标签:utf8 可变 lse tmp www. com 出现 pyc 问题
最近在做这个新闻爬虫进行文本分析,从网上down了一些爬虫的代码 代码源用的是
https://jooop.github.io/2017/01/29/python3%E7%BD%91%E6%98%93%E7%88%AC%E8%99%AB/#1-%E6%A8%A1%E5%9D%97%E7%9A%84%E9%80%89%E6%8B%A9%E5%92%8C%E5%88%97%E8%A1%A8%E9%A1%B5%E9%9D%A2%E7%9A%84%E7%88%AC%E5%8F%96%EF%BC%9A
可以直接使用 python 2.7+mysql5.6+window7系统+pycharm(IDE)
因为爬虫涉及到中文存储到mysql数据库,所以中间经历了中文乱码显示,中文存储到数据库不能正常显示,从python端打印出来的字符也不是中文显示的问题
归根揭底这都是编码格式的问题。所以写下来作为笔记咯,在数据圈混的人,哪能绕开编码格式呢....
先说python端编码问题:
Python2(包括Python26、Python27等)的字符串通常包含str、unicode两种类型,通常str的字符串编码方式由源码文件的编码方式决定,目前使用的基本都是UTF-8的编码格式,所以要在py文件的头部指定编码格式:# -*- coding: utf-8 -*-
在Python程序内部,通常使用的字符串为unicode编码,这样的字符串字符是一种内存编码格式,如果将这些数据存储到文件或是记录日志的时候,就需要将unicode编码的字符串转换为特定字符集的存储编码格式。
那什么是UNICODE、UTF-8呢?Unicode和UTF-8有什么联系呢?
Unicode( 统一码、万国码、单一码)是计算机科学领域里的一项业界标准,包括字符集、编码方案等。Unicode 是为了解决传统的字符编码方案的局限而产生的,它为每种语言中的每个字符设定了统一并且唯一的 二进制编码,以满足跨语言、跨平台进行文本转换、处理的要求。只要电脑上有 UNICODE 这种编码系统,无论是全球哪种文字,只需要保存文件的时候,保存成 UNICODE 编码就可以被其他电脑正常解释。
UTF-8(8-bit Unicode Transformation Format)是一种针对Unicode的可变长度字符编码,也是一种前缀码,又称万国码。
简单来说,Unicode是一种概念,而UTF-8则是将unicode概念实例化。(老板说,我们要搞大数据架构(此时这个就是概念老板并不知道实现标准是啥对应unicode),程序员搞了个hadoop架构(UTF-8)就是大数据架构的实现)
以下是在python中实验的code
ex1:
In[10]: "中文"
Out[10]:
‘\xe4\xb8\xad\xe6\x96\x87‘
这个例子直接输入中文打印出来的utf-8编码格式的值
ex2: 如果你想打印出来中文 必须在前面加print我不禁有些疑惑,why? 我的理解是如果不加print,python不认为你要求打印显示,只是显示一下数据,它就采用比较懒的方式直接显示这个字在计算机中的编码,如果你加了print,他就理解是你要求打印出来,打印出来就根据你这个实际代表的意思打印咯。前提是你的系统是UTF-8编码格式的哦。如果不是utf-8的编码格式,打印出来也是乱码。更改编码格式请见
