标签:-name pool views pos 完全 stat 查找 storage height
最近配置Hadoop的时候出现了这么一个现象,启动之后,使用jps命令之后是这样的:
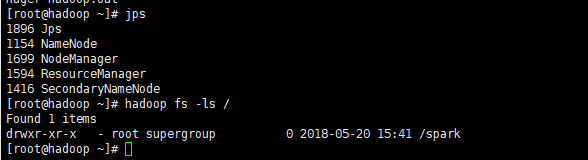
看不到DataNode进程,但是能够正常的工作,是不是很神奇啊?
在一番百度谷歌之后,得出了结论:
我在启动Hadoop之前和启动之后,曾经多次使用如下命令,针对NameNode进行格式化:
hadoop namenode -format这个问题,还不是你直接多次格式化造成的,而是你格式化之后,启动了Hadoop,然后将Hadoop关闭,重新格式化,再启动Hadoop造成的,这个时候你就发现,DataNode线程在jps命令中消失了,还能正常使用,就如我开头的那张图一样。造成这个问题的根源,是NameNode和DataNode的版本号不一致所致。这个问题不仅仅会出现在伪分布式,完全分布式中也会出现。这里以伪分布式进行展示。
如下是正常的两个文件的信息。
NameNode VERSION文件信息:
namespaceID=51628800
clusterID=CID-97bb16dc-c439-427c-9841-5e6e4667cb65
cTime=0
storageType=NAME_NODE
blockpoolID=BP-1918730739-172.17.241.131-1526803461127
layoutVersion=-63DataNode VERSION文件信息:
storageID=DS-4281731b-7a44-4c86-8844-e1927a4fc966
clusterID=CID-97bb16dc-c439-427c-9841-5e6e4667cb65
cTime=0
datanodeUuid=197c3d68-454b-4287-a5e5-90c01ed9be53
storageType=DATA_NODE
layoutVersion=-56所谓版本号不一致,就是说的clusterID的值,上面的信息展示的是一致的,也表明NameNode和DataNode是一组的。
那么这两个文件存放在哪里呢?如下是你在Hadoop配置文件core-site.xml中的一项,就在此项指定的目录之下。
<property>
<!--用来指定hadoop运行时产生文件的存放目录-->
<name>hadoop.tmp.dir</name>
<value>/home/hadoop-2.7.1/tmp</value>
</property>那我就以我这个配置的路径来进行查找,首先到tmp目录下:
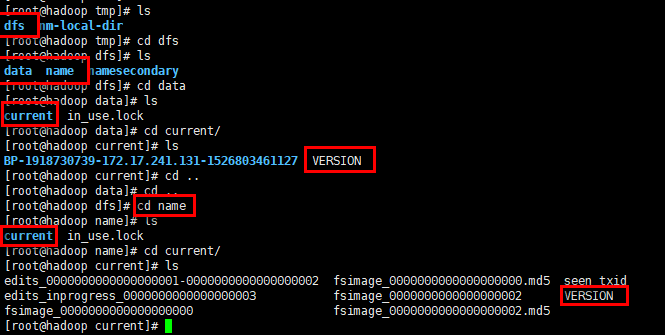
如上图是完整的查找路径。
下面进行此问题的分析:
当第一次格式化,启动Hadoop的时候,没有任何问题,任何环节都是新产生的,所以哪怕你在启动Hadoop之前进行多次的NameNode格式化都可以,因为在Hadoop启动之前,DataNode的版本还没有生成,只有Hadoop启动之后DataNode的版本等响应信息才会在指定的目录下生成,这个时候就产生了NameNode和DataNode的一对一的关系。
当你关掉Hadoop之后进行二次NameNode格式化的时候,NameNode的版本信息等进行了重新写入,内容肯定和之前的不一样,这样就造成了,上文中我提到的clusterID不一致的问题,这样,你再次启动Hadoop,所有功能都正常使用,但唯独jps命令下看不到DataNode线程,这当然会使我们每个程序员感到惊慌,怎么办?

首先,在格式化之前,将你设置的存储Hadoop信息目录下清空,即我上图中的例子tmp目录,将此目录清空即可。也可直接删除此目录,然后新建一个。
然后,进行格式化,这样所产生的NameNode和DataNode信息都是新的,也都是一组的,问题就解决了,这个是最简单最有效的方法。
如果有数据还在,又不想清空数据,那么这个方案就是你的福音。
既然是版本号不一致产生的问题,那么我们就单独解决版本号的问题,将你格式化之后的NameNode的VERSION文件找到,然后将里面的clusterID进行复制,再找到DataNode的VERSION文件,将里面的clusterID进行替换,保存之后重启,那么就可以正常的使用了。查找的的路径,已经在上图中进行了展示,这里不做赘述。
就以上问题,目前我只想到两个解决方案。
标签:-name pool views pos 完全 stat 查找 storage height
原文地址:https://www.cnblogs.com/h12l4/p/9079462.html