标签:多行 enter 就是 amp 描述 period under imu weight
oracle的正则表达式(regular expression)
特殊字符:
‘^‘ 匹配输入字符串的开始位置,在方括号表达式中使用,此时它表示不接受该字符集合。
‘$‘ 匹配输入字符串的结尾位置。如果设置了 RegExp 对象的 Multiline 属性,则 $ 也匹配 ‘n‘ 或 ‘r‘。
‘.‘ 匹配除换行符 n之外的任何单字符。
‘?‘ 匹配前面的子表达式零次或一次。
‘*‘ 匹配前面的子表达式零次或多次。
‘+‘ 匹配前面的子表达式一次或多次。
‘( )‘ 标记一个子表达式的开始和结束位置。
‘[]‘ 标记一个中括号表达式。
‘{m,n}‘ 一个精确地出现次数范围,m= <出现次数 <=n,‘{m}‘表示出现m次,‘{m,}‘表示至少出现m次。
‘ |‘ 指明两项之间的一个选择。例子‘^([a-z]+ |[0-9]+)$‘表示所有小写字母或数字组合成的字符串。
num 匹配 num,其中 num 是一个正整数。对所获取的匹配的引用。
正则表达式的一个很有用的特点是可以保存子表达式以后使用, 被称为Backreferencing. 允许复杂的替换能力
如调整一个模式到新的位置或者指示被代替的字符或者单词的位置. 被匹配的子表达式存储在临时缓冲区中,
缓冲区从左到右编号, 通过数字符号访问。 下面的例子列出了把名字 aa bb cc 变成
cc, bb, aa.
Select REGEXP_REPLACE(‘aa bb cc‘,‘(.*) (.*) (.*)‘, ‘3, 2, 1‘) FROM dual;
字符簇:
[[:alpha:]] 任何字母。
[[:digit:]] 任何数字。
[[:alnum:]] 任何字母和数字。
[[:space:]] 任何白字符。
[[:upper:]] 任何大写字母。
[[:lower:]] 任何小写字母。
[[:punct:]] 任何标点符号。
[[:xdigit:]] 任何16进制的数字,相当于[0-9a-fA-F]
各种操作符的运算优先级
(), (?:), (?=), [] 圆括号和方括号
*, +, ?, {n}, {n,}, {n,m} 限定符
^, $, anymetacharacter 位置和顺序
| “或”操作
match_option的取值如下:
‘c’ 说明在进行匹配时区分大小写(缺省值);
x^I|*I0 ‘i‘ 说明在进行匹配时不区分大小写;
‘n‘ 允许使用可以匹配任意字符的操作符;
‘m‘ 将x作为一个包含多行的字符串。
一. 匹配字符
|
字符类 |
匹配的字符 |
举 例 |
|
\d |
从0-9的任一数字 |
\d\d匹配72,但不匹配aa或7a |
|
\D |
任一非数字字符 |
\D\D\D匹配abc,但不匹配123 |
|
\w |
任一单词字符,包括A-Z,a-z,0-9和下划线 |
\w\w\w\w匹配Ab-2,但不匹配∑£$%*或Ab_@ |
|
\W |
任一非单词字符 |
\W匹配@,但不匹配a |
|
\s |
任一空白字符,包括制表符,换行符,回车符,换页符和垂直制表符 |
匹配在HTML,XML和其他标准定义中的所有传统空白字符 |
|
\S |
任一非空白字符 |
空白字符以外的任意字符,如A%&g3;等 |
|
. |
任一字符 |
匹配除换行符以外的任意字符除非设置了MultiLine先项 |
|
[…] |
括号中的任一字符 |
[abc]将匹配一个单字符,a,b或c. [a-z]将匹配从a到z的任一字符 |
|
[^…] |
不在括号中的任一字符 |
[^abc]将匹配一个a、b、c之外的单字符,可以a,b或A、B、C [a-z]将匹配不属于a-z的任一字符,但可以匹配所有的大写字母 |
二. 重复字符
|
重复字符 |
含 义 |
举 例 |
|
{n} |
匹配前面的字符n次 |
x{2}匹配xx,但不匹配x或xxx |
|
{n,} |
匹配前面的字符至少n次 |
x{2}匹配2个或更多的x,如xxx,xxx.. |
|
{n,m} |
匹配前面的字符至少n次,至多m次。如果n为0,此参数为可选参数 |
x{2,4}匹配xx,xxx,xxxx,但不匹配xxxxx |
|
? |
匹配前面的字符0次或1次,实质上也是可选的 |
x?匹配x或零个x |
|
+ |
匹配前面的字符0次或多次 |
x+匹配x或xx或大于0的任意多个x |
|
* |
匹配前面的字符0次或更多次 |
x*匹配0,1或更多个x |
三. 定位字符
|
定位字符 |
描 述 |
|
^ |
随后的模式必须位于字符串的开始位置,如果是一个多行字符串,则必须位于行首。对于多行文本(包含回车符的一个字符串)来说,需要设置多行标志 |
|
$ |
前面的模式必须位于字符串的未端,如果是一个多行字符串,必须位于行尾 |
|
\A |
前面的模式必须位于字符串的开始位置,忽略多行标志 |
|
\z |
前面的模式必须位于字符串的未端,忽略多行标志 |
|
\Z |
前面的模式必须位于字符串的未端,或者位于一个换行符前 |
|
\b |
匹配一个单词边界,也就是一个单词字符和非单词字符中间的点。要记住一个单词字符是[a-zA-Z0-9]中的一个字符。位于一个单词的词首 |
|
\B |
匹配一个非单词字符边界位置,不是一个单词的词首 |
REGEXP_LIKE(source_string, pattern[, match_parameter])函数

