标签:一致性哈希算法 哈希算法 hashing 缓存 Consistent hashing
一致性哈希算法的起源和介绍就不说了,一般这个是用于分布式缓存,用于处理缓存的数据和多个缓存服务器之间的对应关系。说到一致性哈希算法总会以一般的哈希算法为开头,这里也同样这样介绍。
按照网上大多数的范例,假设有3台缓存服务器A、B、C。对每条要缓存的数据进行哈希计算,然后对服务器数求余,得到的数字就是该数据要存的缓存服务器的位置。
计算公式:
hash(object) % N这里N为3,计算的结果肯定是0、1、2中的一个,0对应A,1对应B,2对应C。
正常情况下这种方式是可行的。但是,如果业务量增大要增加缓存服务器,这时候缓存数据库上多数的缓存数据就会失效,减少服务器也会出现这种情况,而且如果缓存服务器中缓存数据失效过多也有可能引起数据服务器的访问量突然增大,造成数据服务器的服务瘫痪。
意识到了上面的方法的不足,现在再来看下一致性哈希算法。
一致性哈希算法有些地方说是对象的hash值对2的32次方进行取模,也有的地方说是拿对象的hash值对2的32次方进行映射。
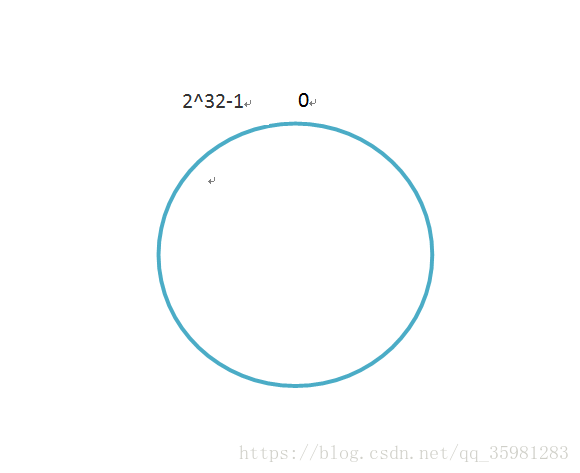
一致性哈希算法涉及到一个很重要的概念——哈希环,这和环上有2^32个点,这些点形成了一个闭环,如下:
0为起始点,0的左边第一个点是2^32-1。
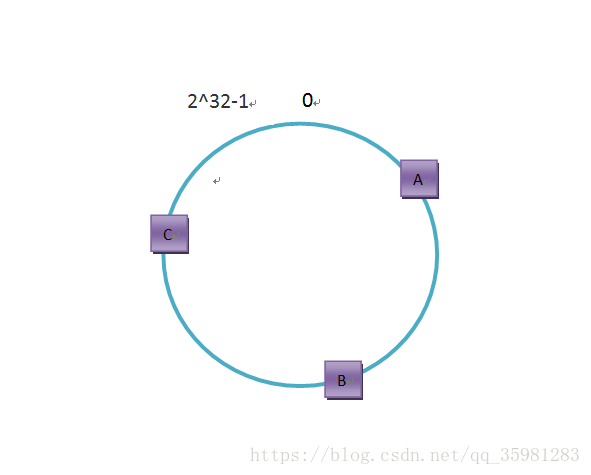
先求出A、B、C三台服务器的hash值,一般是对服务器的ip或者服务器的名称求hash值。
假设A、B、C三台服务器对应的位置如下:
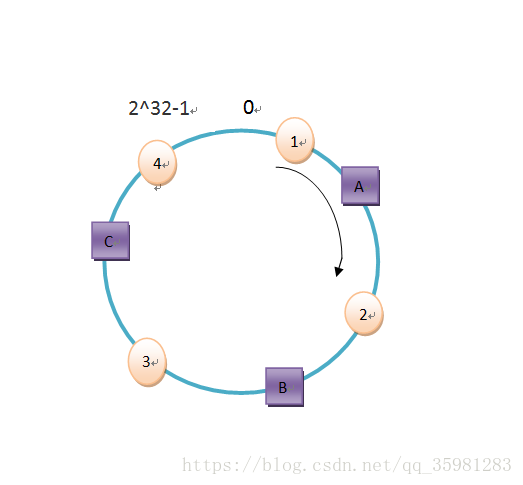
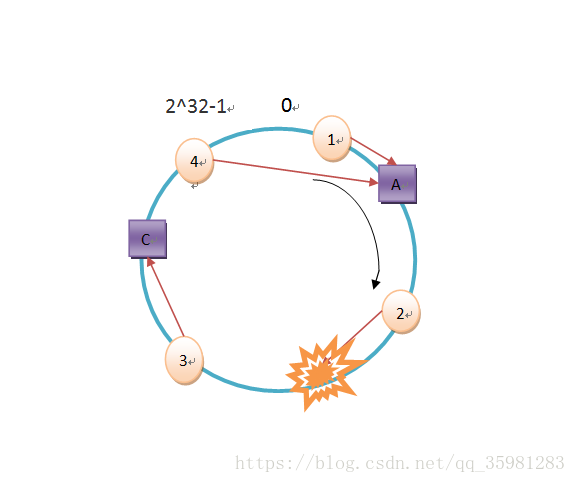
现在以4个数据为例来存储:object1、object2、object3、object4。
