标签:sele 学习 .com 自动 语句 链接 .exe color 技术
urilib是python的标准库,当我们使用Python爬取网页数据时,往往用的是urllib模块,通过调用urllib模块的urlopen(url)方法返回网页对象,并使用read()方法获得url的html内容,然后使用BeautifulSoup抓取某个标签内容,结合正则表达式过滤。但是,用urllib.urlopen(url).read()获取的只是网页的静态html内容,很多动态数据(比如网站访问人数、当前在线人数、微博的点赞数等等)是不包含在静态html里面的,例如我要抓取这个bbs网站中点击打开链接 各个板块的当前在线人数,静态html网页是不包含的(不信你查看页面源代码试试,只有简单的一行)。像这些动态数据更多的是由JavaScript、JQuery、PHP等语言动态生成的,因此再用抓取静态html内容的方式就不合适了。
本文将通过selenium webdriver模块的使用,以获取这些动态生成的内容,尤其是一些重要的动态数据。其实selenium模块的功能不是仅仅限于抓取网页,它是网络自动化测试的常用模块,在Ruby、Java里面都有广泛使用,Python里面虽然使用相对较少,但也是一个非常简洁高效容易上手的自动化测试模块。通过利用selenium的子模块webdriver的使用,解决抓取动态数据的问题,还可以可以对selenium有基本认识,为进一步学习自动化测试打下基础。
1、下载geckodriver.exe:下载地址:https://github.com/mozilla/geckodriver/releases请根据系统版本选择下载;(如Windows 64位系统)
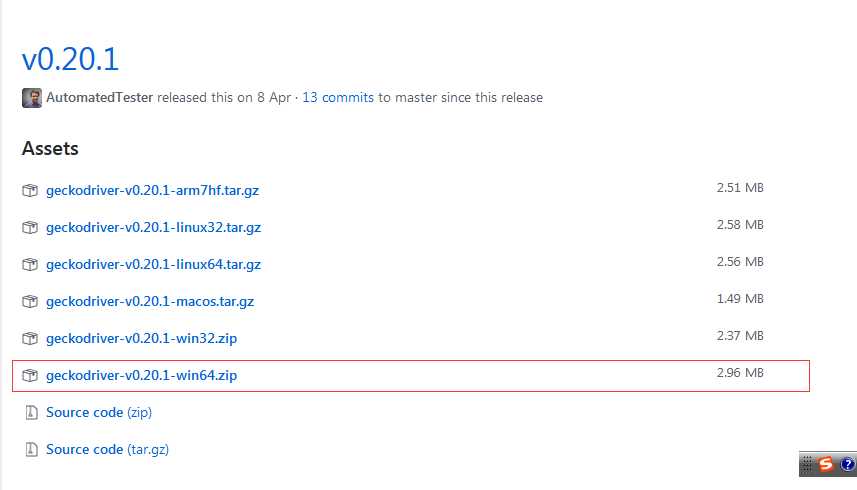
2、下载解压后将getckodriver.exe复制到Firefox的安装目录下,
如(C:\Program Files\Mozilla Firefox),并在环境变量Path中添加路径:C:\Program Files\Mozilla Firefox
3、安装selenium
pip install selenium
4、beautifulsoup4的安装,Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,
pip install beautifulsoup4
pip install lxml
pip install html5lib
5、安装faker
pip install faker
落网的网址是http://www.luoo.net,我们利用火狐浏览器打开该网址,随便选择一期音乐,这里我点击的是摇滚,
然后点击F12,选择第989期,进入该页面,我们就以爬取这一页的内容为例:

进入之后,我们可以看到该网页主要包括以下内容:期刊编号,期刊标题,期刊封面,期刊描述,歌单。
通过下方开发工具中的查看器,可以获取我们感兴趣数据的标签,选择器等信息。以歌单为例:
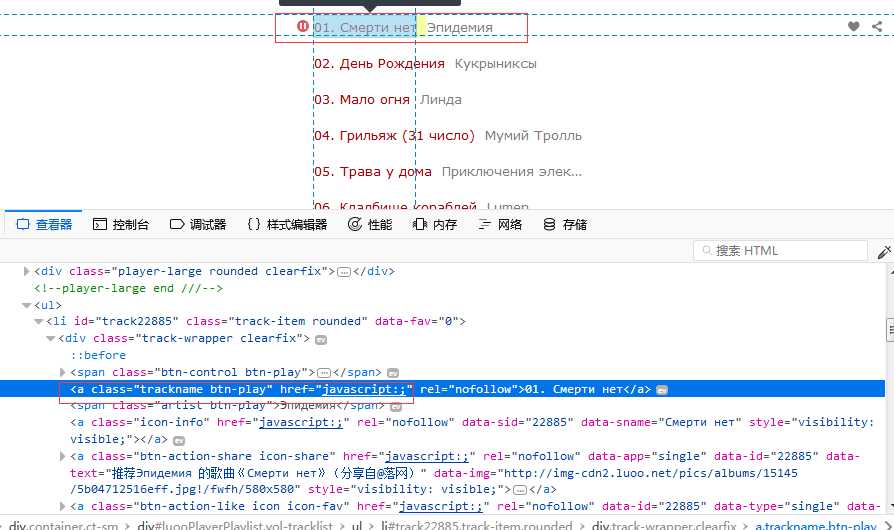
程序代码如下:
# -*- coding: utf-8 -*- """ Created on Thu May 24 16:35:36 2018 @author: zy """ import os from bs4 import BeautifulSoup import random from faker import Factory import queue import threading import urllib.request as urllib from selenium import webdriver import time #"gbk" codec can‘t encode character "\xXX" in position XX : https://www.cnblogs.com/feng18/p/5646925.html #即字符编码是utf-8的字节,但是并不能转换成utf-8编码的字符串 ‘‘‘ 爬取网页信息的类 ‘‘‘ def random_proxies(proxy_ips): ‘‘‘ 从proxy_ips中随机选取一个代理ip args: proxy_ips:list 每个元素都是一个代理ip ‘‘‘ ip_index = random.randint(0, len(proxy_ips)-1) res = { ‘http‘: proxy_ips[ip_index] } return res def fix_characters(s): ‘‘‘ 替换掉s中的一些特殊字符 args: s:字符串 ‘‘‘ for c in [‘<‘, ‘>‘, ‘:‘, ‘"‘, ‘/‘, ‘\\‘, ‘|‘, ‘?