标签:同方 rand als 不可 通过 turn 混合 文本 unit
文本分类任务中可以利用CNN来提取句子中类似 n-gram 的关键信息。
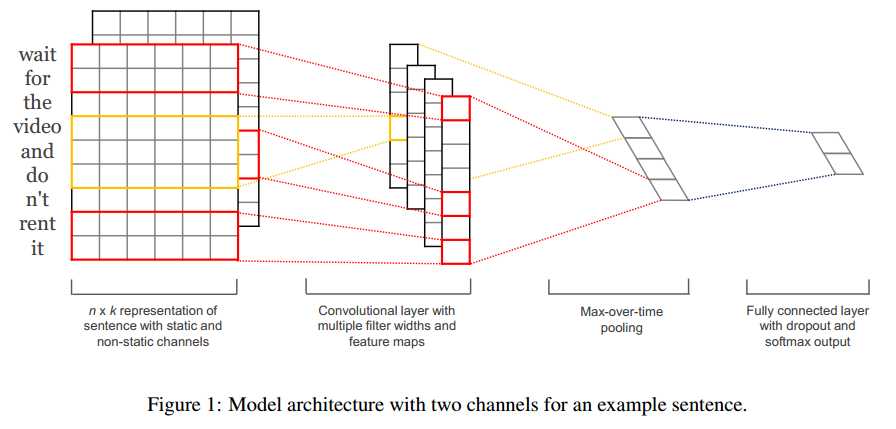
TextCNN的详细过程原理图见下:
keras 代码:
1 def convs_block(data, convs=[3, 3, 4, 5, 5, 7, 7], f=256): 2 pools = [] 3 for c in convs: 4 conv = Activation(activation="relu")(BatchNormalization()( 5 Conv1D(filters=f, kernel_size=c, padding="valid")(data))) 6 pool = GlobalMaxPool1D()(conv) 7 pools.append(pool) 8 return concatenate(pools) 9 10 11 def rnn_v1(seq_length, embed_weight, pretrain=False): 12 13 main_input = Input(shape=(seq_length,), dtype=‘float64‘) 14 15 in_dim, out_dim = embed_weight.shape 16 embedding = Embedding(input_dim=in_dim, weights=[ 17 embed_weight], output_dim=out_dim, trainable=False) 18 content = Activation(activation="relu")( 19 BatchNormalization()((TimeDistributed(Dense(256))(embedding(main_input))))) 20 content = Bidirectional(GRU(256))(content) 21 content = Dropout(0.3)(content) 22 fc = Activation(activation="relu")( 23 BatchNormalization()(Dense(256)(content))) 24 main_output = Dense(3, 25 activation=‘softmax‘)(fc) 26 27 model = Model(inputs=main_input, outputs=main_output) 28 model.compile(optimizer=‘adam‘, 29 loss=‘categorical_crossentropy‘, 30 metrics=[‘accuracy‘]) 31 model.summary() 32 return model
说明如下:
如图所示,,假设句子有 n 个词,vector的维数为 k ,那么这个矩阵就是 n×k 的。
这个矩阵的类型可以是静态的(static),也可以是动态的(non static)。静态就是word vector是固定不变的,而动态则是在模型训练过程中,word vector也当做是可优化的参数,通常把反向误差传播导致word vector中值发生变化的这一过程称为Fine tune。
对于未登录词的vector,可以用0或者随机小的正数来填充。
输入层通过卷积操作得到若干个Feature Map,卷积窗口的大小为 m*k ,其中 m表示n_gram中的n,通过卷积将得到F个列数为1的Feature Map,F表示卷积核的个数。
接下来的池化层,文中用了一种称为Max-over-time Pooling的方法。这种方法就是简单地从之前一维的Feature Map中提出最大的值,文中解释最大值代表着最重要的信号。
最终池化层的输出为各个Feature Map的最大值,即一个一维的向量。polling之后得到的是1*F的一维向量。
池化层的一维向量的输出通过全连接的方式,连接一个Softmax层。
最终实现时,我们可以在倒数第二层的全连接部分上使用Dropout技术,即对全连接层上的权值参数给予L2正则化的限制。这样做的好处是防止隐藏层单元自适应(或者对称),从而减轻过拟合的程度。
1. 数据
实验用到的数据集如下(具体的名称和来源可以参考论文):

2. 模型训练和调参
这些参数的选择都是基于SST-2 dev数据集,通过网格搜索方法(Grid Search)得到的最优参数。另外,训练过程中采用随机梯度下降方法,基于shuffled mini-batches之上的,使用了Adadelta update rule(Zeiler, 2012)。
3. 预训练的Word Vector
这里的word vector使用的是公开的数据,即连续词袋模型(COW)在Google News上的训练结果。未登录次的vector值是随机初始化的。
4. 实验结果
实验结果如下图:

