标签:消费 针对 方案 启动 休眠 全面 book 自己 失败
为什么写这篇文章?
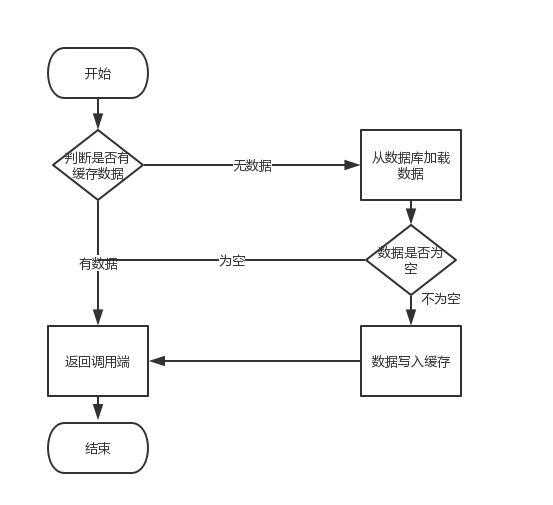
正文
先做一个说明,从理论上来说,给缓存设置过期时间,是保证最终一致性的解决方案。这种方案下,我们可以对存入缓存的数据设置过期时间,所有的写操作以数据库为准,对缓存操作只是尽最大努力即可。也就是说如果数据库写成功,缓存更新失败,那么只要到达过期时间,则后面的读请求自然会从数据库中读取新值然后回填缓存。因此,接下来讨论的思路不依赖于给缓存设置过期时间这个方案。
先更新数据库,再更新缓存
先删除缓存,再更新数据库
先更新数据库,再删除缓存
应该没人问我,为什么没有先更新缓存,再更新数据库这种策略。
先更新数据库,再更新缓存
这套方案,大家是普遍反对的。为什么呢?有如下两点原因。
原因一(线程安全角度)
同时有请求A和请求B进行更新操作,那么会出现
线程A更新了数据库
线程B更新了数据库
线程B更新了缓存
线程A更新了缓存
这就出现请求A更新缓存应该比请求B更新缓存早才对,但是因为网络等原因,B却比A更早更新了缓存。这就导致了脏数据,因此不考虑。
原因二(业务场景角度)
有如下两点:
先删缓存,再更新数据库
该方案会导致不一致的原因是。同时有一个请求A进行更新操作,另一个请求B进行查询操作。那么会出现如下情形:
请求B查询发现缓存不存在

转化为中文描述就是
这么做,可以将1秒内所造成的缓存脏数据,再次删除。
那么,这个1秒怎么确定的,具体该休眠多久呢?
针对上面的情形,读者应该自行评估自己的项目的读数据业务逻辑的耗时。然后写数据的休眠时间则在读数据业务逻辑的耗时基础上,加几百ms即可。这么做的目的,就是确保读请求结束,写请求可以删除读请求造成的缓存脏数据。
如果你用了mysql的读写分离架构怎么办?
ok,在这种情况下,造成数据不一致的原因如下,还是两个请求,一个请求A进行更新操作,另一个请求B进行查询操作。
上述情形,就是数据不一致的原因。还是使用双删延时策略。只是,睡眠时间修改为在主从同步的延时时间基础上,加几百ms。
采用这种同步淘汰策略,吞吐量降低怎么办?
ok,那就将第二次删除作为异步的。自己起一个线程,异步删除。这样,写的请求就不用沉睡一段时间后了,再返回。这么做,加大吞吐量。
第二次删除,如果删除失败怎么办?
这是个非常好的问题,因为第二次删除失败,就会出现如下情形。还是有两个请求,一个请求A进行更新操作,另一个请求B进行查询操作,为了方便,假设是单库:
ok,这也就是说。如果第二次删除缓存失败,会再次出现缓存和数据库不一致的问题。
如何解决呢?
具体解决方案,且看博主对第(3)种更新策略的解析。
先更新数据库,再删缓存
首先,先说一下。老外提出了一个缓存更新套路,名为《Cache-Aside pattern》。其中就指出
另外,知名社交网站facebook也在论文《Scaling Memcache at Facebook》中提出,他们用的也是先更新数据库,再删缓存的策略。
这种情况不存在并发问题么?
