标签:分享图片 forest 控制 com 查看 over r语言 bre 位置
更多内容请关注公众号《大数据风控的一点一滴》
将代码封装在函数PlotKS_N里,Pred_Var是预测结果,可以是评分或概率形式;labels_Var是好坏标签,取值为1或0,1代表坏客户,0代表好客户;descending用于控制数据按违约概率降序排列,如果Pred_Var是评分,则descending=0,如果Pred_Var是概率形式,则descending=1;N表示在将数据按风险降序排列后,等分N份后计算KS值。
PlotKS_N函数返回的结果为一列表,列表中的元素依次为KS最大值、KS取最大值的人数百分位置、KS曲线对象、KS数据框。
代码如下:
#################### PlotKS_N ################################
PlotKS_N<-function(Pred_Var, labels_Var, descending, N){
# Pred_Var is prop: descending=1
# Pred_Var is score: descending=0
library(dplyr)
df<- data.frame(Pred=Pred_Var, labels=labels_Var)
if (descending==1){
df1<-arrange(df, desc(Pred), labels)
}else if (descending==0){
df1<-arrange(df, Pred, labels)
}
df1$good1<-ifelse(df1$labels==0,1,0)
df1$bad1<-ifelse(df1$labels==1,1,0)
df1$cum_good1<-cumsum(df1$good1)
df1$cum_bad1<-cumsum(df1$bad1)
df1$rate_good1<-df1$cum_good1/sum(df1$good1)
df1$rate_bad1<-df1$cum_bad1/sum(df1$bad1)
if (descending==1){
df2<-arrange(df, desc(Pred), desc(labels))
}else if (descending==0){
df2<-arrange(df, Pred, desc(labels))
}
df2$good2<-ifelse(df2$labels==0,1,0)
df2$bad2<-ifelse(df2$labels==1,1,0)
df2$cum_good2<-cumsum(df2$good2)
df2$cum_bad2<-cumsum(df2$bad2)
df2$rate_good2<-df2$cum_good2/sum(df2$good2)
df2$rate_bad2<-df2$cum_bad2/sum(df2$bad2)
rate_good<-(df1$rate_good1+df2$rate_good2)/2
rate_bad<-(df1$rate_bad1+df2$rate_bad2)/2
df_ks<-data.frame(rate_good,rate_bad)
df_ks$KS<-df_ks$rate_bad-df_ks$rate_good
L<- nrow(df_ks)
if (N>L) N<- L
df_ks$tile<- 1:L
qus<- quantile(1:L, probs = seq(0,1, 1/N))[-1]
qus<- ceiling(qus)
df_ks<- df_ks[df_ks$tile%in%qus,]
df_ks$tile<- df_ks$tile/L
df_0<-data.frame(rate_good=0,rate_bad=0,KS=0,tile=0)
df_ks<-rbind(df_0, df_ks)
M_KS<-max(df_ks$KS)
Pop<-df_ks$tile[which(df_ks$KS==M_KS)]
M_good<-df_ks$rate_good[which(df_ks$KS==M_KS)]
M_bad<-df_ks$rate_bad[which(df_ks$KS==M_KS)]
library(ggplot2)
PlotKS<-ggplot(df_ks)+
geom_line(aes(tile,rate_bad),colour="red2",size=1.2)+
geom_line(aes(tile,rate_good),colour="blue3",size=1.2)+
geom_line(aes(tile,KS),colour="forestgreen",size=1.2)+
geom_vline(xintercept=Pop,linetype=2,colour="gray",size=0.6)+
geom_hline(yintercept=M_KS,linetype=2,colour="forestgreen",size=0.6)+
geom_hline(yintercept=M_good,linetype=2,colour="blue3",size=0.6)+
geom_hline(yintercept=M_bad,linetype=2,colour="red2",size=0.6)+
annotate("text", x = 0.5, y = 1.05, label=paste("KS=", round(M_KS, 4), "at Pop=", round(Pop, 4)), size=4, alpha=0.8)+
scale_x_continuous(breaks=seq(0,1,.2))+
scale_y_continuous(breaks=seq(0,1,.2))+
xlab("of Total Population")+
ylab("of Total Bad/Good")+
ggtitle(label="KS - Chart")+
theme_bw()+
theme(
plot.title=element_text(colour="gray24",size=12,face="bold"),
plot.background = element_rect(fill = "gray90"),
axis.title=element_text(size=10),
axis.text=element_text(colour="gray35")
)
result<-list(M_KS=M_KS,Pop=Pop,PlotKS=PlotKS,df_ks=df_ks)
return(result)
}
######################### OVER #######################################
接下来以实际数据为例查看该函数的运行结果。
pred_train是建模得到的预测结果,这里是概率形式:
> pred_train
[1] 0.40418112 0.35814193 0.45220572 0.53482002 0.12923573 ...
labels_train是好坏标签:
> labels_train
[1] 0 0 0 0 0 ...
函数运行的结果存放在train_ks里:
train_ks<-PlotKS_N(pred_train, labels_train, 1, 100)
我们来查看train_ks中的每一元素:
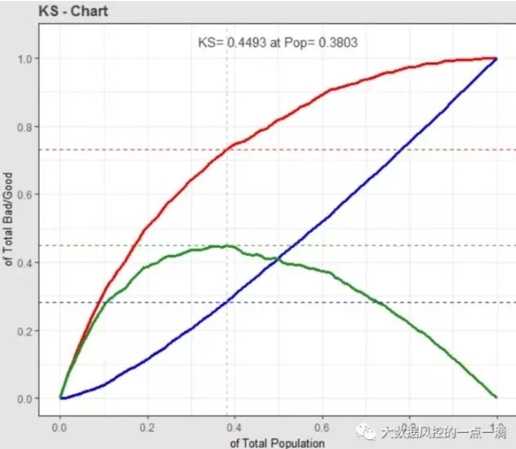
1、KS最大值
> train_ks$M_KS
[1] 0.4492765
2、KS取最大值的人数百分位置
> train_ks$Pop
[1] 0.3803191
3、KS曲线对象
标签:分享图片 forest 控制 com 查看 over r语言 bre 位置
原文地址:https://www.cnblogs.com/bigdatafengkong/p/9076251.html