标签:soup file 信息 parse tag 字符 结构 log 判断
安装:beautifulsoup4
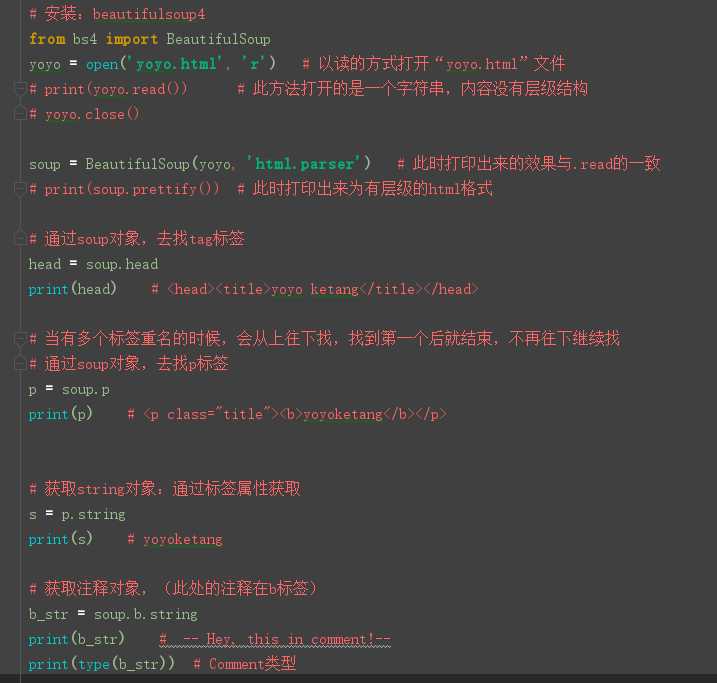
from
bs4 import BeautifulSoup
yoyo = open(‘yoyo.html‘, ‘r‘) # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()
soup
= BeautifulSoup(yoyo, ‘html.parser‘) # 此时打印出来的效果与.read的一致
# print(soup.prettify()) # 此时打印出来为有层级的html格式
# 通过soup对象,去找tag标签
head
= soup.head
print(head) # <head><title>yoyo
ketang</title></head>
# 当有多个标签重名的时候,会从上往下找,找到第一个后就结束,不再往下继续找
# 通过soup对象,去找p标签
p = soup.p
print(p) # <p
class="title"><b>yoyoketang</b></p>
# 获取string对象:通过标签属性获取
s = p.string
print(s) # yoyoketang
# 获取注释对象,(此处的注释在b标签)
b_str
= soup.b.string
print(b_str) #
-- Hey, this in comment!--
print(type(b_str)) # Comment类型
# 标签属性
from bs4 import BeautifulSoup
yoyo = open(‘yoyo.html‘, ‘r‘) # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()
soup = BeautifulSoup(yoyo, ‘html.parser‘)
p = soup.p # p 标签
print(p) # <p class="title"><b>yoyoketang</b></p>
# 获取标签属性
value = p.attrs[‘class‘] # tag对象,可以当成字典取值
print(value) # [‘title‘] list属性
# calss属性有多重属性,返回的值是list
# class="clearfix sdk 十分广泛广泛的
# value = p.attrs[‘class‘]
# print(value) # [‘clearfix‘, ‘sdk‘, ‘十分广泛广泛的‘]

# 查找所有文本
from bs4 import BeautifulSoup
yoyo = open(‘yoyo.html‘, ‘r‘) # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()
soup = BeautifulSoup(yoyo, ‘html.parser‘)
# 获取body对象内容
body = soup.body
print(body)
# 只获取body里面的文本信息
get_text = body.get_text() # 获取当前标签下的,所有子孙节点的string
print(get_text)

