标签:ip核 AC 直接 超出 信息 文件的 错误 alt logs
国密商用算法是指国密SM系列算法,包括基于椭圆曲线的非对称公钥密码SM2算法、密码杂凑SM3算法、分组密码SM4算法,还有只以IP核形式提供的非公开算法流程的对称密码SM1算法等。
第1节 SM2非对称密码算法原理
国密SM2算法是商用的ECC椭圆曲线公钥密码算法,其具有公钥加密、密钥交换以及数字签名的功能。椭圆曲线参数并没有给出推荐的曲线,曲线参数的产生需要利用一定的算法产生。但在实际使用中,国密局推荐使用素数域256 位椭圆曲线,其曲线方程为y^2= x^3+ax+b。参数如下:
其中p是大于3的一个大素数,n是基点G的阶,Gx、Gy 分别是基点G的x与y值,a、b是随圆曲线方程y^2= x^3+ax+b的系数。
第2节 SM3密码杂凑算法原理
杂凑密码算法又称为哈希密码算法或散列密码算法,其可以将任意长度的字符串作为算法输入,并输出固定长度的字符串。当算法的结构设计足够精妙复杂时,基本上可以做到对于任意输入都有唯一确定的输出与之对应,相反该输出也可以唯一标识该输入。
一般可以从两个角度对杂凑算法安全性能进行评估:
1.计算不可逆性:即给定一输入消息A的杂凑值H(A),要得到原消息A在计算上是不可行的; 2.抗碰撞性:即给定一消息B,找到消息B?使H(B)=H(B‘)在计算上是困难的。网络安全领域中,较为常用的杂凑算法主要有MD5、SHA-1以及SHA-256等,都具有良好的计算不可逆性以及抗碰撞性。但在2004年,由王小云教授提出的杂凑碰撞算法,极大地降低了对MD5以及SHA-1算法实施碰撞攻击的时间复杂度。
