对于语句的运行,除了执行计划本身,还有一些其他因素要考虑,例如语句的编译时间、执行时间、做了多少次磁盘读等。
如果DBA能够把问题语句单独测试运行,可以在运行前打开下面这三个开关,收集语句运行的统计信息。
这些信息对分析问题很有价值。
1 SET STATISTICS TIME ON 2 SET STATISTICS IO ON 3 SET STATISTICS PROFILE ON
SET STATISTICS TIME ON
请先来看看SET STATISTICS TIME ON会返回什么信息。先运行语句:

1 DBCC DROPCLEANBUFFERS 2 --清除buffer pool里的所有缓存数据 3 DBCC freeproccache 4 GO 5 6 --清除buffer pool里的所有缓存的执行计划 7 SET STATISTICS TIME ON 8 GO 9 USE [AdventureWorks] 10 GO 11 SELECT DISTINCT([ProductID]),[UnitPrice] FROM [dbo].[SalesOrderDetail_test] 12 WHERE [ProductID]=777 13 GO 14 SET STATISTICS TIME OFF 15 GO
除了结果集之外,SQLSERVER还会返回下面这两段信息
1 SQL Server 分析和编译时间: 2 CPU 时间 = 15 毫秒,占用时间 = 104 毫秒。 3 SQL Server 分析和编译时间: 4 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 5 6 (4 行受影响) 7 8 SQL Server 执行时间: 9 CPU 时间 = 171 毫秒,占用时间 = 1903 毫秒。 10 SQL Server 分析和编译时间: 11 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
大家知道SQLSERVER执行语句是分以下阶段:分析-》编译-》执行
根据表格的统计信息分析出比较合适的执行计划,然后编译语句,最后执行语句
下面说一下上面的输出是什么意思:
1、CPU时间 :这个值的含义指的是在这一步,SQLSERVER所花的纯CPU时间是多少。也就是说,语句花了多少CPU资源
2、占用时间 :此值指这一步一共用了多少时间。也就是说,这是语句运行的时间长短,有些动作会发生I/O操作,产生了I/O等待,
或者是遇到阻塞、产生了阻塞等待。总之时间用掉了,但是没有用CPU资源。所以占用时间比CPU时间长是很正常的 ,但是CPU时间是
语句在所有CPU上的时间总和。如果语句使用了多颗CPU,而其他等待几乎没有,那么CPU时间大于占用时间也是正常的
3、分析和编译时间:这一步,就是语句的编译时间。由于语句运行之前清空了所有执行计划,SQLSERVER必须要对他编译。
这里的编译时间就不为0了。由于编译主要是CPU的运算,所以一般CPU时间和占用时间是差不多的。如果这里相差比较大,
就有必要看看SQLSERVER在系统资源上有没有瓶颈了。
这里他们是一个15毫秒,一个是104毫秒
4、SQLSERVER执行时间: 语句真正运行的时间。由于语句是第一次运行,SQLSERVER需要把数据从磁盘读到内存里,这里语句的
