标签:算法思路 ali https action 内容 matrix cto 解决 排序
github:PCA代码实现、PCA应用
本文算法均使用python3实现
??在实际生产生活中,我们所获得的数据集在特征上往往具有很高的维度,对高维度的数据进行处理时消耗的时间很大,并且过多的特征变量也会妨碍查找规律的建立。如何在最大程度上保留数据集的信息量的前提下进行数据维度的降低,是我们需要解决的问题。
??对数据进行降维有以下优点:
??(1)使得数据集更易使用
??(2)降低很多算法的计算开销
??(3)去除噪声
??(4)使得结果易懂
??降维技术作为数据预处理的一部分,即可使用在监督学习中也能够使用在非监督学习中。而降维技术主要有以下几种:主成分分析(Principal Component Analysis,PCA)、因子分析(Factor Analysis),以及独立成分分析(Independent Component Analysis, ICA)。其中主成分分析PCA应用最为广泛,本文也将详细介绍PCA。
??我们利用一个例子来理解PCA如何进行降维的。
??参考下图,对于样本数据 $ D=\lbrace x^{(1)},x^{(2)},...,x^{(m)} \rbrace$ ,其中 $ x^{(i)} = [ x^{(i)}_1 , x^{(i)}_2]^T $
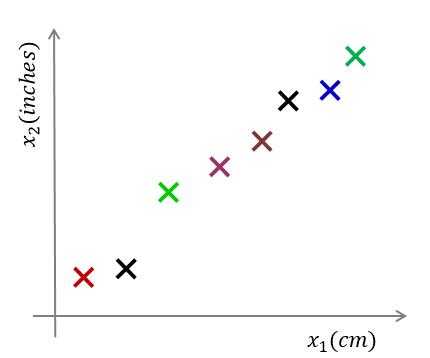

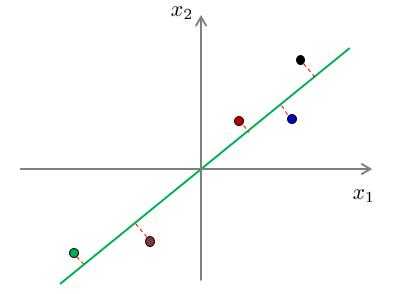
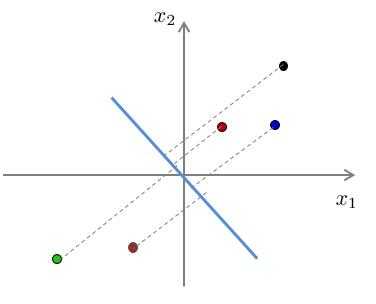
??我们能够和清楚地看到,对于第一种向量的投影误差和一定比第二种的投影误差和要小。
??对应以上两幅图的投影结果:

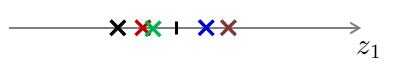
??假设对于原样本中,位于第一象限的三个样本点属于类别“A”,位于第三象限的两个样本点属于类别“B”。经过投影后,我们可以看出,对于第一种降维,在降维后仍旧保持了位于原点右侧的三个样本属于类别“A”,位于原点左侧的两个样本属于类别“B”。而对于第二种投影,明显可以看出,已经不能够分辨出样本的类别了。换句话说,第二种投影方式丢失了一些信息。
??因此,“投影误差和最小”便成为我们所需要优化的目标。
??那么如何寻找投影误差最小的方向呢?