经过多年的研究,由王小云教授主导设计的SM3杂凑密码算法正式推出,该算法可以用于各类密码应用中的数字签名和验证、消息认证码的生成与验证以及随机数的生成,可满足多种密码应用的安全需求。
国密SM3商用密码杂凑算法应用于数字签名和验证、消息认证码的生成与验证以及随机数的生成,可满足多种密码应用的安全需求。对于长度为l(l<264)比特的信息,SM3杂凑算法经过填充和迭代压缩,生成杂凑值,其杂凑值长度为256比特(32字节),其安全性与SHA256相当。
第3节 SM4分组密码算法原理
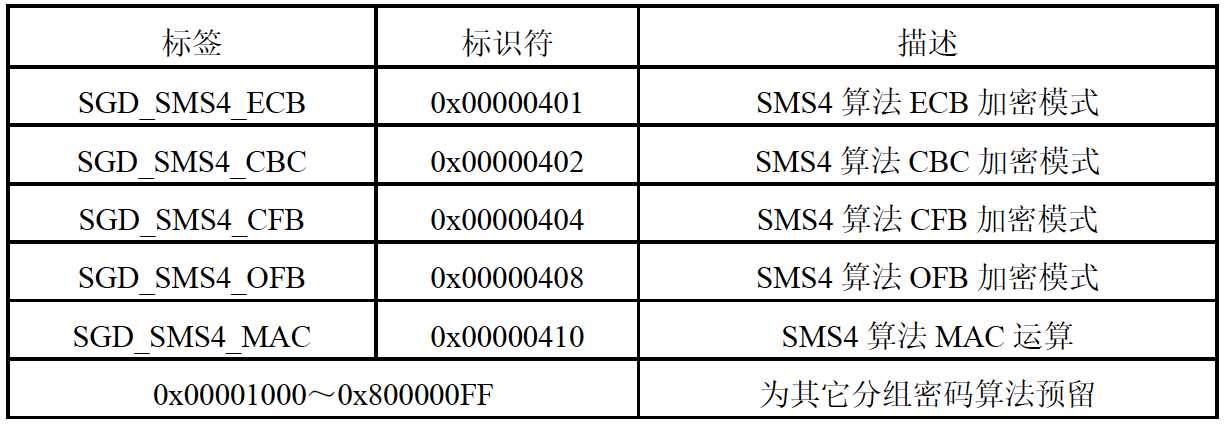
国密SM4算法是一个对称分组密码算法,该算法的分组长度为16字节,密钥长度也为16字节。加密算法与密钥扩展算法都采用32轮非线性迭代过程,解密算法与加密算法的过程相同,只是轮密钥的使用顺序相反,解密轮密钥是加密轮密钥的逆序。SM4算法支持的四种加密模式如下表所示:
SM4 分组算法4种模式及安全MAC的算法标识如下表所示:
第4节 PYTHON实现
python实现代码已上传码云。
4.1 SM2测试截图
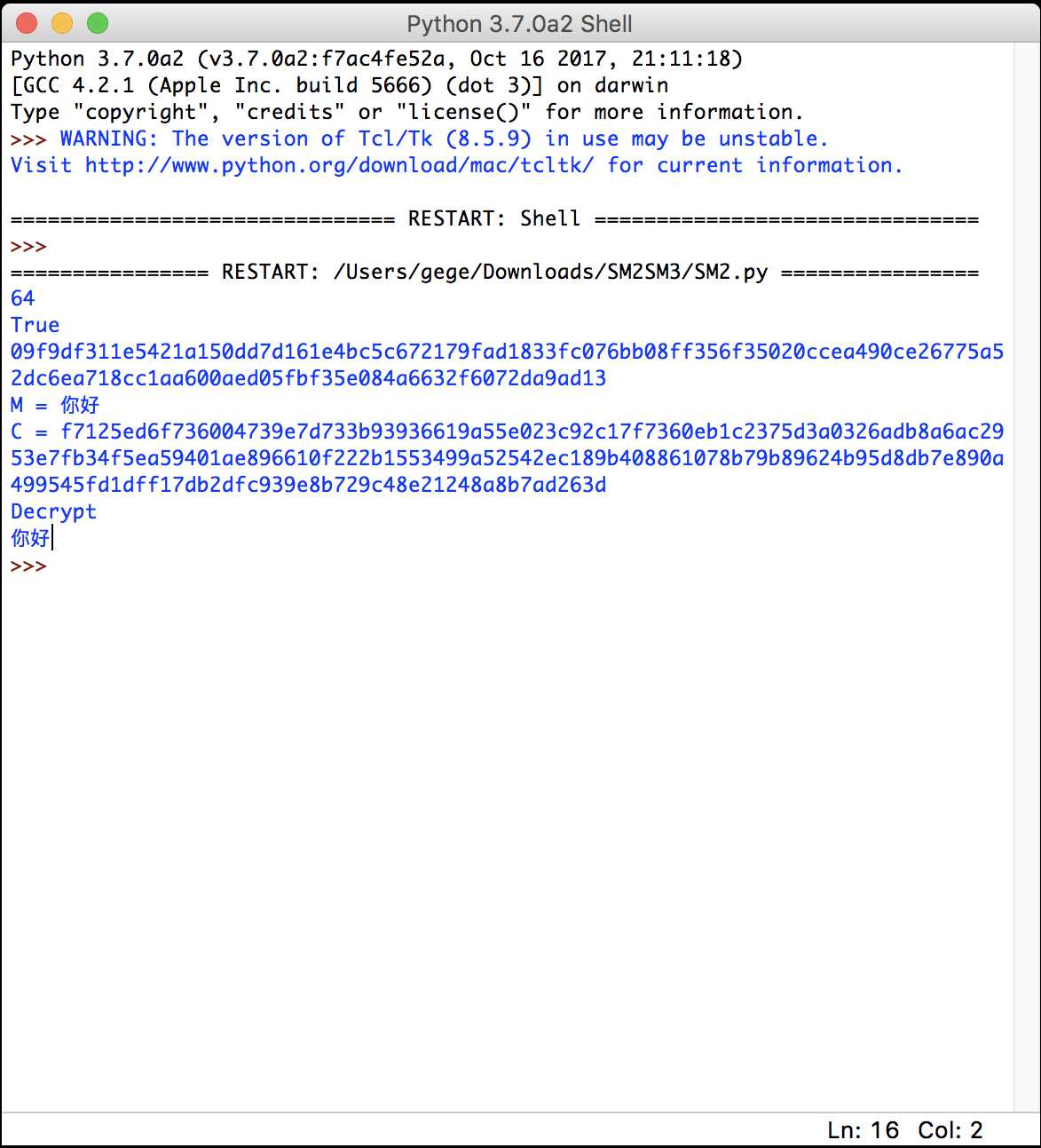
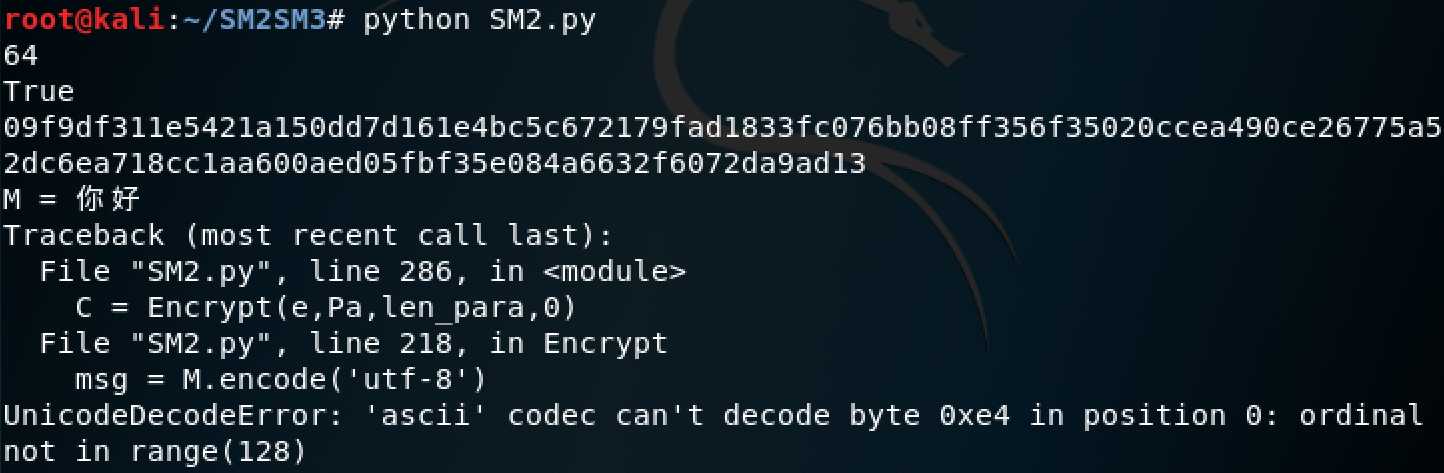
python3实现的国密SM2+SM3,SM3包括KDF功能,可配合SM2加解密(SM2调用了SM3模块)。SM2实现了各种素域下的签名、验签和加解密功能。
