标签:text 毕业 分类方法 except 判断 例子 shuf eva 影响
一个简单的例子
朴素贝叶斯算法是一个典型的统计学习方法,主要理论基础就是一个贝叶斯公式,贝叶斯公式的基本定义如下:
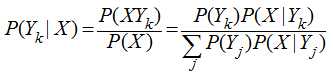
这个公式虽然看上去简单,但它却能总结历史,预知未来。公式的右边是总结历史,公式的左边是预知未来,如果把Y看出类别,X看出特征,P(Yk|X)就是在已知特征X的情况下求Yk类别的概率,而对P(Yk|X)的计算又全部转化到类别Yk的特征分布上来。
举个例子,大学的时候,某男生经常去图书室晚自习,发现他喜欢的那个女生也常去那个自习室,心中窃喜,于是每天买点好吃点在那个自习室蹲点等她来,可是人家女生不一定每天都来,眼看天气渐渐炎热,图书馆又不开空调,如果那个女生没有去自修室,该男生也就不去,每次男生鼓足勇气说:“嘿,你明天还来不?”,“啊,不知道,看情况”。然后该男生每天就把她去自习室与否以及一些其他情况做一下记录,用Y表示该女生是否去自习室,即Y={去,不去},X是跟去自修室有关联的一系列条件,比如当天上了哪门主课,蹲点统计了一段时间后,该男生打算今天不再蹲点,而是先预测一下她会不会去,现在已经知道了今天上了常微分方法这么主课,于是计算P(Y=去|常微分方程)与P(Y=不去|常微分方程),看哪个概率大,如果P(Y=去|常微分方程) >P(Y=不去|常微分方程),那这个男生不管多热都屁颠屁颠去自习室了,否则不就去自习室受罪了。P(Y=去|常微分方程)的计算可以转为计算以前她去的情况下,那天主课是常微分的概率P(常微分方程|Y=去),注意公式右边的分母对每个类别(去/不去)都是一样的,所以计算的时候忽略掉分母,这样虽然得到的概率值已经不再是0~1之间,但是其大小还是能选择类别。
后来他发现还有一些其他条件可以挖,比如当天星期几、当天的天气,以及上一次与她在自修室的气氛,统计了一段时间后,该男子一计算,发现不好算了,因为总结历史的公式:
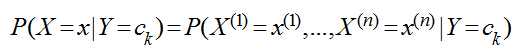
这里n=3,x(1)表示主课,x(2)表示天气,x(3)表示星期几,x(4)表示气氛,Y仍然是{去,不去},现在主课有8门,天气有晴、雨、阴三种、气氛有A+,A,B+,B,C五种,那么总共需要估计的参数有8*3*7*5*2=1680个,每天只能收集到一条数据,那么等凑齐1680条数据大学都毕业了,男生打呼不妙,于是做了一个独立性假设,假设这些影响她去自习室的原因是独立互不相关的,于是
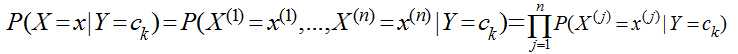
有了这个独立假设后,需要估计的参数就变为,(8+3+7+5)*2 = 46个了,而且每天收集的一条数据,可以提供4个参数,这样该男生就预测越来越准了。
朴素贝叶斯分类器
讲了上面的小故事,我们来朴素贝叶斯分类器的表示形式:
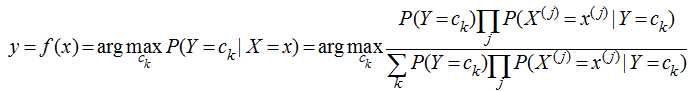
当特征为为x时,计算所有类别的条件概率,选取条件概率最大的类别作为待分类的类别。由于上公式的分母对每个类别都是一样的,因此计算时可以不考虑分母,即
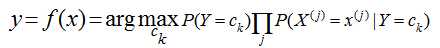
朴素贝叶斯的朴素体现在其对各个条件的独立性假设上,加上独立假设后,大大减少了参数假设空间。
在文本分类上的应用
文本分类的应用很多,比如垃圾邮件和垃圾短信的过滤就是一个2分类问题,新闻分类、文本情感分析等都可以看成是文本分类问题,分类问题由两步组成:训练和预测,要建立一个分类模型,至少需要有一个训练数据集。贝叶斯模型可以很自然地应用到文本分类上:现在有一篇文档d(Document),判断它属于哪个类别ck,只需要计算文档d属于哪一个类别的概率最大:
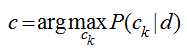
在分类问题中,我们并不是把所有的特征都用上,对一篇文档d,我们只用其中的部分特征词项<t1,t2,...,tnd>(nd表示d中的总词条数目),因为很多词项对分类是没有价值的,比如一些停用词“的,是,在”在每个类别中都会出现,这个词项还会模糊分类的决策面,关于特征词的选取,我的这篇文章有介绍。用特征词项表示文档后,计算文档d的类别转化为:
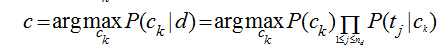
注意P(Ck|d)只是正比于后面那部分公式,完整的计算还有一个分母,但我们前面讨论了,对每个类别而已分母都是一样的,于是在我们只需要计算分子就能够进行分类了。实际的计算过程中,多个概率值P(tj|ck)的连乘很容易下溢出为0,因此转化为对数计算,连乘就变成了累加:
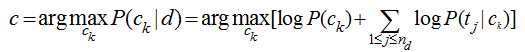
我们只需要从训练数据集中,计算每一个类别的出现概率P(ck)和每一个类别中各个特征词项的概率P(tj|ck),而这些概率值的计算都采用最大似然估计,说到底就是统计每个词在各个类别中出现的次数和各个类别的文档的数目:
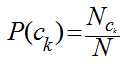
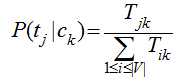
其中,Nck表示训练集中ck类文档的数目,N训练集中文档总数;Tjk表示词项tj在类别ck中出现的次数,V是所有类别的词项集合。这里对词的位置作了独立性假设,即两个词只要它们出现的次数一样,那不管它们在文档的出现位置,它们大概率值P(tj|ck)都是一样,这个位置独立性假设与现实很不相符,比如“放马屁”跟“马放屁”表述的是不同的内容,但实践发现,位置独立性假设得到的模型准确率并不低,因为大多数文本分类都是靠词的差异来区分,而不是词的位置,如果考虑词的位置,那么问题将表达相当复杂,以至于我们无从下手。