‘, ‘*‘]: s = s.replace(c, ‘‘) return s def get_static_url_response_html(url): ‘‘‘ 爬取静态页面数据:https://www.crummy.com/software/BeautifulSoup/bs4/doc/index.zh.html#find reture: 返回html代码 ‘‘‘ fake = Factory.create() # 这里配置可用的代理IP,可以写多个 proxy_ips = [ ‘183.129.151.130‘ ] headers = {‘Accept‘:‘text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8‘, ‘Accept-Charset‘:‘GB2312,utf-8;q=0.7,*;q=0.7‘, ‘Accept-Language‘:‘zh-cn,zh;q=0.5‘, ‘Cache-Control‘:‘max-age=0‘, ‘Connection‘:‘keep-alive‘, ‘Host‘:‘John‘, ‘Keep-Alive‘:‘115‘, ‘Referer‘:url, ‘User-Agent‘: fake.user_agent() #‘User-Agent‘: ‘User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_3) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/56.0.2924.87 Safari/537.36‘ } req = urllib.Request(url=url,origin_req_host=random_proxies(proxy_ips),headers = headers) #当该语句读取的返回值是bytes类型时,要将其转换成utf-8才能正常显示在python程序中 response = urllib.urlopen(req).read() #需要进行类型转换才能正常显示在python中 response = response.decode(‘utf-8‘) return response def download(url,dstpath=None): ‘‘‘ 利用urlretrieve()这个函数可以直接从互联网上下载文件保存到本地路径下 args: url:网页文件或者图片以及其他数据路径 dstpath:保存全路况 ‘‘‘ if dstpath is None: dstpath = ‘./code.jpg‘ try: urllib.urlretrieve(url,dstpath) print(‘Download from {} finish!‘.format(url)) except Exception as e: print(‘Download from {} fail!‘.format(url)) def get_dynamic_url_response_html(url): ‘‘‘ selenium是一个用于Web应用自动化程序测试的工具,测试直接运行在浏览器中,就像真正的用户在操作一样 selenium2支持通过驱动真实浏览器(FirfoxDriver,IternetExplorerDriver,OperaDriver,ChromeDriver) selenium2支持通过驱动无界面浏览器(HtmlUnit,PhantomJs) 1、下载geckodriver.exe:下载地址:https://github.com/mozilla/geckodriver/releases请根据系统版本选择下载;(如Windows 64位系统) 2、下载解压后将getckodriver.exe复制到Firefox的安装目录下, 如(C:\Program Files\Mozilla Firefox),并在环境变量Path中添加路径:C:\Program Files\Mozilla Firefox return: 返回html代码 获取url页面信息后关闭连接 ‘‘‘ browser = webdriver.Firefox(executable_path = r‘D:\ff\geckodriver.exe‘) #html请求 