标签:blog http io os 使用 ar strong for 数据
转自:http://blog.163.com/mig3719@126/blog/static/285720652010950825538/
6. 从关系角度理解SQL
6.1. 关系和表
众所周知,我们目前所用的数据库,通常都是关系数据库。关系自然在其中处于关键位置。初学数据库原理的人可能会很困惑关系和表是什么联系,如果没有清楚的理解,很可能会认为关系这个概念没有实际意义,只会引起混淆。
其实这两组概念只是由于理论界与技术界的着重点不同。前者需要用一个专业的、没有歧义的概念来进行理论探讨,后者则希望在实际应用中能够使用一个直观的、容易理解的词汇。通常情况下,可以认为关系和表是一回事。
就定义来说:关系是元组(即表的记录,或行)的集合。此外,关系还有以下特征:
- 关系含有一组属性(即表的字段,或列),含有N个属性的关系可称为N元关系。
- 一个关系的元组含有与关系相同的属性,N元关系的元组都是N元组,一个元组中对应每个属性有一个值。
- 一个属性的域(即字段的数据类型,但域的要求更严格,详见下文“数据类型”),即该属性所有可能的值的集合。
从 这里可以看出关系和表的区别:关系作为一种集合,不会包含重复元组;而表则可以包含重复记录。这是SQL面对的诸多指责之一,但有其技术合理性。这里的区 别在理解上影响不大,不妨把表理解为“可能(但通常不应该)重复的集合”。注意到这点区别,以下我们便可以对关系和表不加区别的使用了。
另外,这里的关系和表,指的是所有表值的东西,包含物理表、虚拟表(视图)、派生表(一个用在FROM子句的子查询)、表变量、表值函数、等等。它们在物理上有区别,但在逻辑上是等价的。
6.2. 关系模型
数 据库建模(即表结构设计)的过程,是根据现实世界的业务需求,设计一个表示和存储业务数据的关系数据模型。在设计过程中可以借助E-R模型来简化问题,因 为E-R模型可以更直观地对应于现实世界,也可以很容易地转化为关系模型。对于熟练的设计者,可以省略E-R模型,直接构建关系模型。
而关系模型在关系数据库中基本上可以直接表示,所以关系模型与物理模型差别不大。物理模型通常只是根据需要添加必要的索引,或是将概念上的表在物理上映射为分区视图或分区表。
以上几个模型的关系见下图: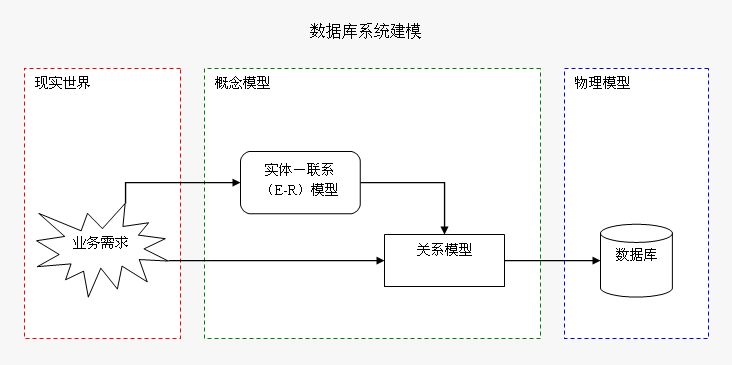
简单总结一下关系模型设计中的两个要点:
1. 完整性约束(Integrity constraint):
完整性约束保证数据的一致性(符合基本条件),包含以下3种类型:
- 实体完整性(主键约束):一个表的主键不能为空。
- 参照完整性(外键约束):一个表的外键必须存在于所参照的表中。
- 自定义完整性(CHECK约束,UNIQUE约束):即表中的数据不能违反约束定义的条件(不能使CHECK的表达式为False,不能使UNIQUE约束的字段或字段组合出现重复值)。
完整性约束定义了系统概念模型的边界,很大程度上防止了脏数据进入系统,这是非常重要的,因为脏数据往往比没有数据还要讨厌(这与“错误的观点胜过没有观点”恰恰相反)。
在 设计表结构时,外键、CHECK、UNIQUE约束或许可以适当省略(出于运行性能和开发效率的考虑,并且相信表数据只有统一存储过程修改,不会出现脏数 据),但主键通常是一定需要的。主键不仅意味着可以高效查询(因为目前DBMS的主键通常都是通过B+树聚集索引实现的),更重要的是清楚地说明了表中数 据的唯一标识是什么。(目前我只发现一种不需要主键的情况:日志表——同一时刻可能有多笔记录,所以datetime不能作为主键;而一个递增的 LogID也没有太大实际意义,参看关于聚集索引选择方案的疑问一帖。)
关于主键的选择方案,详见一个基础问题一帖。
给 我看表的数据样本,以及(可能)过时的数据字典和程序文档,我仍然迷惑不解。如果给我看完整的表的定义(要包括各种完整性约束,特别是主键),通常就不需 要查看表中的数据样本了,甚至连文档也可以省去。(这两句话借鉴了Brooks在《人月神话》一书中的话。参见《UNIX编程艺术》1.6节脚注。)
2. 范式(Normal Form, NF):
范式是一组关系(表)设计的原则,通过避免冗余防止出现数据的更新异常(即DRY原则的体现)。在实践上常用的是以下3个层次的范式:
- 1NF:表中的字段都是原子的。
- 2NF:表中的所有字段都可以由主键唯一决定(函数依赖)。
- 3NF:除完整主键以外,其它字段(包括部分主键)之间不存在决定关系(函数依赖)。
首 先说明一下1NF的“原子的”。这个“原子的”是指业务需求不需要对这个值进行拆分(没有前提条件,“拆分”一词是有多种解释的,如字符串可以拆分成字 符,整数可以拆分成二进制的位串或素因子的乘积)。例如,城区、街道、门牌号是地址的三部分,如果地址只是作为一个记录,不需要更细粒度的处理,则可以将 三部分存在一个字段;如果需要根据城区进行查询和分组统计,则至少需要把城区作为一个单独的字段。所以,一个字段是不是“原子的”必须根据业务需求这个条 件来定义。实践中业务需求是会变化的,因而系统设计还需要一定的前瞻性。目前一个原子的字段可能随着需求变化而不再是原子的。