然后需要注意的一个问题是ti可能没有出现在ck类别的训练集,却出现在ck类别的测试集合中,这样因为Tik为0,导致连乘概率值都为0,其他特征词出现得再多,该文档也不会被分到ck类别,而且在对数累加的情况下,0值导致计算错误,处理这种问题的方法是采样加1平滑,即认为每个词在各个类别中都至少出现过一次,即
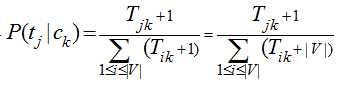
下面这个例子来自于参考文献1,假设有如下的训练集合测试集:

现在要计算docID为5的测试文档是否属于China类别,首先计算个各类的概率,P(c=China)=3/4,P(c!=China)=1/4,然后计算各个类中词项的概率:
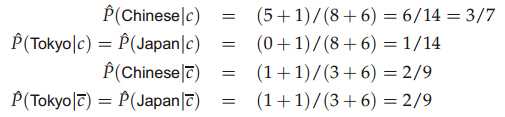
注意分母(8+6)中8表示China类的词项出现的总次数是8,+6表示平滑,6是总词项的个数,然后计算测试文档属于各个类别的概率:
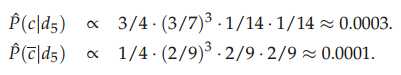
可以看出该测试文档应该属于CHina类别。
文本分类实践
我找了搜狗的搜狐新闻数据的历史简洁版,总共包括汽车、财经、it、健康等9类新闻,一共16289条新闻,搜狗给的数据是每一篇新闻用一个txt文件保存,我预处理了一下,把所有的新闻文档保存在一个文本文件中,每一行是一篇新闻,同时保留新闻的id,id的首字母表示类标,预处理并分词后的示例如下:

我用6289条新闻作为训练集,剩余1万条用于测试,采用互信息进行文本特征的提取,总共提取的特征词是700个左右。
分类的结果如下:
8343 10000 0.8343
总共10000条新闻,分类正确的8343条,正确率0.8343,这里主要是演示贝叶斯的分类过程,只考虑了正确率也没有考虑其他评价指标,也没有进行优化。贝叶斯分类的效率高,训练时,只需要扫描一遍训练集,记录每个词出现的次数,以及各类文档出现的次数,测试时也只需要扫描一次测试集,从运行效率这个角度而言,朴素贝叶斯的效率是最高的,而准确率也能达到一个理想的效果。
我的实现代码如下:
1 #!encoding=utf-8
2 import random
3 import sys
4 import math
5 import collections
6 import sys
7 def shuffle():
8 ‘‘‘将原来的文本打乱顺序,用于得到训练集和测试集‘‘‘
9 datas = [line.strip() for line in sys.stdin]
10 random.shuffle(datas)
11 for line in datas:
12 print line
13
14
15 lables = [‘A‘,‘B‘,‘C‘,‘D‘,‘E‘,‘F‘,‘G‘,‘H‘,‘I‘]
16 def lable2id(lable):
17 for i in xrange(len(lables)):
18 if lable == lables[i]:
19 return i
20 raise Exception(‘Error lable %s‘ % (lable))
21
22 def docdict():
23 return [0]*len(lables)
24
25 def mutalInfo(N,Nij,Ni_,N_j):
26 #print N,Nij,Ni_,N_j
27 return Nij * 1.0 / N * math.log(N * (Nij+1)*1.0/(Ni_*N_j))/ math.log(2)
28
29 def countForMI():
30 ‘‘‘基于统计每个词在每个类别出现的次数,以及每类的文档数‘‘‘
31 docCount = [0] * len(lables)#每个类的词数目
32 wordCount = collections.defaultdict(docdict)
33 for line in sys.stdin:
34 lable,text = line.strip().split(‘ ‘,1)
35 index = lable2id(lable[0])
36 words = text.split(‘ ‘)
37 for word in words:
38 wordCount[word][index] += 1
39 docCount[index] += 1
40
41 miDict = collections.defaultdict(docdict)#互信息值
42 N = sum(docCount)
43 for k,vs in wordCount.items():
44 for i in xrange(len(vs)):
45 N11 = vs[i]
46 N10 = sum(vs) - N11
47 N01 = docCount[i] - N11
48 N00 = N - N11 - N10 - N01
49 mi = mutalInfo(N,N11,N10+N11,N01+N11) + mutalInfo(N,N10,N10+N11,N00+N10)+ mutalInfo(N,N01,N01+N11,N01+N00)+ mutalInfo(N,N00,N00+N10,N00+N01)
50 miDict[k][i] = mi
51 fWords = set()
52 for i in xrange(len(docCount)):
53 keyf = lambda x:x[1][i]
54 sortedDict = sorted(miDict.items(),key=keyf,reverse=True)
55 for j in xrange(100):
56 fWords.add(sortedDict[j][0])
