标签:实现 图片 代码实现 后序遍历 回溯 它的 def 内存 style
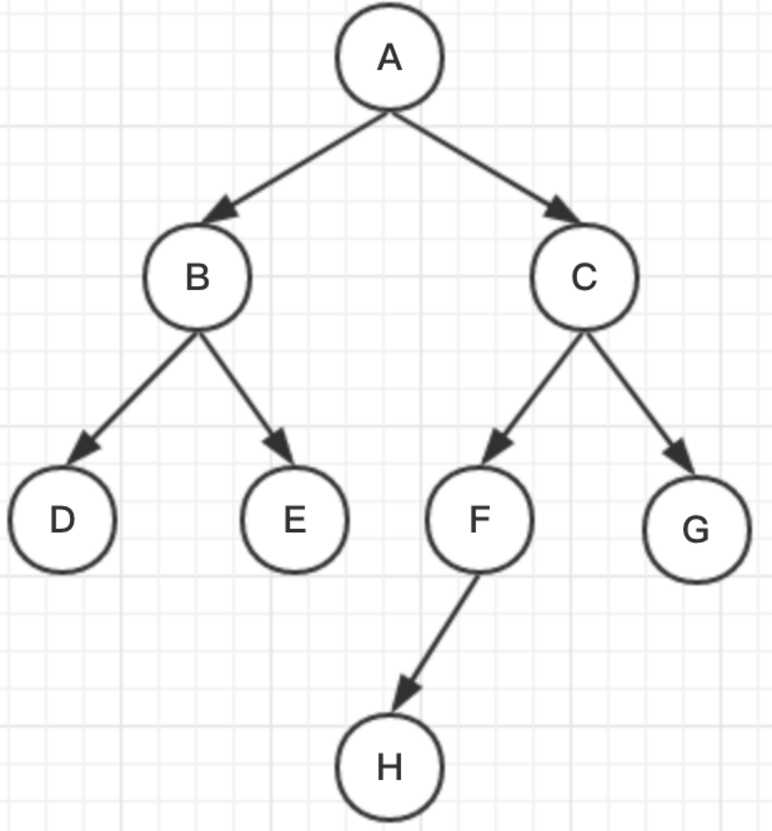
遍历规则:不断地沿着顶点的深度方向遍历。顶点的深度方向是指它的邻接点方向。
最后得出的结果为:ABDECFHG。
Python代码实现的伪代码如下:
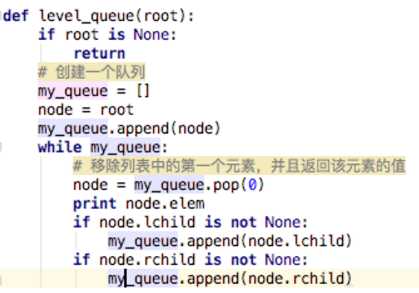
遍历规则:
1)先访问完当前顶点的所有邻接点。(应该看得出广度的意思)
2)先访问顶点的邻接点先于后访问顶点的邻接点被访问。
最后得出的结果为:ABCDEFGH。
Python代码实现的伪代码如下:
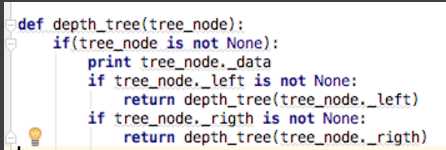
深度优先遍历:对每一个可能的分支路径深入到不能再深入为止,而且每个结点只能访问一次。要特别注意的是,二叉树的深度优先遍历比较特殊,可以细分为先序遍历、中序遍历、后序遍历(我们前面使用的是先序遍历)。具体说明如下:
先序遍历:对任一子树,先访问根,然后遍历其左子树,最后遍历其右子树。
中序遍历:对任一子树,先遍历其左子树,然后访问根,最后遍历其右子树。
后序遍历:对任一子树,先遍历其左子树,然后遍历其右子树,最后访问根。
广度优先遍历:又叫层次遍历,从上往下对每一层依次访问,在每一层中,从左往右(也可以从右往左)访问结点,访问完一层就进入下一层,直到没有结点可以访问为止
深度优先搜素算法:不全部保留结点,占用空间少;有回溯操作(即有入栈、出栈操作),运行速度慢。
广度优先搜索算法:保留全部结点,占用空间大; 无回溯操作(即无入栈、出栈操作),运行速度快。
通常深度优先搜索法不全部保留结点,扩展完的结点从数据库中弹出删去,这样,一般在数据库中存储的结点数就是深度值,因此它占用空间较少。
所以,当搜索树的结点较多,用其它方法易产生内存溢出时,深度优先搜索不失为一种有效的求解方法。
广度优先搜索算法,一般需存储产生的所有结点,占用的存储空间要比深度优先搜索大得多,因此,程序设计中,必须考虑溢出和节省内存空间的问题。
但广度优先搜索法一般无回溯操作,即入栈和出栈的操作,所以运行速度比深度优先搜索要快些
标签:实现 图片 代码实现 后序遍历 回溯 它的 def 内存 style
原文地址:https://www.cnblogs.com/chenyanlong/p/9090992.html