标签:失败 github obj 文件 图片 并且 成功 简单的 实现
这是一个最简单的图像识别,将图片加载后直接利用Python的一个识别引擎进行识别
将图片中的数字通过 pytesseract.image_to_string(image)识别后将结果存入到本地的txt文件中
1 #-*-encoding:utf-8-*-
2 import pytesseract
3 from PIL import Image
4
5 class GetImageDate(object):
6 def m(self):
7 image = Image.open(u"a.png")
8 text = pytesseract.image_to_string(image)
9 return text
10
11 def SaveResultToDocument(self):
12 text = self.m()
13 f = open(u"Verification.txt","w")
14 print text
15 f.write(str(text))
16 f.close()
17
18 g = GetImageDate()
19 g.SaveResultToDocument()
具体想要实现上面的代码需要安装两个包和一个引擎
在安装之前需要先安装好Python,pip并配置好环境变量
所有包的安装都是通过pip来安装的,需要在windows PowerShell中进行,并且是在 C:\Python27\Scripts目录下
1.第一个包: pytesseract
pip install pytesseract
若是出现安装错误的情况,安装不了的时候,可以将命令改为 pip.exe install pytesseract来安装
若是将pip修改为pip.exe安装成功后,那么下文的所有pip都需要改为pip.exe
2.第二个包:PIL安装
pip install PIL
若是失败了可以如下修改 pip install PILLOW
3.安装识别引擎tesseract-ocr
https://github.com/tesseract-ocr/tesseract
下载 tesseract-ocr,进行默认安装
安装完成后需要配置环境变量,在系统变量path后增加 tesseract-ocr的安装地址C:\Program Files (x86)\Tesseract-OCR;
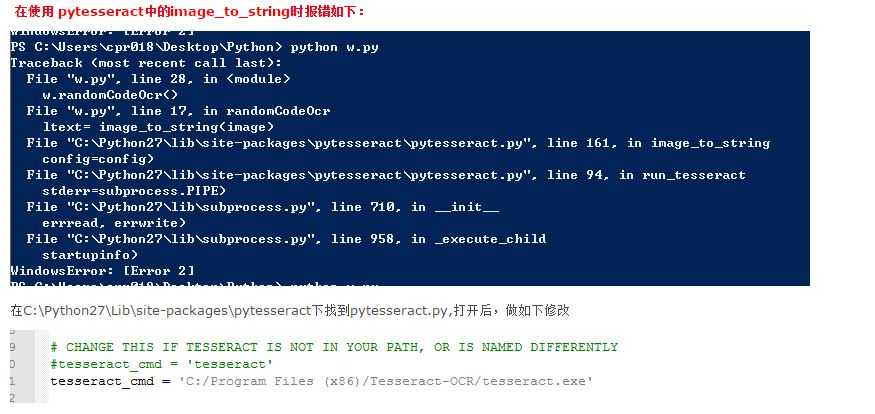
一切都安装完成后运行上述代码,会发现报错,此时需要
至此结束
python 图像识别
标签:失败 github obj 文件 图片 并且 成功 简单的 实现
原文地址:https://www.cnblogs.com/decode1234/p/9096627.html