不是的。假设这会有两个请求,一个请求A做查询操作,一个请求B做更新操作,那么会有如下情形产生
ok,如果发生上述情况,确实是会发生脏数据。
然而,发生这种情况的概率又有多少呢?
发生上述情况有一个先天性条件,就是步骤(3)的写数据库操作比步骤(2)的读数据库操作耗时更短,才有可能使得步骤(4)先于步骤(5)。可是,大家想想,数据库的读操作的速度远快于写操作的(不然做读写分离干嘛,做读写分离的意义就是因为读操作比较快,耗资源少),因此步骤(3)耗时比步骤(2)更短,这一情形很难出现。
假设,有人非要抬杠,有强迫症,一定要解决怎么办?
如何解决上述并发问题?
首先,给缓存设有效时间是一种方案。其次,采用策略(2)里给出的异步延时删除策略,保证读请求完成以后,再进行删除操作。
还有其他造成不一致的原因么?
有的,这也是缓存更新策略(2)和缓存更新策略(3)都存在的一个问题,如果删缓存失败了怎么办,那不是会有不一致的情况出现么。比如一个写数据请求,然后写入数据库了,删缓存失败了,这会就出现不一致的情况了。这也是缓存更新策略(2)里留下的最后一个疑问。
如何解决?
提供一个保障的重试机制即可,这里给出两套方案。
方案一:
如下图所示
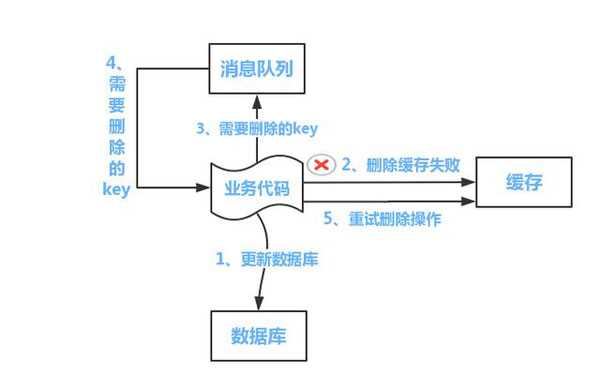
流程如下所示
然而,该方案有一个缺点,对业务线代码造成大量的侵入。于是有了方案二,在方案二中,启动一个订阅程序去订阅数据库的binlog,获得需要操作的数据。在应用程序中,另起一段程序,获得这个订阅程序传来的信息,进行删除缓存操作。
方案二:
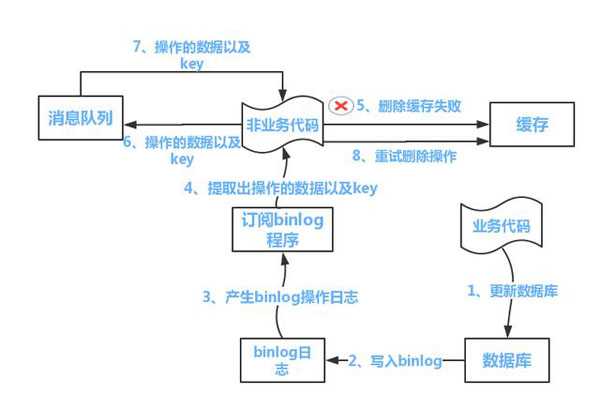
流程如下图所示:
备注说明:
上述的订阅binlog程序在mysql中有现成的中间件叫canal,可以完成订阅binlog日志的功能。至于oracle中,博主目前不知道有没有现成中间件可以使用。另外,重试机制,博主是采用的是消息队列的方式。如果对一致性要求不是很高,直接在程序中另起一个线程,每隔一段时间去重试即可,这些大家可以灵活自由发挥,只是提供一个思路。
总结
本文其实是对目前互联网中已有的一致性方案,进行了一个总结。对于先删缓存,再更新数据库的更新策略,还有方案提出维护一个内存队列的方式,博主看了一下,觉得实现异常复杂,没有必要,因此没有必要在文中给出。最后,希望大家有所收获。
文章转载至 http://database.51cto.com/art/201805/573559.htm
标签:消费 针对 方案 启动 休眠 全面 book 自己 失败
原文地址:https://www.cnblogs.com/rinack/p/9067089.html