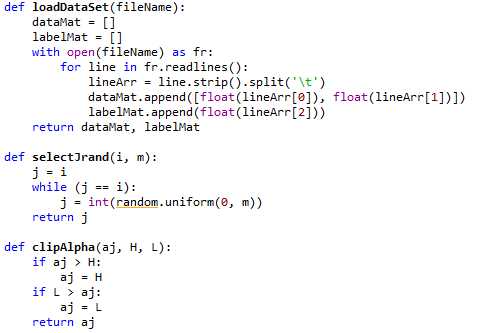
对于testSet.txt数据集,先辅助函数loadDataSet()函数打开文件并对其进行逐行解析,从而得到每行的类标签和整个数据矩阵。selectJrand()中参数i是第一个alpha的下标,m是所有alpha的数目。clipAlpha()用于调整大于H或小于L的alpha值。
然后需要构建一个仅包含init方法的optStructure类来实现其成员变量的填充。calcEK()计算E值并返回。selectJ()用于选择内循环的alpha值。cpdateEK()计算在对alpha值进行优化时会用到的误差值。


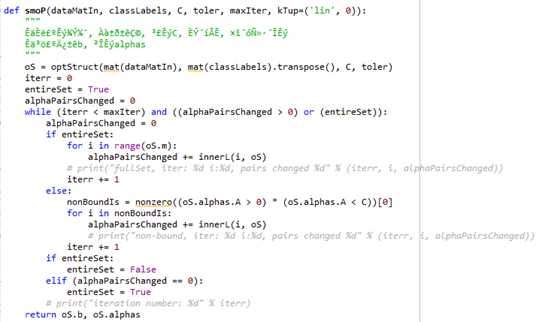
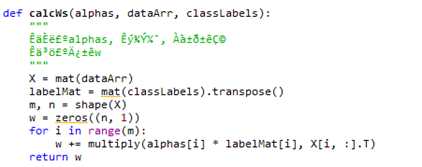
再导入innerL()函数,使用它自己的数据结构在参数os中传递。smoP()函数创建一个数据结构来容纳所有的数据,然后对控制函数退出的变量进行初始化。CalcWs()中的for循环遍历数据集中的所有数据,舍弃支持向量之外的其他数据点。

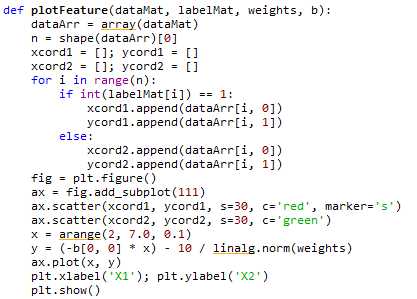
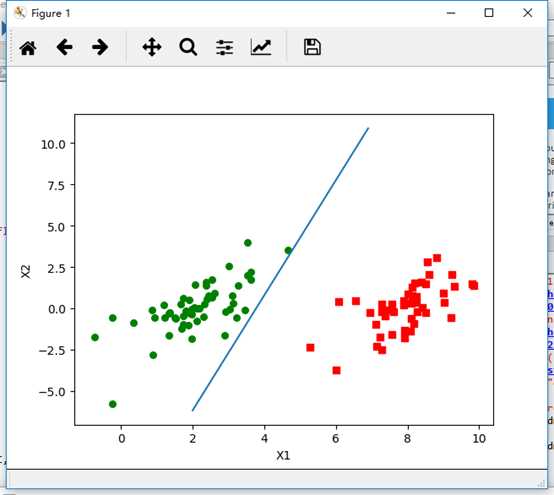
最后,利用matplotlib画出图形。
数据:存放在trainingDigits和testDigits两个文件夹中的手写识别数据。
SMO算法程序与前面相同,接下来用img2vector()函数将32x32的二进制图像转换为1x1024向量及loadImages()函数加载图片。
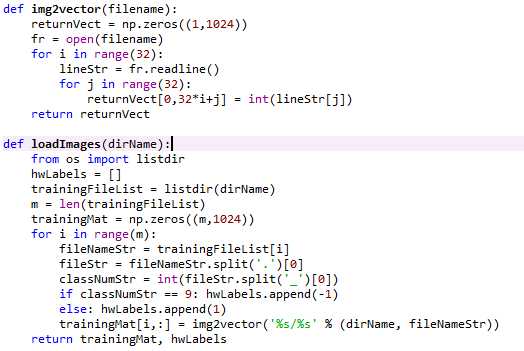
用testDigits()函数测试支持向量个数、训练集错误率及测试集错误率。
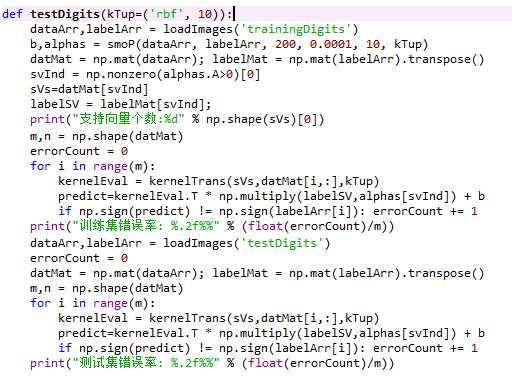
经过4次迭代以后得到:

核函数是SMV的核心算法,对于原本线性不可分的样本,可以通过将原始输入空间映射到更高维度的特征空间这一操作使其在新的核空间内变为线性可分。仅需要调整核函数就可以将特征进行低维到高维的变换,在低维上进行计算,实质结果表现在高维上。
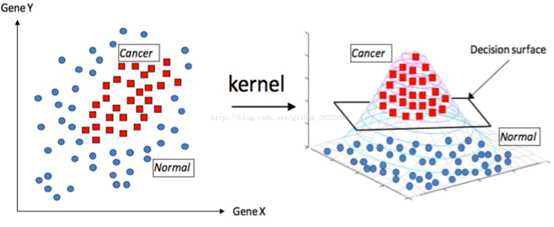
此图来自https://blog.csdn.net/github_38325884/article/details/74418365
比较流行的一个核函数是径向基核函数:
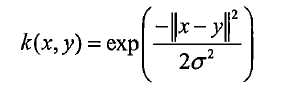
由于本人对核函数还不是很懂,这里使用的数据集比较简单,没有使用核函数,就不再具体介绍了,想深入了解具体算法实现过程可参考http://www.cnblogs.com/jerrylead/archive/2011/03/18/1988406.html
支持向量机具有良好的学习能力,结果有很好的推广性。且完整算法在很大程度上提高了优化的速度。但对参数调节和核函数的选择敏感,若要处理二分类以外的问题需要对原始分离器加以修改。适用于数值型和标称型数据。
标签:arch 数据结构 支持 ref bubuko 核心 images hive 过程
原文地址:https://www.cnblogs.com/yue-guan/p/1072smv.html