描述:返回满足匹配模式的字符串。相当于增强的like函数。
Source_string指定源字符表达式;
pattern指定规则表达式;
match_parameter指定默认匹配操作的文本串。
Examples
--The following query returns the first and last names for those employees with a first name of Steven or Stephen --(where first_name begins with Ste and ends with en and in between is either v or ph): --查询返回结果为first_name以ste开头,en结尾,中间为v或ph SQL> SELECT first_name, last_name 2 FROM employees 3 WHERE REGEXP_LIKE (first_name, ‘^Ste(v|ph)en$‘) 4 ORDER BY first_name, last_name; FIRST_NAME LAST_NAME -------------------- ------------------------- Stephen Stiles Steven King Steven Markle --The following query returns the last name for those employees with a double vowel in their last name --(where last_name contains two adjacent occurrences of either a, e, i, o, or u, regardless of case): --last_name中包含aeiou中任何一个,不区分大小写 SELECT last_name FROM employees WHERE REGEXP_LIKE (last_name, ‘([aeiou])\1‘, ‘i‘) ORDER BY last_name; LAST_NAME ------------------------- De Haan Greenberg Khoo Gee Greene Lee Bloom Feeney --用到的实例 判断客户信息中手机号格式是否正确 REGEXP_LIKE(CUS_MOBILE1, ‘\d*([0-9]{1}+[0-9]{1}+)\1{4,}\d*‘) --类似1313131……
OR REGEXP_LIKE(CUS_MOBILE1, ‘\d*(\d)\1{6,}\d*‘) --某一位数连续重复5次 OR REGEXP_LIKE(CUS_MOBILE1,‘0123|1234|2345|3456|4567|5678|6789|7890|01234|12345|23456|34567|45678|56789|67890
|012345|123456|234567|345678|456789|567890
|0123456|1234567|2345678|3456789|4567890|01234567|12345678|23456789|34567890
|012345678|123456789|234567890|0123456789|1234567890|‘) --连续增长7位以上
REGEXP_REPLACE(source_string,pattern,replace_string,position,occurtence,match_parameter)函数
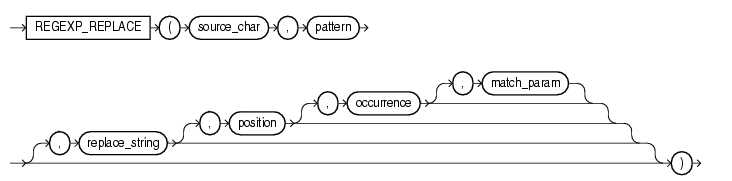
描述:字符串替换函数。相当于增强的replace函数。
Source_string指定源字符表达式;
pattern指定规则表达式;
replace_string指定用于替换的字符串;
position指定起始搜索位置;
occurtence指定替换出现的第n个字符串;
match_parameter指定默认匹配操作的文本串
--The following example examines phone_number, -- looking for the pattern xxx.xxx.xxxx. Oracle reformats this pattern with (xxx) xxx-xxxx. SELECT REGEXP_REPLACE(phone_number, ‘([[:digit:]]{3})\.([[:digit:]]{3})\.([[:digit:]]{4})‘, ‘(\1) \2-\3‘) "REGEXP_REPLACE" FROM employees ORDER BY "REGEXP_REPLACE"; REGEXP_REPLACE -------------------------------------------------------------------------------- (515) 123-4444 (515) 123-4567 (515) 123-4568 (515) 123-4569 (515) 123-5555 --The following example examines the string, looking for two or more spaces.