范式给出了一组表应该怎样设计的原则,但没有说明如何把表设计成这样。数据库理论上的关系范式分解过于抽象,以下是一点实用性的思路:
- 1NF:让表中的每个字段都不需要拆分处理(至少不需要太复杂的拆分处理)。如姓名的结构很简单,通常不需要设计成姓和名两个字段,但如果是一个国际化的系统,不同文化中姓名的结构可以不同,这时则最好把LastName和FirstName分开存放,比如Facebook、Twitter等网站的设计。
- 2NF:给表定义主键。参看上文关于实体完整性的讨论。
- 3NF:不要在同一个表中存放相关数据或派生数据,只存放主要数据,其它数据通过联接查询或计算获得。如不要在员工表中同时存放部门ID和部门名称(相关数据)或同时存放出生年月和年龄(派生数据),其中部门ID或出生年月是主要数据,部门名称可以通过联接查询获得,年龄可以通过计算获得。
有 些情况下出于结构的直观或查询性能的考虑,可能会需要反范式的设计。如在一个字符串字段中存放逗号分隔的多个值(形如‘1,2,3,5,8‘,违反 1NF),或是在一个表中同时存放相关数据或派生数据来避免联接或计算开销(比如同时存放部门ID和部门信息来避免联接部门表,或同时存放员工各项薪酬福 利和总薪资来避免复杂的薪资计算,违反3NF)。反范式的设计会带来复杂的查询处理或冗余,更好的方案是基本数据用符合范式的表存储,通过统一的过程来计 算和刷新缓冲表来提高查询时的性能,参看《程序员修炼之道》第7节关于DRY原则的讨论。
6.3. 关系运算
表的查询,与关系代数(Relational Algebra)定义的关系运算是等价的。理解关系运算,或许可以简化对查询的认识。
常用的基本关系运算只有4类(够简单吧):
1. 基本的集合运算(双目运算)
关系是元组的集合,所以关系也支持基本的集合运算:
- 并(union):对应SQL关键字UNION
- 交(intersection):对应SQL关键字INTERSECT
- 差(difference):对应SQL关键字EXCEPT
不同的是,关系的集合运算,要求参与运算的两个关系必须含有相同属性集(属性的个数和类型都一样)。
由于表允许重复记录,在SQL中以上三种操作还可以是UNION ALL/INTERSECT ALL/EXCEPT ALL的形式,结果不去除重复记录。
2. 提取关系的一部分的运算(单目运算)
- 选择(selection):根据条件过滤出指定的元组(行),对应SQL查询的WHERE子句
- 投影(projection):根据列表过滤出指定的属性(列),对应SQL查询的SELECT子句
由于表允许重复记录,关系的投影运算事实上等价于SELECT DISTINCT的效果。而SELECT的默认效果是不去除重复记录。
3. 两个关系的联接(双目运算)
- 笛卡尔积(Cartesian product):对应SQL关键字CROSS JOIN(与FROM后的多个表直接用逗号分隔效果相同)
- 内联接(Inner Join):对应SQL关键字INNER JOIN
- 外联接(Outer Join):对应SQL关键字{LEFT | RIGHT | FULL} OUTER JOIN
4. 聚合运算(单目运算)
根据指定属性(列)分组,同时可以使用聚合函数。对应SQL查询的GROUP BY子句。
以上4类关系运算,不管是单目运算还是双目运算,其结果依然是一个关系,因而可以继续进行运算。
通常情况下的SQL查询,除一些特殊的语言特性外(如TOP、排序函数等),主要的查询逻辑都是这4类关系运算的组合。
6.4. 数据查询
1. 查询的逻辑处理过程
以T-SQL为例,一个查询(完整SELECT语句)的逻辑处理过程如下(其中括号中的数字表示处理顺序):
[code=sql]
(8) SELECT (9) DISTINCT (11) <TOP_specification> <select_list>
(1) FROM <left_table>
(3) <join_type> JOIN <right_table>
(2) ON <join_condition>
(4) WHERE <where_condition>
(5) GROUP BY <group_by_list> (6) WITH {CUBE | ROLLUP}
(7) HAVING <having_condition>
(10) ORDER BY <order_by_list>
[/code]
说明:
+ 有些子句是可选的。比如JOIN可能出现0到多次,GROUP BY和HAVING可能出现0到1次。