运行发生了比较长的I/O等待。所以这里的CPU时间和占用时间差别就很大了,一个是171毫秒,而另一个是1903毫秒
总的来讲,这条语句花了104+1903+186=2193毫秒,其中CPU时间为15+171=186毫秒。语句的主要时间应该是都花在了I/O等待上
现在再做一遍语句,但是不清除任何缓存
1 SET STATISTICS TIME ON 2 GO 3 4 SELECT DISTINCT([ProductID]),[UnitPrice] FROM [dbo].[SalesOrderDetail_test] 5 WHERE [ProductID]=777 6 7 GO 8 SET STATISTICS TIME OFF 9 GO
这次比上次快很多。输出时间统计信息是:
1 SQL Server 分析和编译时间: 2 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 3 SQL Server 分析和编译时间: 4 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。 5 6 (4 行受影响) 7 8 SQL Server 执行时间: 9 CPU 时间 = 156 毫秒,占用时间 = 169 毫秒。 10 SQL Server 分析和编译时间: 11 CPU 时间 = 0 毫秒,占用时间 = 0 毫秒。
由于执行计划被重用,“SQL分析和编译时间” CPU时间是0,占用时间是0
由于数据已经缓存在内存里,不需要从磁盘上读取,SQL执行时间 CPU时间是156,占用时间这次和CPU时间非常接近,是169。
这里省下运行时间1903-169=1734毫秒,从这里可以再次看出,缓存对语句执行性能起着至关重要的作用
为了不影响其他测试,请运行下面的语句关闭SET STATISTICS TIME ON
1 SET STATISTICS TIME OFF 2 GO
SET STATISTICS IO ON
这个开关能够输出语句做的物理读和逻辑读的数目。对分析语句的复杂度有很重要的作用
还是以刚才那个查询作为例子
1 DBCC DROPCLEANBUFFERS 2 GO 3 SET STATISTICS IO ON 4 GO 5 6 SELECT DISTINCT([ProductID]),[UnitPrice] FROM [dbo].[SalesOrderDetail_test] 7 WHERE [ProductID]=777 8 GO
他的返回是:
1 (4 行受影响) 2 表 ‘SalesOrderDetail_test‘。扫描计数 5,逻辑读取 15064 次,物理读取 0 次,预读 15064 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次。
各个输出的含义是:
表:表的名称。这里的表就是SalesOrderDetail_test
扫描计数:执行的扫描次数。按照执行计划,表格被扫描了几次。一般来讲大表扫描的次数越多越不好。唯一的例外是如果执行计划选择了并发运行,
由多个thread线程同时做一个表的读取,每个thread读其中的一部分,但是这里会显示所有thread的数目。也就是有几个thread在并发做,
就会有几个扫描。这时数目大一点没问题的。
逻辑读取:从数据缓存读取的页数。页数越多,说明查询要访问的数据量就越大,内存消耗量越大,查询也就越昂贵。