In[11]: print "中文"
中文
In[12]: sys.getdefaultencoding()
Out[12]:
‘utf-8‘
Answer:Print打印显示的过程
![]()
图1. Print打印显示过程
Python2.7中调用print打印var 变量时,操作系统会对var做一定的字符处理:如果var是str类型的变量,则直接将var变量交付给终端进行显示;如果var变量是unicode类型,则操作系统首先将var编码成str类型的对象(编码格式取决于stdout的编码格式),然后再交由终端进行显示。在终端显示时,如果str类型的变量的编码方式和终端设置的编码方式不一致,很可能会出现乱码问题。
ex3、列表或字典中的中文处理
data = {"a":"hello","b":"中国"} #假设是utf-8的格式
这时我们用print直接输出data, 或用str函数将data转为字符串。其中的中文是变成unicode的字符,如:
>>> data = {"a":"hello","b":"中国"}
>>> print data
{‘a‘: ‘hello‘, ‘b‘: ‘\xd6\xd0\xb9\xfa‘}
单独输出中文字段没问题,如
>>> print data[‘b‘]
中国
如果希望能正常的将整个字典输出,可以利用json包的dump方法,如:
>>> data = {"a":"hello","b":"中国"}
>>> s = json.dumps(data,ensure_ascii=False);
>>> print s
{"a": "hello", "b": "中国"}
>>> print isinstance(s,str)
True
然后说一下这些数据如何正常的存储到mysql中去
首先mysql要支持utf-8编码存储,需要去mysql安装文件中my.ini配置中进行配置
[client]
#password = your_password
port = 3306
socket = /tmp/mysql.sock
default-character-set=utf8
[mysqld]
port=3306
character-set-server=utf8
collation-server=utf8_general_ci
其次要确定你创建的表及字段默认存储也是utf-8的格式,具体查看和更改方式
https://www.cnblogs.com/wcwen1990/p/6917109.html 可以参考这个网页
然后你就需要将utf-8的字符直接按其本身的字符存储而不是用计算机默认进制字节存储,此时你可以通过
str.decode("unicode_escape") 实现
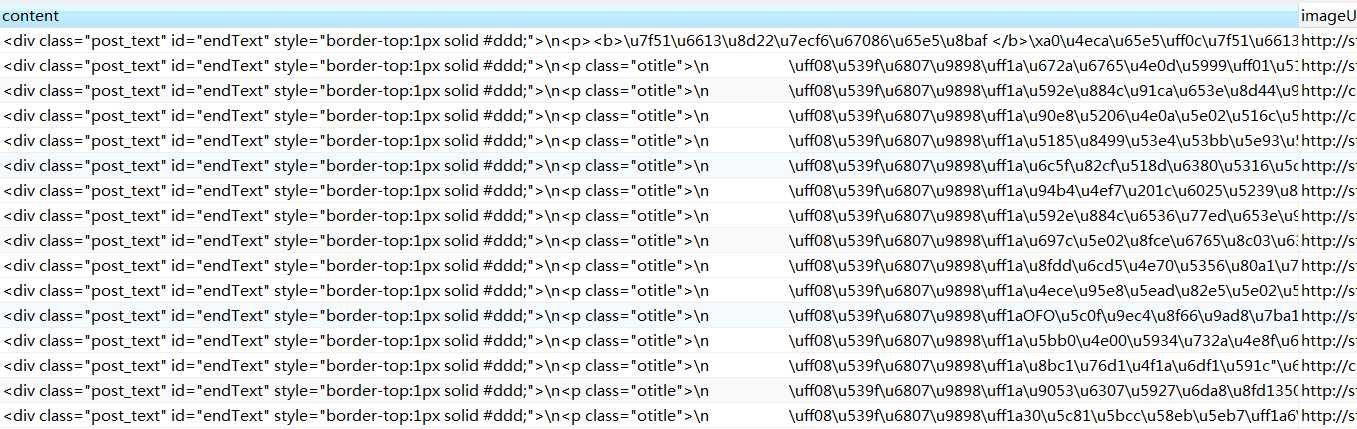
下图是我没有进行decode转换,直接存储进去的就是unicode编码文件
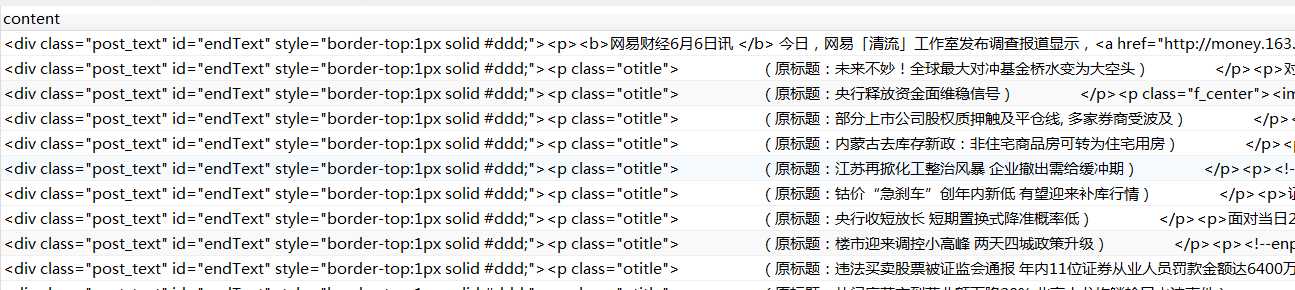
加了decode("unicode_escape")之后的存储就直接是正常的文字了
标签:utf8 可变 lse tmp www. com 出现 pyc 问题
原文地址:https://www.cnblogs.com/lxxlovekang/p/9151274.html