标签:文本 鼠标右键 刷新 位置 inf use header -- import
1、网页打开检查器,到达该路径,再刷新网页,点击第一个“Attractions”文件,出现headers(重要)、response、cookies等信息
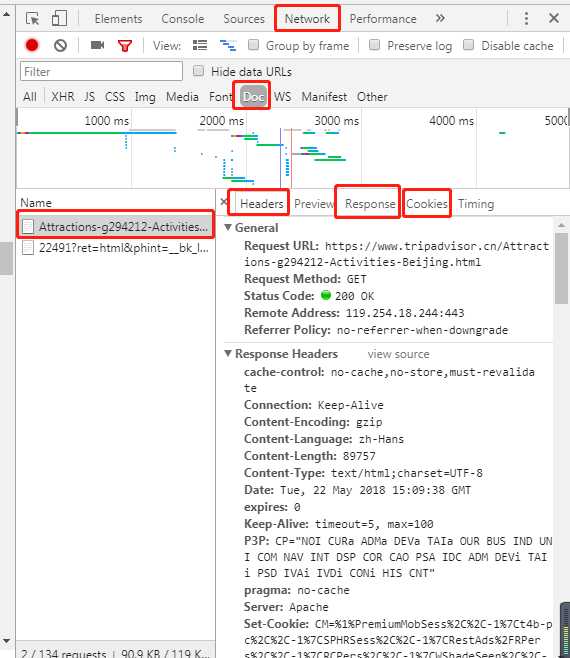
2、定位元素位置方法,找唯一特征:
3、某一字段下有多个信息,需要定位在其父级标签,方便进一步筛选信息
4、进一步筛选信息:
5、连续爬多页
6、反爬--延时
7、反爬--网页切换浏览设备
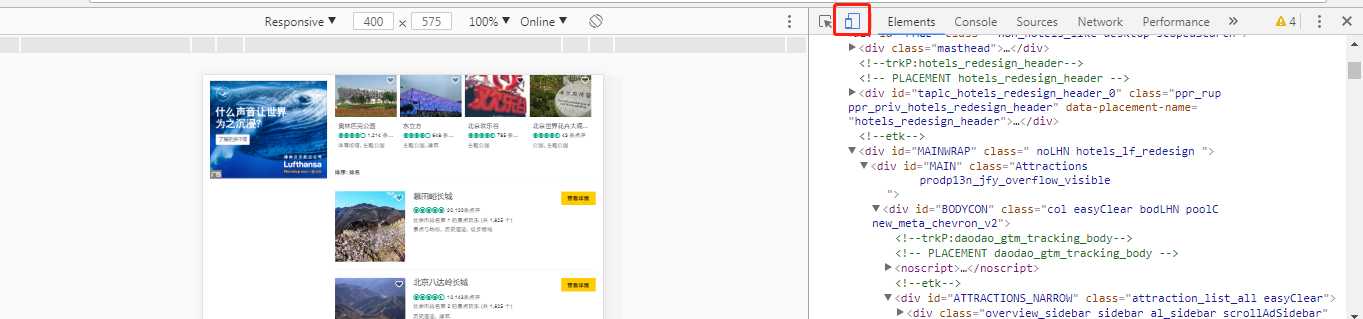
(完)
标签:文本 鼠标右键 刷新 位置 inf use header -- import
原文地址:https://www.cnblogs.com/szhao0823/p/9074912.html