标签:esc div subject 字段 要求 microsoft 相关 red www
本文访问的数据库是基于存有RDF三元组的开源数据库Localyago修改的库,其中只有一个表,表中有五个属性:主语subject、谓语predict、宾语object、主语的编号subid,宾语的编号objid。每条记录由(subject,predict,object,subid,objid)组成。其中当宾语为字符型而不是实体时(比如“2011”),编号默认为0。有以下数据表:
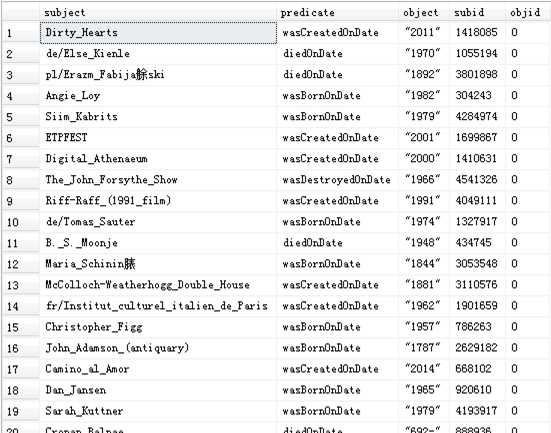
select subject, subid, count(subject) as subprenum from [Localyago].[dbo].[yago] group by subject,subid order by subprenum DESC;
group by实现分组统计,这里按subject分类,由于我们在select的时候选择了subject和subid,而select中的字段要么包含在group by语句里,要么被包含在聚合函数里,所以我们在这里的group by中也要写入subid,不然会报错
order by 是排序,默认从小到大输出,加上DESC就变成倒序、从大到小输出
得到如下结果:
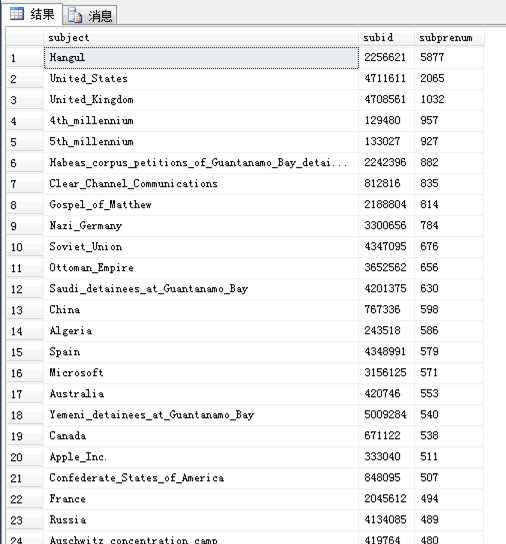
2. 将查询结果的临时表按subprenum倒序存入新的表中,便于存储和查询
最基本的方式:
如果新表不存在
select * into 新表 from 旧表
如果新表不存在
insert into 新表 select * from 旧表
从而有:
select subject, subid, count(subject) as subprenum into Localyago.dbo.subpre from [Localyago].[dbo].[yago] group by subject,subid; order by subprenum;
然后发现虽然我们上一步查询的结果是有序的,但运行这个之后生成的新表,并没有按照subprenum排序,顺序是乱的。
检索之后发现这是由于SQL Server自身的局限,如果有特殊需要,要求临时表里面的数据有序,则可以通过【创建聚集索引】来解决这个问题。具体请参考博文:https://www.cnblogs.com/kerrycode/p/5172333.html
从而改进代码如下:
select subject, subid, count(subject) as subprenum into Localyago.dbo.subpre from [Localyago].[dbo].[yago] where 1=0 group by subject,subid; create clustered index inx_subpre on Localyago.dbo.subpre(subprenum DESC);--创建聚集索引,按subprenum倒序排序 insert into Localyago.dbo.subpre select subject, subid, count(subject) as subprenum from [Localyago].[dbo].[yago] where subid !=0 group by subject,subid order by subprenum;
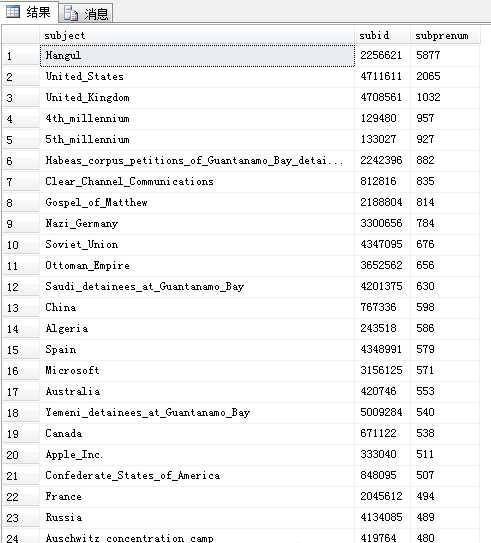
这样运行之后得到的新表subpre里的记录就是按照subprenum倒序排序了
如下:
【SQL Server 2012】按倒序存储“分组统计”结果的临时表到新建表
标签:esc div subject 字段 要求 microsoft 相关 red www
原文地址:https://www.cnblogs.com/a-present/p/9128054.html