browser.get(url) html = browser.page_source time.sleep(2) #html = browser.page_source.decode(‘utf-8‘) #关闭浏览器 browser.quit() return html class UrlSpyder(threading.Thread): ‘‘‘ 使用Threading模块创建线程:http://www.runoob.com/python/python-multithreading.html 使用Threading模块创建线程,直接从threading.Thread继承,然后重写__init__方法和run方法: 主要思路分成两部分: 1.用来发起http请求分析出播放列表然后丢到队列中 2.在队列中逐条下载文件到本地(如果需要下载文件) 一般分析列表速度较快,下载速度比较慢,可以借助多线程同时进行下载 ‘‘‘ def __init__(self, base_url, releate_urls, que=None): ‘‘‘ args: base_url:网址 releate_urls:相对于网址的网页路径 list集合 que:队列 Python的queue模块中提供了同步的、线程安全的队列类,包括FIFO(先入先出)队列Queue,LIFO(后入先出)队列LifoQueue, 和优先级队列PriorityQueue。这些队列都实现了锁原语,能够在多线程中直接使用。可以使用队列来实现线程间的同步。 ‘‘‘ threading.Thread.__init__(self) print(‘Start spider\n‘) print (‘=‘ * 50) #保存字段信息 self.base_url = base_url if queue is None: self.queue = queue.Queue() else: self.queue = que self.releate_urls = releate_urls def run(self): ‘‘‘ 把要执行的代码写到run函数里面 线程在创建后会直接运行run函数 ‘‘‘ #遍历每一个网页 并开始爬取 for releate_url in self.releate_urls: self.spider(releate_url) print (‘\nCrawl end\n\n‘) def spider(self, releate_url): ‘‘‘ 爬取指定网页数据,并提取我们所需要的网页信息的函数 args: releate_url:网页的相对路径 ‘‘‘ url = os.path.join(self.base_url,releate_url) print (‘Crawling: ‘ + url + ‘\n‘) ‘‘‘ 解析html 针对不同的网址,解析内容也不一样 ‘‘‘ #获取指定网页的html代码 response = get_dynamic_url_response_html(url) #response = getUrlRespHtml(url) ) #使用BeautifulSoup解析这段代码,能够得到一个 BeautifulSoup 的对象,并能按照标准的缩进格式的结构输出: #soup = BeautifulSoup(response, ‘lxml‘) soup = BeautifulSoup(response, ‘html.parser‘) #输出网页信息 #print(soup.prettify()) #with open(‘./read.html‘,‘w‘,encoding=‘utf-8‘) as f: #两个内容是一样的 只是一个是标准缩进格式,另一个不是 #f.write(str(soup.prettify())) #f.write(str(response)) ‘‘‘ 根据爬取网站不同,下面代码也会不一样 解析该网站某一期的所有音乐信息 主要包括: 期刊信息 期刊封面 期刊描述 节目清单 ‘‘‘ #<span class="vol-number rounded">989</span> num = soup.find(‘span‘,class_=‘vol-number‘).get_text() #<span class="vol-title">曙色初动</span> 解析标题 find每次只返回第一个元素 title = soup.find(‘span‘,class_=‘vol-title‘).get_text() ‘‘‘ <div class="vol-cover-wrapper" id="volCoverWrapper"> <img src="http://img-cdn2.luoo.net/pics/vol/554f999074484.jpg!