标签:读取 计算 ext .so 哈哈 篡改 nta 常量 for
抓包:
为什么要抓包:
1、定位问题
2、篡改请求
3、能测试系统的其他的异常
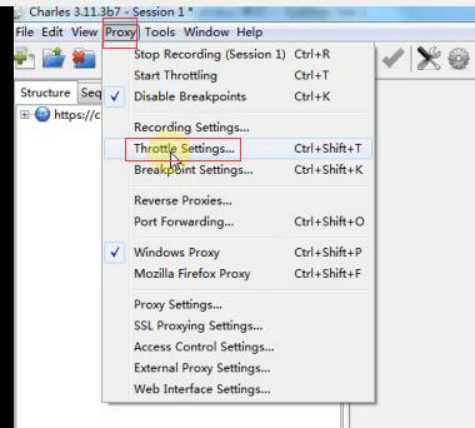
手机抓包charles:
1、打开charles,必须保证手机和电脑是在一个局域网里面
2、手机设置代理,服务器写你电脑的ip,端口号默认是8888
https协议的抓取不到数据,安全协议,需要对应公司自己的证书导入到抓包工具才可以。
模拟弱网测试:可限速的
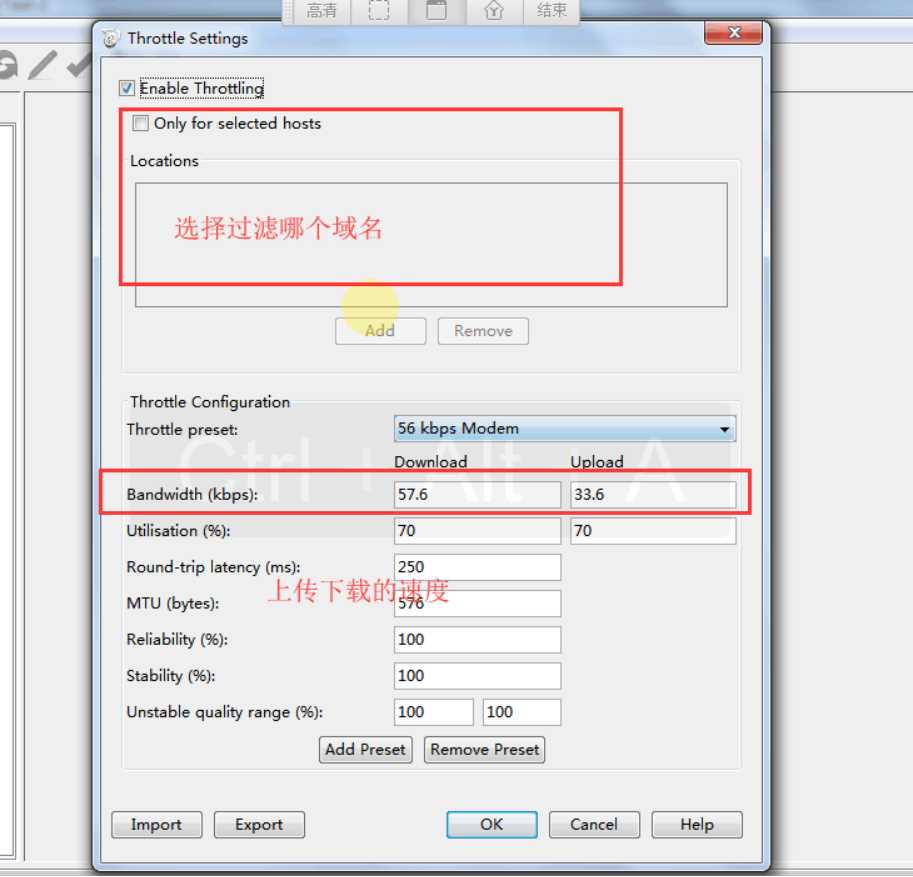
设置端口:
soupui:
1、sopaui新建一个soap项目
2、在wsdl地址这里,填上 wsdl接口的地址
3、左边是请求的数据,右边是返回的数据
python基础:
引号:
在python中不区分单引号和双引号,都可表示一个字符串,单引号与双引号可互相嵌套使用(单引号里面可用双引号,双引号里面可用单引号),但不能交叉使用。
注释:
单行注释:用#号表示 多行注释:用三对引号表示,同样不区分单双引号
eg:‘‘‘XXXX
ddddddd
eeeeeeee‘‘‘或者
"""dddddddddddddddddd
oooooooooo
pppppppppp"""
格式化:
方法一:+拼接
import datetime
today=datetime.datetime.today()#获取今天日期
user=‘aa‘
msg="欢迎"+user+"来到我家!"+"今天日期是"+today
方法二:%占位符(推荐方法,不占内存)
name="zhangsan"
print("hello %s,nice to meet you!" %name)
输出:hello zhangsan,nice to meet you!