--Oracle replaces each occurrence of two or more spaces with a single space. SELECT REGEXP_REPLACE(‘500 Oracle Parkway, Redwood Shores, CA‘, ‘( ){2,}‘, ‘ ‘) "REGEXP_REPLACE" FROM DUAL; REGEXP_REPLACE -------------------------------------- 500 Oracle Parkway, Redwood Shores, CA
REGEXP_SUBSTR(source_string, pattern[,position [, occurrence[, match_parameter]]])函数
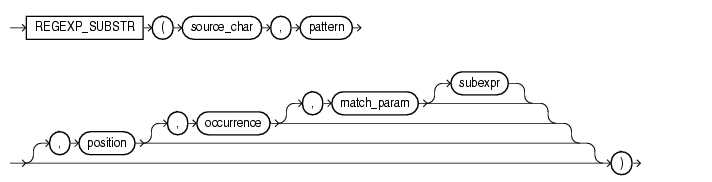
描述:返回匹配模式的子字符串。相当于增强的substr函数。
Source_string指定源字符表达式;
pattern指定规则表达式;
position指定起始搜索位置;
occurtence指定替换出现的第n个字符串;
match_parameter指定默认匹配操作的文本串。
--The following example examines the string, looking for the first substring bounded by commas. --Oracle Database searches for a comma followed by one or more occurrences of non-comma characters followed by a comma. --Oracle returns the substring, including the leading and trailing commas. SELECT REGEXP_SUBSTR(‘500 Oracle Parkway, Redwood Shores, CA‘, ‘,[^,]+,‘) "REGEXPR_SUBSTR" FROM DUAL; REGEXPR_SUBSTR ----------------- , Redwood Shores, --The following example examines the string,
--looking for http:// followed by a substring of one or more alphanumeric characters and optionally,
--a period (.). Oracle searches for a minimum of three and a maximum of four occurrences of this substring between
--http:// and either a slash (/) or the end of the string. SELECT REGEXP_SUBSTR(‘http://www.example.com/products‘, ‘http://([[:alnum:]]+\.?){3,4}/?‘) "REGEXP_SUBSTR" FROM DUAL; REGEXP_SUBSTR ---------------------- http://www.example.com/ --The next two examples use the subexpr argument to return a specific subexpression of pattern.
--The first statement returns the first subexpression in pattern: SELECT REGEXP_SUBSTR(‘1234567890‘, ‘(123)(4(56)(78))‘, 1, 1, ‘i‘, 1) "REGEXP_SUBSTR" FROM DUAL; REGEXP_SUBSTR ------------------- 123 --The next statement returns the fourth subexpression in pattern: SELECT REGEXP_SUBSTR(‘1234567890‘, ‘(123)(4(56)(78))‘, 1, 1, ‘i‘, 4) "REGEXP_SUBSTR" FROM DUAL; REGEXP_SUBSTR ------------------- 78
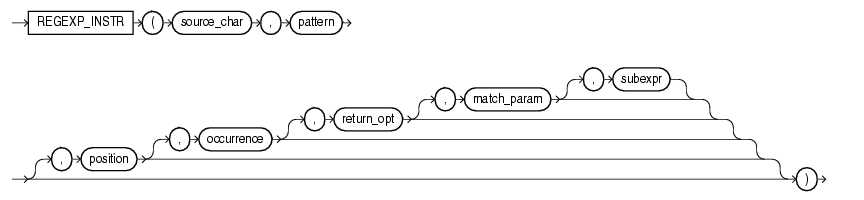
REGEXP_INSTR(source_string, pattern[, start_position[, occurrence[, return_option[, match_parameter]]]])函数
描述: 该函数查找 pattern ,并返回该模式的第一个位置。
您可以随意指定您想要开始搜索的 start_position。 occurrence 参数默认为1,
除非您指定您要查找接下来出现的一个模式。return_option 的默认值为 0,它返回该模式的起始位置;
值为 1 则返回符合匹配条件的下一个字符的起始位置
--The following example examines the string, looking for occurrences of one or more non-blank characters.
--Oracle begins searching at the first character in the string and
--returns the starting position (default) of the sixth occurrence of one or more non-blank characters. SELECT REGEXP_INSTR(‘500 Oracle Parkway, Redwood Shores, CA‘, ‘[^ ]+‘, 1, 6) "REGEXP_INSTR" FROM DUAL; REGEXP_INSTR ------------ 37 --The following example examines the string, looking for occurrences of words beginning with s, r, or p, regardless of case,
--followed by any six alphabetic characters. Oracle begins searching at the third character in the string and
--returns the position in the string of the character following the second occurrence of a seven-letter word beginning with s, r, or p,
--regardless of case. SELECT REGEXP_INSTR(‘500 Oracle Parkway, Redwood Shores, CA‘, ‘[s|r|p][[:alpha:]]{6}‘, 3, 2, 1, ‘i‘) "REGEXP_INSTR" FROM DUAL; REGEXP_INSTR ------------ 28 --The following examples use the subexpr argument to search for a particular subexpression in pattern.
--The first statement returns the position in the source string of the first character in the first subexpression, which is ‘123‘: SELECT REGEXP_INSTR(‘1234567890‘, ‘(123)(4(56)(78))‘, 1, 1, 0, ‘i‘, 1) "REGEXP_INSTR" FROM DUAL; REGEXP_INSTR ------------------- 1 --The next statement returns the position in the source string of the first character in the second subexpression, which is ‘45678‘: SELECT REGEXP_INSTR(‘1234567890‘, ‘(123)(4(56)(78))‘, 1, 1, 0, ‘i‘, 2) "REGEXP_INSTR" FROM DUAL; REGEXP_INSTR ------------------- 4 --The next statement returns the position in the source string of the first character in the fourth subexpression, which is ‘78‘: SELECT REGEXP_INSTR(‘1234567890‘, ‘(123)(4(56)(78))‘, 1, 1, 0, ‘i‘, 4) "REGEXP_INSTR" FROM DUAL; REGEXP_INSTR ------------------- 7
标签:多行 enter 就是 amp 描述 period under imu weight
原文地址:https://www.cnblogs.com/wangzihong/p/9094805.html