计算hash值:
hash(object1) = key1
hash(object2) = key2
hash(object3) = key3
hash(object4) = key4这四个值在hash环上的对应为从0开始,按照顺时针,离这个hash值最近的那个节点作为存储服务器。
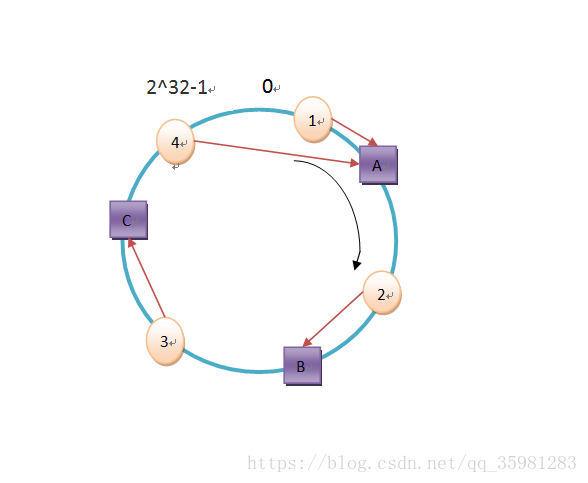
其对应存储如下:
其中object4之后没有节点,会从0开始寻找缓存服务器,所以存到A上。
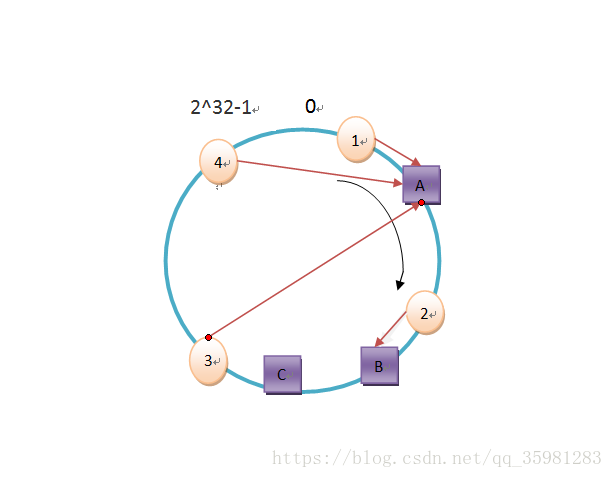
现在如果去掉节点B,可以看出object2的缓存就找到C上了,这时候是找不到的,但是object1、object3和object4依然是有效的。
如果新增节点也是类似情况,相对来说对原有服务器的影响很小很小。
但是,现实中A、B、C节点在哈希环上的分布很多时候都会是下面这种情况:
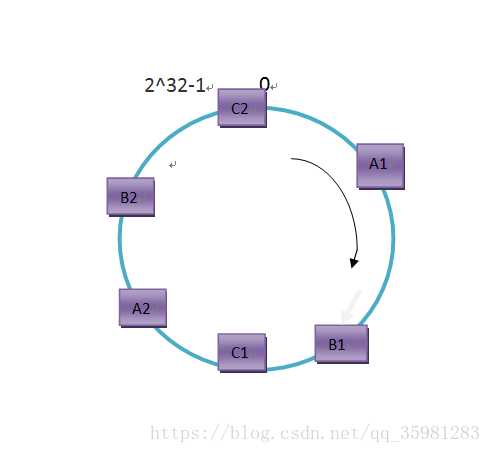
这时候C节点是没用的,负载都集中到了A上。针对这种情况引入了虚拟节点。
所谓的虚拟节点就是一台主机在哈希环上分配多个节点,一般哈希环上节点越多分配的越均匀,才能更大的体现出一致性哈希算法的优势。
这里我们对A、B、C都映射两个虚拟节点,虚拟节点的映射可以通过类似如下方式来生成:
hash(ipA#A1) = key1
hash(ipA#A2) = key2
hash(ipB#B1) = key3
hash(ipB#B2) = key4
hash(ipC#C1) = key5
hash(ipC#C2) = key6这个时候缓存主机分配的相对来说比较均匀,同样数据缓存的时候对应的主机也会相对均匀。
标签:一致性哈希算法 哈希算法 hashing 缓存 Consistent hashing
原文地址:http://blog.51cto.com/12719721/2120001