age=11
score=86.2656
score=round(score,2)#保四舍五入,留小数点后2位
msg=‘%%你的年龄是%d,你的分数是%.3f‘ %(age,score)#想打印%则要写两个%,两个%则2的倍数为4
print(msg)
占位符%s是字符串 %d是整数 %f是小数(默认小数后6位) %.2f 表示小数后2位小数且自动会四舍五入,注意%后面的点号不要忽略
方法三:
不知道打印的是什么类型可以用%r或者%s
n=100
print( ‘you print is %r‘ %n)
you print is 100
if条件判断:
a=2
b=3
if a>b:
print(‘a max‘)
else:
print(‘b max‘)
python没有像其他语言一样使用{}表示语句体,通过语句的缩进判断语句体,缩进默认为4个空格。python中if语句通过==运算符判断相等,用!=判断不相等。用in和not in表示包含的关系。
hi=‘hello world‘
if ‘hello‘ in hi:
print(‘contain‘)
else:
print(‘nott contain‘)
if语句可以进行布尔类型的判断:
a=true
if a:
print(‘a is true‘)
else:
print(‘a is not true‘)
多重if条件判断:
results=72
if results >=90:
print(‘优秀‘)
elif results >=70:
print(‘良好‘)
elif results >=60:
print(‘及格‘)
else:
print(‘不及格‘)
while循环:while循环,必须有一个计算器来记录循环次数,循环就是在重复执行循环体里的代码
count=0
while count<10:
print(‘打断点‘)
count+=1 #count=count+1
import random #导入random
num=random.randint(1,100)#产生一个随机数
count=0
while count<7:
guess=input(‘请输入你猜的数字:‘)
guess=int(guess)
if guess>num:
print(‘大了‘)
continue
elif guess<num:
print(‘小了‘)
continue #结束本次循环,开始下次循环
else :
print(‘恭喜猜对了‘)
break#立即结束循环
count+=1#count=count+1
else:#循环正常结束后,会执行else
print(‘游戏次数已用尽,请充值‘)
for循环:for循环比while循环使用率更高,它更简单灵活,不需要定义计数器,会自动计数的。
for i in ‘hello world‘:
print(i)
h
e
l
l
o
w
o
r
l
d
若需要进行一定次数的循环,则需要用range()函数。
for i in range(5):
print(i)
0
1
2
3
4
range()函数默认从零开始循环,可设置起始位置和步长,比如打印1-10之间的奇数:
for i in range(1,10,2):
print(i)
1
3
5
7
9
range(start,end[,step]):start表示起始位置,end表示结束位置,step表示步长。在python2中range()是一个生成器,xrange()是一个数组,后者在性能上要优于前者因为不需要一上来就开辟一块很大的内存空间,但它们用法完全相同。而python3中range()与python2中xrange()相同,是一个数组。
数组:(列表)
数组用方括号([])表示,里面每一项用逗号隔开。
age = 18 #int
