标签:rtc 信息 百分比 元素 数据挖掘 ssis 估算 dia code
机器学习中的统计学方法。
统计学是机器学习的一个支柱。
原始观察仅仅是数据, 但它们不是信息或知识。数据引发问题, 例如:
众数、平均数和中位数在某些情况下测量的都是数据的中心。
下面两个公式分别计算的是sample和population的平均数:
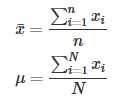
要想找出数据的中位数,我们首先要给数据排序。假设我们有n个已经排好序的数,它们是x1,x2,x3,…,xn。下面是找出它们中位数的公式:
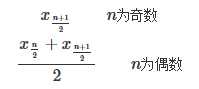
参见Boxplot。请看下图:
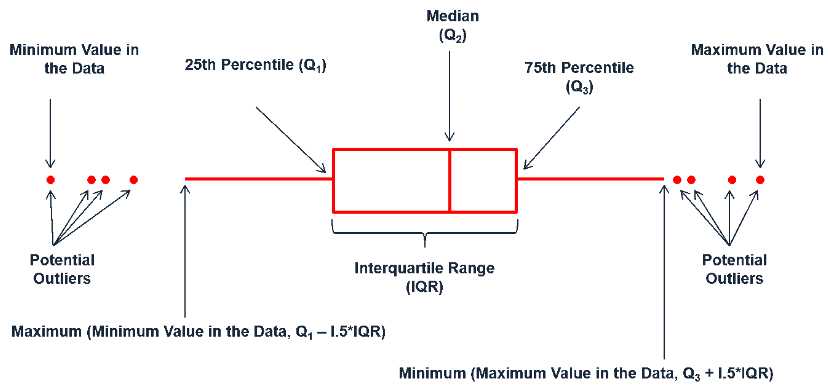
上图中已经很明白地说明Q1、Q3和IQR各自的含义了。从上图我们也看到了小于Q1?1.5?IQR或大于Q3+1.5?IQR是可能存在的异常值。在一些情况下,统计学家用这样的方法去掉异常值。
下面,介绍一个找Q1、Q3的方法。
找到Q2,也就是数据集的Median,因此把数据集分成两部分
方差和标准差度量的是数据的分散程度。计算方差和标准差的公式如下:
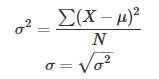
但是绝对值不是更简单明了吗,它也可以度量数据的分散程度啊?为什么我们要费这么大功夫去平方然后在开根号求标准差?这是因为在统计分析中,标准差有一些很Cool的性质。
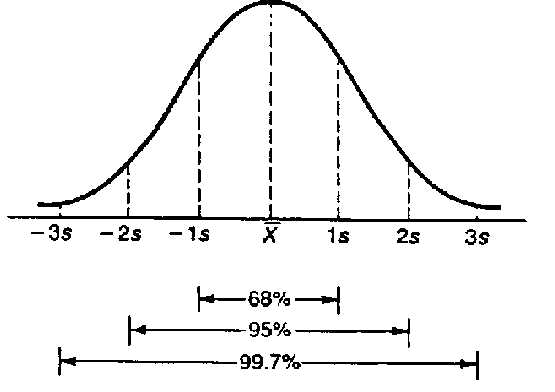
从上图我们可以看出,在正态分布中,有大约68%的数据落在距离平均值1个标准差的范围内,有大约95%的数据落在距离平均值2个标准差的范围内,等等。实际上,我们可以求出任意百分比的数据落在什么样的标准差范围内。因此,求出标准差至关重要。
如果我们的数据集是整个population,那么求标准差的公式和上面的一样。但是如果我们的数据集仅仅是从population中抽取的sample,我们的公式如下:
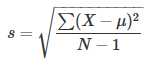
把它叫做Sample standard deviation. 直观上来讲,population中数据大多数都分布在中心,因此我们的Sample中的数据基本上都来自于中心,这样所计算出的标准差要比真实的标准差要小,因为它的数据分散程度要小。因此我们要用N-1来求解(叫做Bessel’s Correction),这样会使我们求出的标准差更加接近真实的标准差。Sample standard deviation也就是population标准差σ的估算。
z-score表示一个元素与mean之间相差几个标准差。它的计算公式如下:
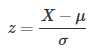
σ:标准差
当我们standardization正态分布时(即z-score过程),我们将得到一个标准的正态分布,即平均值为0,标准差为1的正态分布。
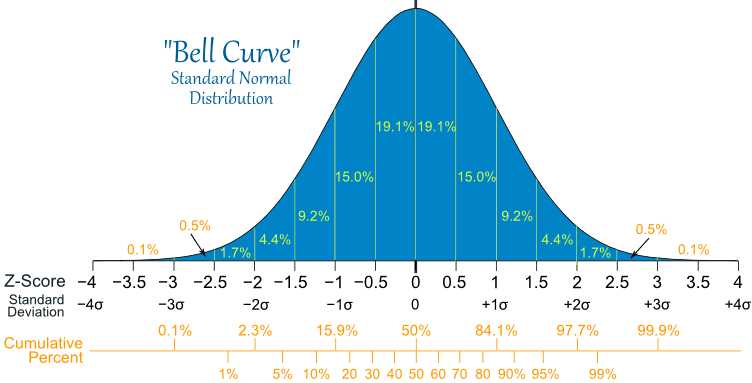
在上图中的正态分布中,X轴上随机选择一个小于x的概率等于负无穷到x与曲线形成的面积。
可以用微积分的知识求出任意两点与曲线之间形成的面积。我们也可以用Z-Table来求出小于某个x值的面积。但是,在用Z-Table之前,我们必须要把正态分布standardization,也就是求出对应x值的z-score。
假设一个sample包含很多的observations,每个observation是随机生成的并且它们之间是相互独立的,计算这个sample的平均值。重复计算这样sample的平均值,中心极限定理告诉我们这些平均值服从正态分布。
在概率理论中,中心极限定理的定义为:在特定的条件下,不管潜在的population分布是什么样的,大量重复地计算独立随机变量的算术平均值,这些平均值将服从正态分布。
维基百科上给出抽样分布的定义为:In statistics, a sampling distribution or finite-sample distribution is the probability distribution of a given statistic based on a random sample.
举个例子,假设我们有一个mean为μ,方差为σ2的正态分布。我们重复地从这个population中取出samples,然后分别计算每个sample的平均值,这个统计值叫做sample mean.
每个sample都有一个平均值,这些平均值的分布叫做sampling distribution of the sample mean.
由于population的分布是正态分布,这个分布也是正态分布,它服从N(μ, σ2/n),这里n为sample size. 根据中心极限定理,即使population分布不是正态的,sampling distribution也通常接近于正态分布。
以下是应用机器学习项目中使用统计方法的10个例子。
Statistical Methods for Machine Learning
标签:rtc 信息 百分比 元素 数据挖掘 ssis 估算 dia code
原文地址:https://www.cnblogs.com/ytxwzqin/p/9087604.html