+ 从以上顺序可以看出,为何在WHERE子句不能使用SELECT的计算结果,但在ORDER BY子句却可以。
+ 查询的逻辑处理过程与物理处理过程可能并不相同。但对于SQL的学习来说,先理解逻辑处理过程是必须的。先要知道怎样计算出正确的结果,才谈得上怎样更高效地计算出正确的结果。
该内容详见《Microsoft SQL Server 2005技术内幕:T-SQL查询》第1章。
2. 查询条件
在SQL Server联机丛书中,查询条件的BNF语法图如下:
[code=sql]
Search Condition
< search_condition > ::=
{ [ NOT ] <predicate> | ( <search_condition> ) }
[ { AND | OR } [ NOT ] { <predicate> | ( <search_condition> ) } ]
[ ,...n ]
<predicate> ::=
{ expression { = | < > | ! = | > | > = | ! > | < | < = | ! < } expression
| string_expression [ NOT ] LIKE string_expression [ ESCAPE ‘escape_character‘ ]
| expression [ NOT ] BETWEEN expression AND expression
| expression IS [ NOT ] NULL
| expression [ NOT ] IN ( subquery | expression [ ,...n ] )
| expression { = | < > | ! = | > | > = | ! > | < | < = | ! < } { ALL | SOME | ANY} ( subquery )
| EXISTS ( subquery ) }
| CONTAINS ( { column | * } , ‘ < contains_search_condition >‘ )
| FREETEXT ( { column | * } , ‘freetext_string‘ )
[/code]
其中:predicate为断言,expression为标量表达式,subquery为子查询。查询语句返回使查询条件为True的结果。
3. 子查询
一个查询如果作为一个语句的一部分,则称为子查询。
a. 按结果分类:
- scalar subquery:如果查询结果是标量值,即只有一行一列,则为标量子查询(标量表达式)。
- table-valued subquery:反之则是表值子查询(表值表达式)。
b. 按查询是否涉及外层表分类:
- self-contained subquery:不涉及外层表的子查询是不相关子查询,如SELECT a.* FROM a WHERE a.id IN (SELECT b.id FROM b)。
- correlated subquery:反之则是相关子查询,如SELECT a.* FROM a WHERE EXISTS (SELECT * FROM b WHERE b.id = a.id)。
c. 按子查询所在的位置分类:
- In search_condition:在查询条件中的子查询,比如上文语法图中的所有subquery。
- In FROM clause:在FROM子句中的子查询,又称派生表,如SELECT * FROM (SELECT * FROM a) tmp,派生表一定要指定表别名。(SQL Server 2005之后支持Common Table Expressions,可视为派生表的变形,但可以在一个查询中多次使用,而且支持Recursive CTE这种高级功能,详见联机丛书。)
- In SELECT clause:在SELECT子句中的子查询,如SELECT d.DepID, ManagerName = (SELECT e.EmpName FROM Employee e WHERE e.EmpID = d.ManagerID) FROM Department d WHERE ...,这种子查询性能较差,通常可以用JOIN代替。如果可能,尽量避免使用SELECT子句中的子查询。
6.5. 数据修改
在SQL Server中,修改数据(增、删、改)的语句支持以下格式:
1. 增(INSERT)
[code=sql]
INSERT INTO <table>( <column_list>) VALUES( <values>)
INSERT INTO <table>( <column_list>) SELECT <values> FROM ...
INSERT INTO <table>( <column_list>) EXEC <usp>
SELECT <values> INTO <table> FROM ...