??寻找到方差最大的方向即可。方差最大与投影误差最小这两个优化目标其实本质上是一样的,具体可参考周志华著《机器学习》一书,书中证明了最大可分性(误差最大)与最近重构性(投影和最小)两种优化等价。
??到此我们就对PCA的降维方式已经有了初步的理解。
??PCA的算法思路主要是:数据从原来的坐标系转换到新的坐标系,由数据本身决定。转换坐标系时,以方差最大的方向作为坐标轴方向,因为数据的最大方差给出了数据的最重要的信息。第一个新坐标轴选择的是原始数据中方差最大的方向,第二个新坐标轴选择的是与第一个新坐标轴正交且方差次大的方向。重复该过程,重复次数为原始数据的特征维数。
??通过这种方式获得的新的坐标系,我们发现,大部分方差都包含在前面几个坐标轴中,后面的坐标轴所含的方差几乎为0。于是,我们可以忽略余下的坐标轴,只保留前面的几个含有绝大部分方差的坐标轴。事实上,这样也就相当于只保留包含绝大部分方差的维度特征,而忽略包含方差几乎为0的特征维度,也就实现了对数据特征的降维处理。
??根据以上PCA算法思路的描述,我们大概可以看出,对于PCA算法,其要点主要是如何找到方差最大的方向。
??这里将提到有关线性代数里的一些内容:
??(1)协方差矩阵
????(1.1)特征 $ X_i $ 与特征 $ X_j $ 的协方差(Covariance): \[ Cov(X_i, X_j) = \frac{\sum_{k=1}^n(X_i^{(k)} - \overline{X}_i)(X_j^{(k)}-\overline{X}_j)}{n-1} \]
??????其中 $ X_i^{(k)}, X_j^{(k)} $ 表示特征 $ X_i.X_j $ 的第 $ k $ 个样本中的取值。而 $ \overline{X}_i,\overline{X}_j $ 则是表示两个特征的样本均值。
??????可以看出,当 $ X_i = X_j $ 时,协方差即为方差。
????(1.2)对于一个只有两个特征的样本来说,其协方差矩阵为: \[ C = \begin{bmatrix} Cov(X_1,X_1) & Cov(X_1,X_2) \\ Cov(X_2,X_1) & Cov(X_2,X_2) \\ \end{bmatrix} \]
??????当特征数为 $ n $ 时,协方差矩阵为 $ n \times n $ 维的矩阵,且对角线为各特征的方差值。
??(2)特征向量与特征值
????对于矩阵 $ A $ ,若满足 $ A \zeta = \lambda \zeta $ ,则称 $ \zeta $ 是矩阵 $ A $ 的特征向量,而 $ \lambda $ 则是矩阵 $ A $ 的特征值。将特征值按照从大到小的顺序进行排序,选择前 $ k $ 个特征值所对应的特征向量即为所求投影向量。
????对于特征值与特征向量的求解,主要是:特征分解(当 $ A $ 为方阵时),奇异值SVD分解(当 $ A $ 不为方阵时)
??输入:训练样本集 $ D ={x^{(1)},x^{(2)},...,x^{(m)}} $ ,低维空间维数 $ d‘ $ ;
??过程:.
??1:对所有样本进行中心化(去均值操作): $ x_j^{(i)} \leftarrow x_j^{(i)} - \frac{1}{m} \sum_{i=1}^m x_j^{(i)} $ ;
??2:计算样本的协方差矩阵 $ XX^T $ ;
??3:对协方差矩阵 $ XX^T $ 做特征值分解 ;
??4:取最大的 $ d‘ $ 个特征值所对应的特征向量 $ w_1,w_2,...,w_{d‘} $
??5:将原样本矩阵与投影矩阵相乘: $ X \cdot W $ 即为降维后数据集 $ X‘ $ 。其中 $ X $ 为 $ m \times n $ 维, $ W = [w_1,w_2,...,w_{d‘}] $ 为 $ n \times d‘ $ 维。
??5:输出:降维后的数据集 $ X‘ $
??优点:使得数据更易使用,并且可以去除数据中的噪声,使得其他机器学习任务更加精确。该算法往往作为预处理步骤,在数据应用到其他算法之前清洗数据。
??缺点:数据维度降低并不代表特征的减少,因为降维仍旧保留了较大的信息量,对结果过拟合问题并没有帮助。不能将降维算法当做解决过拟合问题方法。如果原始数据特征维度并不是很大,也并不需要进行降维。
引用及参考:
[1]《机器学习》周志华著
[2]《机器学习实战》Peter Harrington著
[3] https://www.cnblogs.com/zy230530/p/7074215.html
[4] http://www.cnblogs.com/zhangchaoyang/articles/2222048.html
[5] https://www.cnblogs.com/terencezhou/p/6235974.html
写在最后:本文参考以上资料进行整合与总结,属于原创,文章中可能出现理解不当的地方,若有所见解或异议可在下方评论,谢谢!
若需转载请注明:https://www.cnblogs.com/lliuye/p/9156763.html
标签:算法思路 ali https action 内容 matrix cto 解决 排序
原文地址:https://www.cnblogs.com/lliuye/p/9156763.html