其中,前四个模型是上文中所提出的基本模型的各个变种:
Fine tuned;5. 结论
CNN-static较与CNN-rand好,说明pre-training的word vector确实有较大的提升作用(因为pre-training的word vector显然利用了更大规模的文本数据信息);CNN-non-static较于CNN-static大部分要好,说明适当的Fine tune也是有利的,是因为使得vectors更加贴近于具体的任务;CNN-multichannel较于CNN-single在小规模的数据集上有更好的表现,实际上CNN-multichannel体现了一种折中思想,即既不希望Fine tuned的vector距离原始值太远,但同时保留其一定的变化空间。值得注意的是,static的vector和non-static的相比,有一些有意思的现象如下表格:

bad对应的最相近词为good,原因是这两个词在句法上的使用是极其类似的(可以简单替换,不会出现语句毛病);而在non-static的版本中,bad对应的最相近词为terrible,这是因为在Fune tune的过程中,vector的值发生改变从而更加贴切数据集(是一个情感分类的数据集),所以在情感表达的角度这两个词会更加接近;!最接近一些表达形式较为激进的词汇,如lush等;而,则接近于一些连接词,这和我们的主观感受也是相符的。Kim Y的这个模型很简单,但是却有着很好的性能。后续Denny用TensorFlow实现了这个模型的简单版本,可参考这篇博文;以及Ye Zhang等人对这个模型进行了大量的实验,并给出了调参的建议,可参考这篇论文。
下面总结一下Ye Zhang等人基于Kim Y的模型做了大量的调参实验之后的结论:
Ye Zhang等人给予模型调参者的建议如下:
non-static版本的word2vec或者GloVe要比单纯的one-hot representation取得的效果好得多;1-10之间,当然对于长句,使用更大的过滤器也是有必要的;Feature Map的数量在100-600之间;ReLU和tanh两种激活函数表现较佳;1-max pooling就已经足够了,可以没必要设置太复杂的pooling方式;Feature Map的数量使得模型的性能下降时,可以考虑增大正则的力度,如调高dropout的概率;论文附录中还附上了各种调参结果,感兴趣的可以前往阅读之。
TextCNN详细过程:第一层是图中最左边的7乘5的句子矩阵,每行是词向量,维度=5,这个可以类比为图像中的原始像素点了。然后经过有 filter_size=(2,3,4) 的一维卷积层,每个filter_size 有两个输出 channel。第三层是一个1-max pooling层,这样不同长度句子经过pooling层之后都能变成定长的表示了,最后接一层全连接的 softmax 层,输出每个类别的概率。
特征:这里的特征就是词向量,有静态(static)和非静态(non-static)方式。static方式采用比如word2vec预训练的词向量,训练过程不更新词向量,实质上属于迁移学习了,特别是数据量比较小的情况下,采用静态的词向量往往效果不错。non-static则是在训练过程中更新词向量。推荐的方式是 non-static 中的 fine-tunning方式,它是以预训练(pre-train)的word2vec向量初始化词向量,训练过程中调整词向量,能加速收敛,当然如果有充足的训练数据和资源,直接随机初始化词向量效果也是可以的。
通道(Channels):图像中可以利用 (R, G, B) 作为不同channel,而文本的输入的channel通常是不同方式的embedding方式(比如 word2vec或Glove),实践中也有利用静态词向量和fine-tunning词向量作为不同channel的做法。
一维卷积(conv-1d):图像是二维数据,经过词向量表达的文本为一维数据,因此在TextCNN卷积用的是一维卷积。一维卷积带来的问题是需要设计通过不同 filter_size 的 filter 获取不同宽度的视野。
Pooling层:利用CNN解决文本分类问题的文章还是很多的,比如这篇 A Convolutional Neural Network for Modelling Sentences 最有意思的输入是在 pooling 改成 (dynamic) k-max pooling ,pooling阶段保留 k 个最大的信息,保留了全局的序列信息。比如在情感分析场景,举个例子:
“ 我觉得这个地方景色还不错,但是人也实在太多了 ”
虽然前半部分体现情感是正向的,全局文本表达的是偏负面的情感,利用 k-max pooling能够很好捕捉这类信息。
《Convolutional Neural Networks for Sentence Classification》速读
标签:同方 rand als 不可 通过 turn 混合 文本 unit
原文地址:https://www.cnblogs.com/zle1992/p/9093102.html