name =‘小黑,jj,刘欣,xxxx‘ #字符串
score = 98.35 #float python中没有double类型
stus = [ ‘jj‘,‘刘欣‘,‘单宝‘ ]
print( type(stus))
print( stus[0] )
#增
stus.append(‘周凡‘) #在列表末尾增加一个元素
stus.insert(0,‘磊磊‘) #在指定位置添加一个元素
# 删除
stus.pop(2) #删除指定位置的元素
stus.remove(‘磊磊‘) #删除指定的元素
del stus[3] #删除指定位置的元素
#改
stus[1]=‘老王‘ #修改
#查
print(stus[-1])#取值 下标为-1的时候,就取最后一个元素
stus.clear() #清空整个list
stus.append(‘老王‘)
print( stus.count(‘老王‘) )#统计这个元素在list里面出现了几次
count = stus.count(‘老王‘)
print(count)
print( stus.index(‘老王‘) ) #返回这个元素第一次出现的下标,如果这个元素在list里面不存在的话,会报错
print(stus)
stus.reverse() #反转
print(stus)
stus2 = [‘高峰‘,‘小王‘,‘张众一‘]
stus.extend(stus2) #把后面list里面的值,加入到第一个list里面
print(stus)
stu3 = stus+stus2 #合并两个list
print(stu3)
nums = [1,3,8,5,23,24,3,3462,12]
nums.sort(reverse=True) #排序,默认是升序
print(nums)
n = [1,2,3] #1维数组
n2= [ [1,2,3] ,[‘hehe‘] ] #二维数组
my = [[1,2,3,4,5,6],[‘name‘,‘age‘,‘sex‘,‘哈哈‘,[‘小明‘,‘小黑‘,‘小白‘]],890] #3维数组
print(my[1][4][0])
my[1][4].append(‘小紫‘)
my[1][2]=‘性别‘
print(my)
print( len(my) ) #看变量的元素个数,长度
#多维数组
username = input(‘user:‘)
count = stus.count(username)
# print(stus)
# if count>0:
# print(‘该用户已经存在‘)
if username not in stus:
print(‘不存在‘)
其他:
a=11
print(type(a))#判断常量类型
类型强制转换:
name=input(‘请输入姓名:‘)
age=input(‘请输入年龄:‘)#input输入的都是字符串类型
age=int(age) 强制转化为整数
a=11
a=str(a)强制转化为字符串
score = 98.52699
socre = round(score,2) #四舍五入保留小数点后2位
input:python2中input()要求用户输入的字符串必须加引号,为避免读取非法字符串类型发生一些危险行为,不得不使用raw_input()代替input().
快速复制一行代码:ctr+D
Python2代码有中文会报错:在代码第一行写入下面这行代码即可。
# -*- coding: utf-8 -*
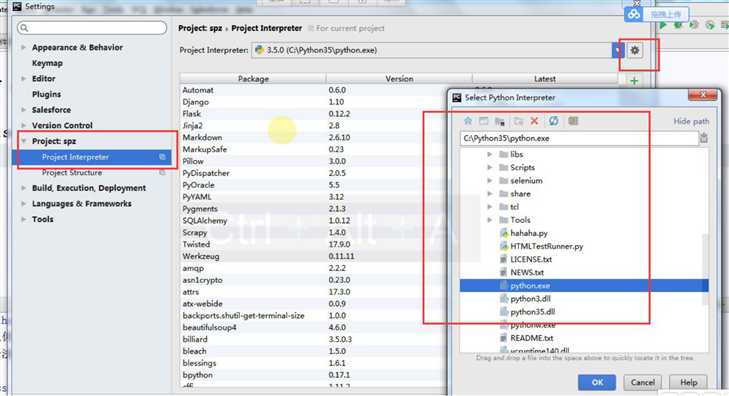
设置python版本类型:
标签:读取 计算 ext .so 哈哈 篡改 nta 常量 for
原文地址:https://www.cnblogs.com/rzln/p/9107638.html