可以检查是否应该调整索引,减少扫描的次数,缩小扫描范围
顺便说一下这个逻辑读取的统计原理:为什麽显示出来的结果的单位不是Page,也不是K或KB。SQLSERVER
里在做读和写的时候,会运行到某一段特定的代码。每调用一次这个代码,Reads/Write就会加1。所以这个值比较大
那语句一定做了比较多的I/O,但是不能通过这个值计算出I/O的绝对数量,这个值反映的是逻辑读写量不是物理读写量
1 逻辑读取 15064 次
物理读取:从磁盘读取的页数
预读:为进行查询而预读入缓存的页数
物理读取+预读:就是SQLSERVER为了完成这句查询而从磁盘上读取的页数。如果不为0,说明数据没有缓存在内存里。运行速度一定会受到影响
LOB逻辑读取:从数据缓存读取的text、ntext、image、大值类型(varchar(max)、nvarchar(max)、varbinary(max))页的数目
LOB物理读取:从磁盘读取的text、ntext、image、大值类型页的数目
LOB预读:为进行查询而放入缓存的text、ntext、image、大值类型页的数目
然后再来运行一遍,不清空缓存
1 SET STATISTICS IO ON 2 GO 3 4 SELECT DISTINCT([ProductID]),[UnitPrice] FROM [dbo].[SalesOrderDetail_test] 5 WHERE [ProductID]=777 6 GO
结果集返回:
1 表 ‘SalesOrderDetail_test‘。扫描计数 5,逻辑读取 15064 次,物理读取 0 次,预读 0 次,lob 逻辑读取 0 次, 2 lob 物理读取 0 次,lob 预读 0 次。
这次逻辑读取不变,还是15064页。但是物理读取和预读都是0了。说明数据已经缓存在内存里
第二次运行不需要再从磁盘上读一遍,节省了时间
为了不影响其他测试,请运行下面语句关闭SET STATISTICS IO ON
1 SET STATISTICS IO OFF 2 GO
SET STATISTICS PROFILE ON
这是三个设置中返回最复杂的一个,他返回语句的执行计划,以及语句运行在每一步的实际返回行数统计。
通过这个结果,不仅可以得到执行计划,理解语句执行过程,分析语句调优方向,也可以判断SQLSERVER是否
选择了一个正确的执行计划。
1 SET STATISTICS PROFILE ON 2 GO 3 SELECT COUNT(b.[SalesOrderID]) 4 FROM [dbo].[SalesOrderHeader_test] a 5 INNER JOIN [dbo].[SalesOrderDetail_test] b 6 ON a.[SalesOrderID]=b.[SalesOrderID] 7 WHERE a.[SalesOrderID]>43659 AND a.[SalesOrderID]<53660 8 GO
返回的结果集很长,下面说一下重要字段
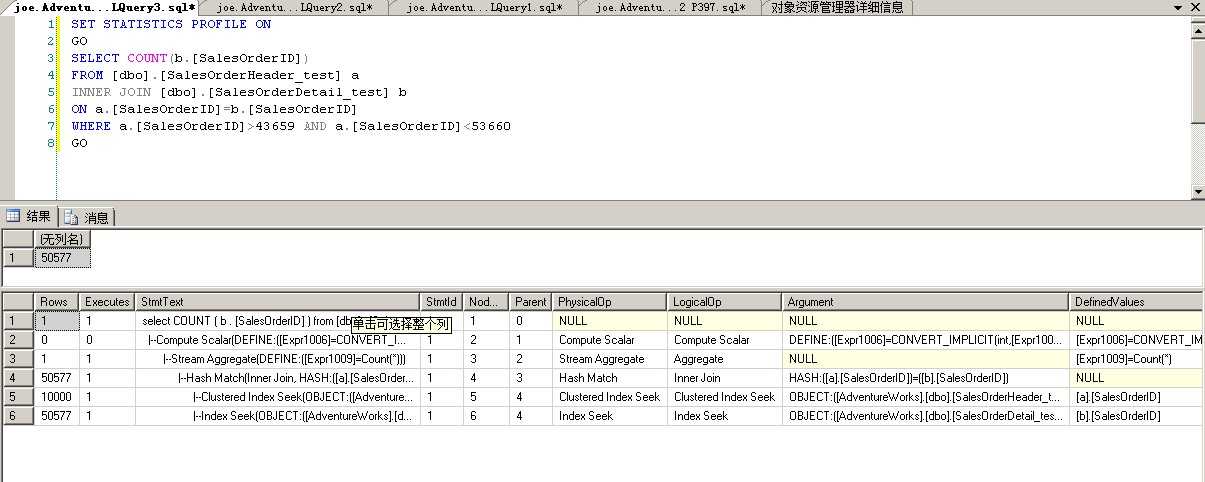
注意:这里是从最下面开始向上看的,也就是说从最下面开始一直执行直到得到结果集所以(行1)里的rows字段显示的值就是这个查询返回的结果集。
而且有多少行表明SQLSERVER执行了多少个步骤,这里有6行,表明SQLSRVER执行了6个步骤!!
