标签:tesseract 驱动 添加 通过 浏览器 配置 tar dig ocr
一、安装python3
下载安装

二、安装请求库
1、安装requests
python的第三方库
pip3 install requests

2、安装selenium
自动化测试工具,可以驱动浏览器,对应JS渲染的页面,非常有效
pip3 install selenium
不指定版本默认安装最新

3、安装ChromeDriver
使用selenium,需要配合浏览器,这是Chrome浏览器的驱动
下载地址:
https://npm.taobao.org/mirrors/chromedriver/
注意跟浏览器版本对应匹配
下载解压后,将文件配置环境变量(可以直接放到python的scripis目录)
4、安装GeckoDriver
FireFox浏览器的驱动
下载地址:
https://github.com/mozilla/geckodriver/releases
注意跟浏览器版本对应匹配
下载解压后,将文件配置环境变量(可以直接放到python的scripis目录)
5、安装PhantomJS
无界面的可脚本编程的WebKit浏览器引擎
下载地址:
http://phantomjs.org/download.html
解压后同上驱动文件一样配置环境变量
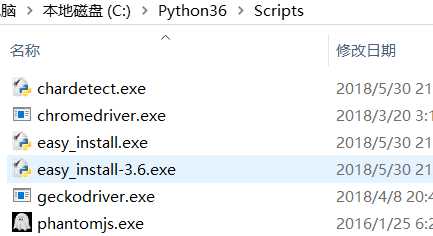
安装成功

6、安装aiohttp
requests是一个阻塞式HTTP请求库,发出请求后程序会一直等待服务器响应
aiohttp是一个异步Web服务的库,python3.5开始加入async和await关键字,使得回调更直观和人性化
pip3 install aiohttp
此外推荐安装另外两个库:字符编码检测库:cchardet;加速DNS的解析库:aiodns
pip3 install cchardet aiodns
三、解析库的安装
1、安装lxml
python的一个解析库,支持HTML、XML的解析,支持XPath解析方式,解析效率很高
pip3 install lxml
2、安装Beautiful Soup
python的一个HTML、XML的解析库,用它可以方便的从网页中提取数据,拥有强大的API和多样的解析方式
pip3 install beautifulsoup4
3、安装pyquery
同样是一个强大的网页解析工具,提供了和jQuery类似的语法来解析HTML文档,支持CSS选择器
pip3 install pyquery
4、安装tesserocr
OCR:光学字符识别,通过扫描字符,然后通过其形状将其翻译成电子文本
tesserocr是python的一个OCR识别库,其实是对tesseract的一层python API封装,所以要先安装tesseract
下载地址
http://digi.bib.uni-mannheim.de/tesseract

不带dev的是稳定版本
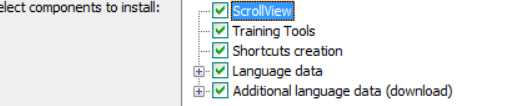
勾选add选项,安装OCR语言包,可识别多国语言
将目录:(D:\Tesseract-OCR)添加环境变量

pip3 install tesserocr pillow
报错

解决:
第一步下载 simonflueckiger/tesserocr-windows_build
对应自己的PC和python下载

cd到该文件目录,执行pip
pip3 install tesserocr-2.2.2-cp35-cp35m-win_amd64.whl

这样tesserocr就安装成了

命令测试

python代码测试
出错
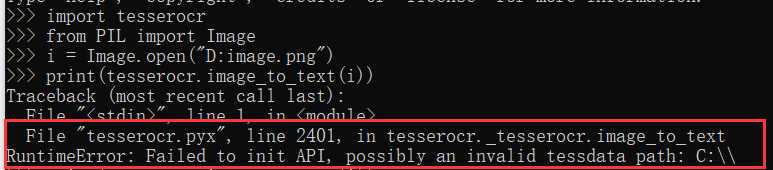
解决:
将tessdata文件夹复制到python的安装目录
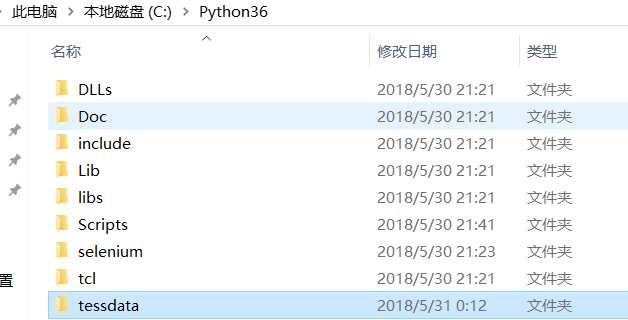
再次执行

直接调用file_to_text()

标签:tesseract 驱动 添加 通过 浏览器 配置 tar dig ocr
原文地址:https://www.cnblogs.com/Mr-chenshuai/p/9114469.html