[/code]
以上4个语句:
第1个是SQL标准的插入语句(SQL Server 2008还支持在VALUES子句指定多个元组);
第2个和第3个是T-SQL扩展的插入语句,但要求SELECT语句和EXEC存储过程的结果集与目标表的指定插入列字段个数一致且数据类型一一对应(或可以隐式转换);
第4个不是插入语句,而是根据SELECT语句的结果集创建一个表并将结果数据插入其中,注意与第2个语句的区别。
2. 删(DELETE)
[code=sql]
DELETE FROM <table> [WHERE <where_condition>] !!!
DELETE FROM <table> FROM <table> JOIN <another_table> ON <join_condition> WHERE <where_condition>
TRUNCATE TABLE <table>
[/code]
以上3个语句:
第1个是SQL标准的删除语句(WHERE子句省略的结果是删除全部数据,注意!);
第2个是T-SQL扩展的删除语句,效果是将符合联接查询条件的目标表数据删除(将DELETE FROM <table>改为SELECT DISTINCT <table>.*可以看到删除哪些数据);
第3个实际上是DDL而不是DML,需要的权限和运行条件都与DELETE不同,但效果却是清除表中所有数据,而且比DELETE高效。
3. 改(UPDATE)
[code=sql]
UPDATE <table> SET <col> = <new_value> [WHERE <where_condition>] !!!
UPDATE <table> SET <col> = <new_value> FROM <table> JOIN <another_table> ON <join_condition> WHERE <where_condition>
[/code]
以上2个语句:
第1个是SQL标准的更新语句(WHERE子句省略的结果是更新全部数据,注意!);
第 2个是T-SQL扩展的更新语句,效果是将符合联接查询条件的目标表数据更新为指定结果(将UPDATE <table> SET <col> = <new_value>改为SELECT <table>.<col>, <new_value>可以看到把哪些数据更新为哪些新值,其中<new_value>可以是联接查询的计算值,但如果联接查询 结果使得目标表的<col>和新值<new_value>成为一对多的关系,则<col>会更新为哪 个<new_value>是不确定的,这种情况可能导致意想不到的bug)。
该内容详见《Microsoft SQL Server 2005技术内幕:T-SQL查询》第8章。
6.6. 表的逻辑含义
很多使用数据库的人,不了解数据库原理,不能从逻辑上理解表的含义,从而只能把表看作一种数据结构,看作一种类似二维数组的东西,于是写出低效的循环语句就不难理解了,数据一致性更是难以保证。
可以从以下两个层面来理解表:
1. 一个表是一类事物(物件object和事实fact的统称)的集合,其中表的每行记录表示一个该类事物,主键是一个事物的唯一标识。
如:学生表(#学号,姓名,专业,……)是学生(物件)的集合,一个学号可以唯一标识一个学生;学生选课表(#学号,#课程ID,选课时间)是学生选课(事实)的集合,联合主键学号和课程ID可以唯一标识某个学生选了某门课的事实。
数据库建模就是根据业务需求设计一组表,用来表示业务系统中的所有事物。
2. 一个表的表结构定义了一个谓词,表中的每行记录都是对该谓词的一个真值量化。由于量化后的谓词是一个命题,所以,一个表是一组真命题的集合。
(关于谓词和量化的概念,可参看《离散数学及其应用(第5版)》一书中关于数据逻辑的部分。)
如: 学生选课表(#学号,#课程ID,选课时间)定义了这样一个谓词——“学生{#学号},在{选课时间},选了课程{#课程ID}。”,其中{}中的部分是 一个变量。谓词不是命题,只有对其量化(或称实例化)之后才是命题。该表的一行记录(‘S001‘,‘C0001‘,‘2010-08-24 17:16:58‘)表示一个真值量化,量化后的命题是“学生S001,在2010-08-24 17:16:58,选了课程C0001。”。
一个数据库系统包含了很多表,每个表是一组真命题的集合,所有这些真命题则表示了系统中可信的知识。
设计一个表,就是设计一个谓词。只要表结构文档把这个谓词的含义说明清楚了,则表中记录的含义也自然清楚了;反之,如果一个表的谓词存在模糊或歧义,则表中的记录也是没有意义的。
从这个角度理解完整性约束:
- 实体完整性(主键约束):如果一个表包含了完全相同的两条记录,则把一个真命题重复一遍并不能增加知识;如果一个表的两条不同记录有着相同主键,则说明这两个命题是冲突的。实体完整性保证了每个命题的唯一和无冲突。
- 参照完整性(外键约束):参照完整性保证了每个命题涉及的事物都是有意义的(在该事物的表中有定义)。
- 域完整性(CHECK约束):域完整性保证每个命题都是一致的(不违反CHECK约束)。“每个命题都是一致的”是“每个命题都是正确的”的必要非充分条件,所以约束只是一种最小保证。
Trackback : http://topic.csdn.net/u/20100826/18/ba72991f-f961-4c18-8d9b-f234c87a609d.html
标签:blog http io os 使用 ar strong for 数据
原文地址:http://www.cnblogs.com/kira2will/p/3997363.html