Rows:执行计划的每一步返回的实际行数
Executes:执行计划的每一步被运行了多少次
StmtText:执行计划的具体内容。执行计划以一棵树的形式显示。每一行都是运行的一步,都会有结果集返回,也都会有自己的cost
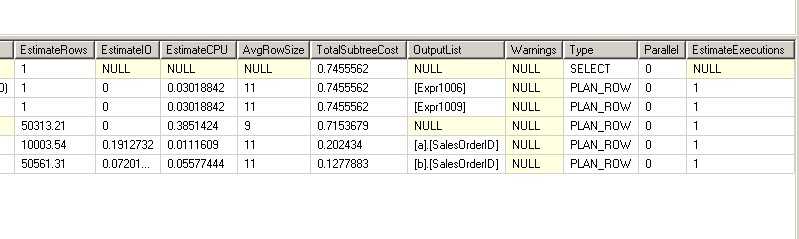
EstimateRows:SQLSERVER根据表格上的统计信息,预估的每一步的返回行数。在分析执行计划时,
我们会经常将Rows和EstimateRows这两列做对比,先确认SQLSERVER预估得是否正确,以判断统计信息是否有更新
EstimateIO:SQLSERVER根据EstimateRows和统计信息里记录的字段长度,预估的每一步会产生的I/O cost
EstimateCPU:SQLSERVR根据EstimateRows和统计信息里记录的字段长度,以及要做的事情的复杂度,预估每一步会产生的CPU cost
TotalSubtreeCost:SQLSERVER根据EstimateIO和EstimateCPU通过某种计算公式,计算出每一步执行计划子树的cost
(包括这一步自己的cost和他的所有下层步骤的cost总和),下面介绍的cost说的都是这个字段值
Warnings:SQLSERVER在运行每一步时遇到的警告,例如,某一步没有统计信息支持cost预估等。
Parallel:执行计划的这一步是不是使用了并行的执行计划
从上面结果可以看出执行计划分成4步,其中第一步又分成并列的两个子步骤
步骤a1(第5行):从[SalesOrderHeader_test]表里找出所有a.[SalesOrderID]>43659 AND a.[SalesOrderID]<53660的值
因为表在这个字段上有一个聚集索引,所以SQL可以直接使用这个索引的seek
SQL预测返回10000条记录,实际也就返回了10000条记录.。这个预测是准确的。这一步的cost是0.202(totalsubtreecost)
步骤a2(第6行):从[SalesOrderDetail_test]表里找出所有 a.[SalesOrderID]>43659 AND a.[SalesOrderID]<53660的值
因为表在这个字段上有一个非聚集索引,所以SQL可以直接使用这个索引的seek
这里能够看出SQL聪明的地方。虽然查询语句只定义了[SalesOrderHeader_test]表上有a.[SalesOrderID]>43659 AND a.[SalesOrderID]<53660过滤条件,
但是根据语义分析,SQL知道这个条件在[SalesOrderDetail_test]上也为真。所以SQL选择先把这个条件过滤然后再做join。这样能够大大降低join的cost
在这一步SQL预估返回50561条记录,实际返回50577条。cost是0.127,也不高
步骤b(第4行):将a1和a2两步得到的结果集做一个join。因为SQL通过预估知道这两个结果集比较大,所以他直接选择了Hash Match的join方法。
SQL预估这个join能返回50313行,实际返回50577行。因为SQL在两张表的[SalesOrderID]上都有统计信息,所以这里的预估非常准确
这一步的cost等于totalsubtreecost减去他的子步骤,0.715-0.202-0.127=0.386。由于预估值非常准确,可以相信这里的cost就是实际每一步的cost
步骤c(第3行):在join返回的结果集基础上算count(*)的值这一步比较简单,count(*)的结果总是1,所以预测值是正确的。
其实这一步的cost是根据上一步(b)join返回的结果集大小预估出来的。我们知道步骤b的预估返回值非常准确,所以这一步的预估cost也不会有什么大问题
这棵子树的cost是0.745,减去他的子节点cost,他自己的cost是0.745-0.715=0.03。是花费很小的一步
步骤b(第2行):将步骤c返回的值转换为int类型,作为结果返回
这一步是上一步的继续,更为简单。convert一个值的数据类型所要的cost几乎可以忽略不计。所以这棵子树的cost和他的子节点相等,都是0.745。
也就是说,他自己的cost是0
通过这样的方法,用户可以了解到语句的执行计划、SQL Server预估的准确性、cost的分布
最后说一下:不同SQL Server版本,不同机器cost可能会不一样,例如SQL Server 2005 、SQL Server 2008
转自:https://www.cnblogs.com/tohen/p/6183618.html