截图体现了SM2对“你好”的加解密过程。4.2 SM3测试截图
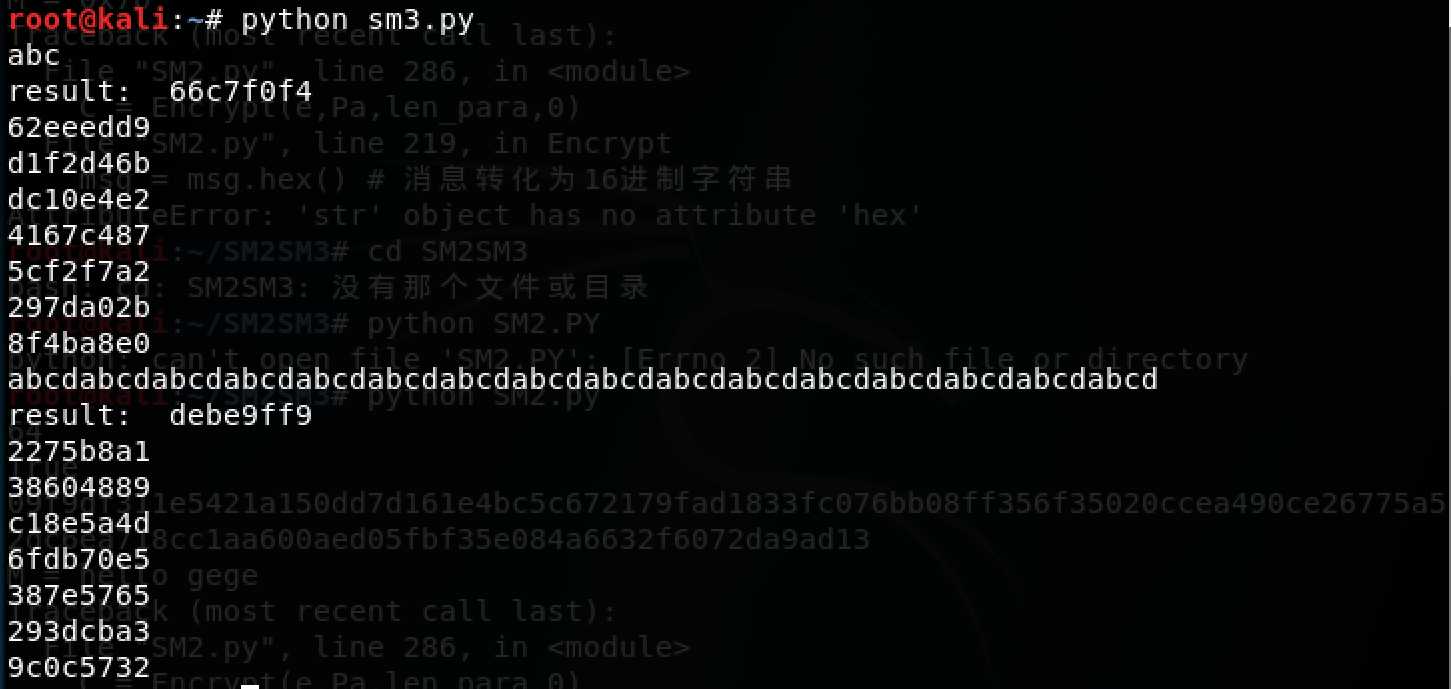
python编写的SM3密码杂凑算法代码。
对字符串abc、 abcd*16进行测试,结果如图:
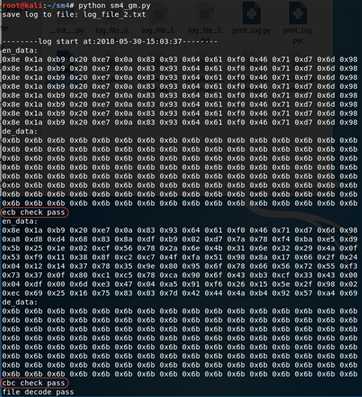
4.3 SM4测试截图
python实现的国产加密sm4算法。
测试了ecb和cbc两种模式:
第5节 遇到的问题与解决过程
5.1 问题一
python中出现Non-ASCII character ‘\xe7‘ in file sm2.py on line 6, but no encoding declare的错误。可按照错误建议网址查看http://www.python.org/peps/pep-0263.html,发现是因为Python在默认状态下不支持源文件中的编码所致。解决方案有如下三种:
1)在文件头部添加如下注释码: # coding=<encoding name> 例如,可添加# coding=utf-8 2)在文件头部添加如下两行注释码: #!/usr/bin/python # -*- coding: <encoding name> -*- 例如,可添加# -*- coding: utf-8 -*- 3)在文件头部添加如下两行注释码: #!/usr/bin/python # vim: set fileencoding=<encoding name> : 例如,可添加# vim: set fileencoding=utf-8 :5.2 问题二
UnicodeDecodeError: ‘ascii‘ codec can‘t decode byte 0xe9 in position 0: ordinal not in range(128) 产生原因:因为默认情况下,Python采用的是ascii编码方式,而Python在进行编码方式之间的转换时,会将unicode 作为“中间编码”,但unicode最大只有128那么长,所以这里当尝试将ascii编码字符串转换成"中间编码" unicode时由于超出了其范围,就报出了如上错误。
有的解决办法参见cnblogs、csdn。但具体我是换了python3.7版本直接运行通过的。
5.3 问题三
python模块以及导入出现ImportError: No module named ‘xxx‘问题。
具体参见mamicode
python中,每个py文件被称之为模块,每个具有_init_.py文件的目录被称为包。只要模块或者包所在的目录在sys.path中,就可以使用import 模块或import包来使用。
如果你要使用的模块(py文件)和当前模块在同一目录,只要import相应的文件名就好,比如在a.py中使用b.py:
import b
2017-2018-2 20179204《网络攻防实践》第十三周学习总结 python实现国密算法
标签:ip核 AC 直接 超出 信息 文件的 错误 alt logs
原文地址:https://www.cnblogs.com/20179204gege/p/9111064.html