57 print docCount#打印各个类的文档数目
58 for fword in fWords:
59 print fword
60
61
62 def loadFeatureWord():
63 ‘‘‘导入特征词‘‘‘
64 f = open(‘feature.txt‘)
65 docCounts = eval(f.readline())
66 features = set()
67 for line in f:
68 features.add(line.strip())
69 f.close()
70 return docCounts,features
71
72 def trainBayes():
73 ‘‘‘训练贝叶斯模型,实际上计算每个类中特征词的出现次数‘‘‘
74 docCounts,features = loadFeatureWord()
75 wordCount = collections.defaultdict(docdict)
76 tCount = [0]*len(docCounts)#每类文档特征词出现的次数
77 for line in sys.stdin:
78 lable,text = line.strip().split(‘ ‘,1)
79 index = lable2id(lable[0])
80 words = text.split(‘ ‘)
81 for word in words:
82 if word in features:
83 tCount[index] += 1
84 wordCount[word][index] += 1
85 for k,v in wordCount.items():
86 scores = [(v[i]+1) * 1.0 / (tCount[i]+len(wordCount)) for i in xrange(len(v))]#加1平滑
87 print ‘%s\t%s‘ % (k,scores)
88
89 def loadModel():
90 ‘‘‘导入贝叶斯模型‘‘‘
91 f = open(‘model.txt‘)
92 scores = {}
93 for line in f:
94 word,counts = line.strip().rsplit(‘\t‘,1)
95 scores[word] = eval(counts)
96 f.close()
97 return scores
98
99 def predict():
100 ‘‘‘预测文档的类标,标准输入每一行为一个文档‘‘‘
101 docCounts,features = loadFeatureWord()
102 docscores = [math.log(count * 1.0 /sum(docCounts)) for count in docCounts]
103 scores = loadModel()
104 rCount = 0
105 docCount = 0
106 for line in sys.stdin:
107 lable,text = line.strip().split(‘ ‘,1)
108 index = lable2id(lable[0])
109 words = text.split(‘ ‘)
110 preValues = list(docscores)
111 for word in words:
112 if word in features:
113 for i in xrange(len(preValues)):
114 preValues[i]+=math.log(scores[word][i])
115 m = max(preValues)
116 pIndex = preValues.index(m)
117 if pIndex == index:
118 rCount += 1
119 print lable,lables[pIndex],text
120 docCount += 1
121 print rCount,docCount,rCount * 1.0 / docCount
122
123
124 if __name__=="__main__":
125 #shuffle()
126 #countForMI()
127 #trainBayes()
128 predict()
代码里面,计算特征词与训练模型、测试是分开的,需要修改main方法,比如计算特征词:
$cat train.txt | python bayes.py > feature.txt
训练模型:
$cat train.txt | python bayes.py > model.txt
预测模型:
$cat test.txt | python bayes.py > predict.out
总结
本文介绍了朴素贝叶斯分类方法,还以文本分类为例,给出了一个具体应用的例子,朴素贝叶斯的朴素体现在条件变量之间的独立性假设,应用到文本分类上,作了两个假设,一是各个特征词对分类的影响是独立的,另一个是词项在文档中的顺序是无关紧要的。朴素贝叶斯的独立性假设在实际中并不成立,但在分类效上依然不错,加上独立性假设后,对与属于类ck的谋篇文档d,其p(ck|d)往往会估计过高,即本来预期p(ck|d)=0.55,而朴素贝叶斯却计算得到p(ck|d)=0.99,但这并不影响分类结果,这是朴素贝叶斯分类器在文本分类上效果优于预期的原因。
参考链接:http://www.cnblogs.com/fengfenggirl/p/bayes_classify.html
标签:text 毕业 分类方法 except 判断 例子 shuf eva 影响
原文地址:https://www.cnblogs.com/itbuyixiaogong/p/9077514.html