/fwfh/640x452" alt="曙色初动" class="vol-cover"> <a href="http://www.luoo.net/vol/index/739" class="nav-prev" title="后一期" style="display: inline; opacity: 0;"> </a><a href="http://www.luoo.net/vol/index/737" class="nav-next" title="前一期" style="display: inline; opacity: 0;"> </a> </div> 解析对应的图片背景 ‘‘‘ cover = soup.find(‘img‘, class_=‘vol-cover‘).get(‘src‘) ‘‘‘ <div class="vol-desc"> 本期音乐为史诗氛围类音乐专题。<br><br>史诗音乐的美好之处在于能够让人有无限多的宏伟想象。就像这一首首曲子,用岁月沧桑的厚重之声,铿锵有力的撞击人的内心深处,绽放出人世间的悲欢离合与决绝!<br><br>Cover From Meer Sadi </div> 解析描述文本 ‘‘‘ desc = soup.find(‘div‘, class_=‘vol-desc‘).get_text() ‘‘‘ <a href="javascript:;" rel="nofollow" class="trackname btn-play">01. Victory</a> <a href="javascript:;" rel="nofollow" class="trackname btn-play">02. Mythical Hero</a> 解析歌单 find_all返回一个列表 所有元素 ‘‘‘ track_names = soup.find_all(‘a‘, attrs={‘class‘: ‘trackname‘}) track_count = len(track_names) tracks = [] # 12期前的音乐编号1~9是1位(如:1~9),之后的都是2位 1~9会在左边垫0(如:01~09) for track in track_names: _id = str(int(track.text[:2])) if (int(releate_url) < 12) else track.text[:2] _name = fix_characters(track.text[4:]) tracks.append({‘id‘: _id, ‘name‘: _name}) phases = { ‘phase‘: num, # 期刊编号 ‘title‘: title, # 期刊标题 ‘cover‘: cover, # 期刊封面 ‘desc‘: desc, # 期刊描述 ‘track_count‘: track_count, # 节目数 ‘tracks‘: tracks # 节目清单(节目编号,节目名称) } #追加到队列 self.queue.put(phases) if __name__ == ‘__main__‘: luoo_site = ‘http://www.luoo.net/vol/index/‘ spyder_queue = queue.Queue() ## 创建新线程 luoo = UrlSpyder(luoo_site, releate_urls=[‘1372‘,‘1370‘], que=spyder_queue) luoo.setDaemon(True) #开启线程 luoo.start() ‘‘‘ 从队列中取数据,并进行下载 ‘‘‘ count = 1 while True: if spyder_queue.qsize() <= 0: time.sleep(10) pass else: phases = spyder_queue.get() print(phases) #下载图片 download(phases[‘cover‘],‘%d.jpg‘%(count)) count += 1
运行结果如下:
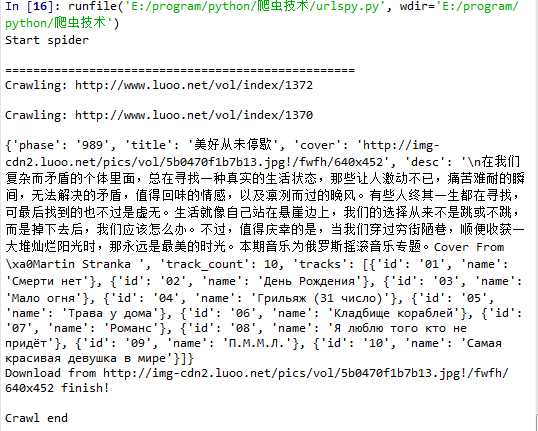

并爬取了如下两种图片:

标签:sele 学习 .com 自动 语句 链接 .exe color 技术
原文地址:https://www.cnblogs.com/zyly/p/9096217.html