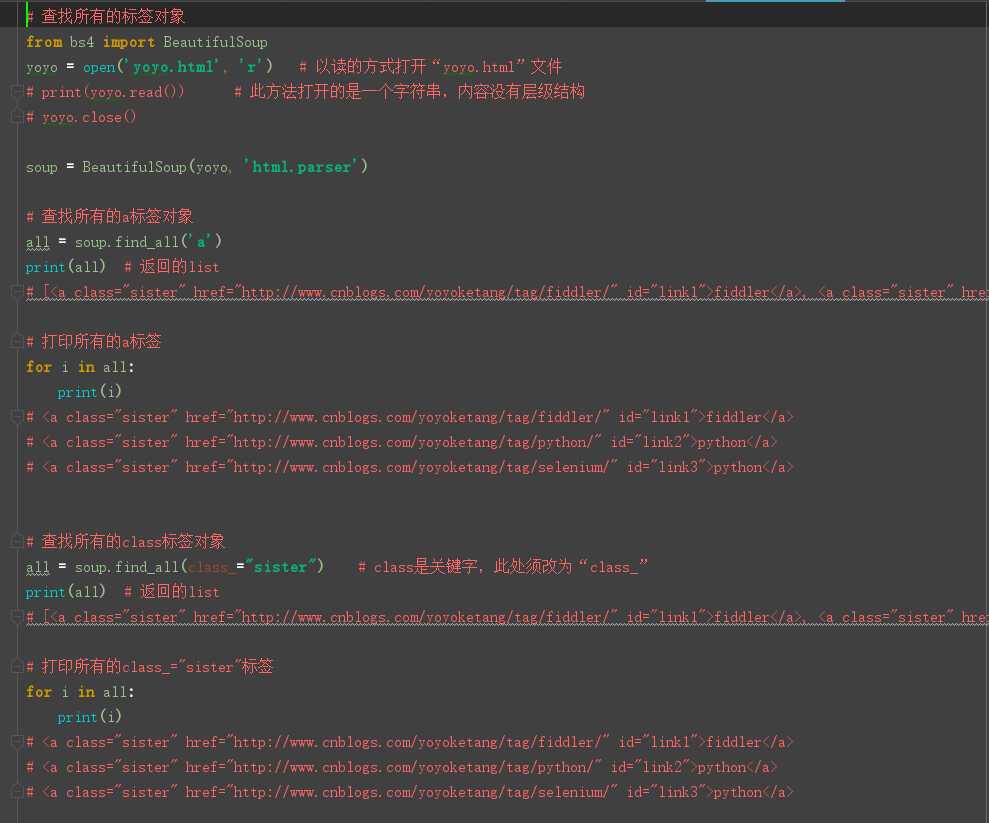
# 查找所有的标签对象
from bs4 import BeautifulSoup
yoyo = open(‘yoyo.html‘, ‘r‘) # 以读的方式打开“yoyo.html”文件
# print(yoyo.read()) # 此方法打开的是一个字符串,内容没有层级结构
# yoyo.close()
soup = BeautifulSoup(yoyo, ‘html.parser‘)
# 查找所有的a标签对象
all = soup.find_all(‘a‘)
print(all) # 返回的list
# [<a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>]
# 打印所有的a标签
for i in all:
print(i)
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>
# 查找所有的class标签对象
all = soup.find_all(class_="sister") # class是关键字,此处须改为“class_”
print(all) # 返回的list
# [<a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>, <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>]
# 打印所有的class_="sister"标签
for i in all:
print(i)
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/fiddler/" id="link1">fiddler</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/python/" id="link2">python</a>
# <a class="sister" href="http://www.cnblogs.com/yoyoketang/tag/selenium/" id="link3">python</a>
# 爬图片
# 目标网站:http://699pic.com/sousuo-218808-13-1.html
import requests
from bs4 import BeautifulSoup
import os
r = requests.get(‘http://699pic.com/sousuo-218808-13-1.html‘)
# r.content # 返回的是字节流
soup = BeautifulSoup(r.content, ‘html.parser‘) # 用html解析器,查找r.content
# tu = soup.find_all(‘img‘) # 查找所有的标签名字为“img”的对象
tu = soup.find_all(class_="lazy") # 查找所有的标签名字为“class_="lazy"”的对象
for i in tu:
# print(i)
# <img alt="洱海清晨的彩霞倒映水中高清图片" class="lazy" data-original="http://img95.699pic.com/photo/50061/5608.jpg_wh300.jpg" height="300" src="http://static.699pic.com/images/blank.png" title="洱海清晨的彩霞倒映水中图片下载" width="453.30915684497"/>
print(i[‘data-original‘]) # 获取所有的url地址
# 爬单张图片
url = ‘http://img95.699pic.com/photo/50061/5608.jpg_wh300.jpg‘
r = requests.get(url)
f = open(‘123.jpg‘, ‘wb‘) # 以二进制写入的方式打开一个名为123.jpg的文件 (后缀可随意改)
f.write(r.content) # 把r传输的字节流写入到文件中
f.close() # 关闭文件
# 批量写入:

# 创建路径, 创建一个名为“tupian”的文件夹
curpath = os.path.dirname(os.path.dirname(os.path.realpath(__file__)))
tupian = os.path.join(curpath, ‘tupian‘)
if not os.path.exists(tupian): # 判断名字为“tupian”的文件夹是否为不存在
os.mkdir(tupian) # 不存在,则创建名字为“tupian”的文件夹
# 批量写入图片并保存
for i in tu:
try:
jpg_url = i[‘data-original‘] # 要获取的图片的地址
name = i[‘alt‘]
r = requests.get(jpg_url)
# 写入内容,放到tupian文件夹下
f = open(os.path.join(tupian, ‘%s.jpg‘%name), ‘wb‘)
f.write(r.content)
f.close()
except:
pass
标签:soup file 信息 parse tag 字符 结构 log 判断
原文地址:https://www.cnblogs.com/zhongyehai/p/9147719.html
