标签:code 需要 校验 存在 decode xls lse string www
url = ‘接口地址‘
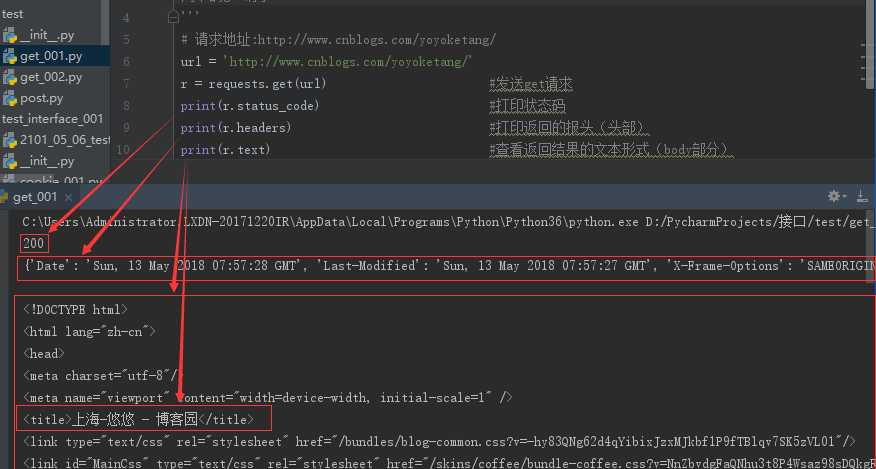
r = requests.get(url) #发送get请求
print(r.status_code) #打印状态码,若有重定向,返回的是重定向之后的代码
print(r.headers) #打印返回的报头(头部)
print(r.text) #查看返回结果的文本形式
r.status_code #响应状态码
r.content #字节方式的响应体,会自动为你解码 gzip 和 deflate 压缩
r.headers #以字典对象存储服务器响应头,但是这个字典比较特殊,字典键不区分大小写,若键不存在则返回None
r.json() #Requests中内置的JSON解码器 ,json转成python的字典了
r.url # 如果没有重定向,就是请求的url,如果有重定向,就是重定向后的url
r.encoding # 查看返回的编码格式
r.cookies # 获取cookie
r.raw #返回原始响应体
r.history #追踪重定向过程(list类型)
r.text #字符串方式的响应体,会自动根据响应头部的字符编码进行解码
r.content.decode(‘utf-8‘) # 返回内容有乱码时,用此方法打印
r.raise_for_status() #失败请求(非200响应)抛出异常
loginCookies = r.cookies: # 获取登录的cookies
cookies=loginCookies: # 把获取到的cookies传入请求
s = requests.session() # 可以理解为代码的微型浏览器,这样做的好处就是可以保存cookies,不用每次都去获取(只适用于网站是cookies这种,网站是token的没用)
print(r.encoding) # 查看返回的编码格式
r.json # 获取返回的json
verify=False # 访问https请求时加上后不验证证书
# open打开excel文件,保存为后缀为xls的文件
fp = open(‘yoyo.xls‘, ‘wb‘) # w:写入, b:二进制的形式
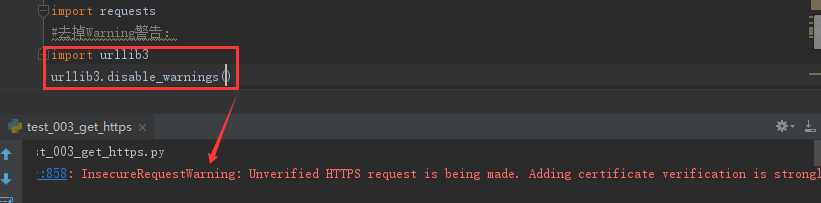
去掉Warning警告:
import urllib3
urllib3.disable_warnings()
一、HTTP:
get请求:
1、get请求(无参数):
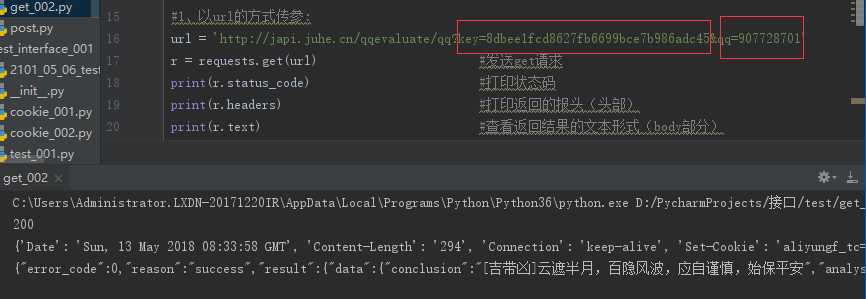
2、get请求(带参数):
接口地址:http://japi.juhe.cn/qqevaluate/qq
返回格式:json
请求方式:get post
请求示例:http://japi.juhe.cn/qqevaluate/qq?key=您申请的appKey&qq=295424589
接口备注:根据传入的参数 qq 号码和您申请的 appKey 测试 qq 的吉凶
请求参数说明(入参) :
名称 必填 类型 说明
key 是 string 您申请的 appKey:8dbee1fcd8627fb6699bce7b986adc45
qq 是 string 需要测试的 QQ 号码:907728701
2.1、以url的方式传参:
url = ‘http://japi.juhe.cn/qqevaluate/qq?key= 8dbee1fcd8627fb6699bce7b986adc45&qq=907728701‘
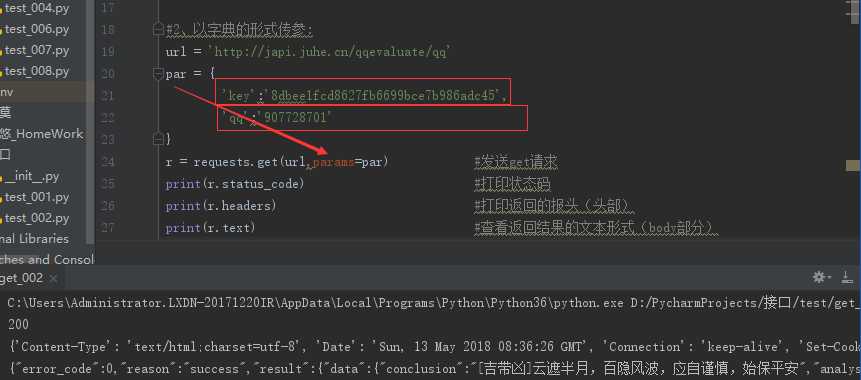
2.2、以字典的形式传参:
url = ‘http://japi.juhe.cn/qqevaluate/qq‘
par = {
‘key‘:‘ 8dbee1fcd8627fb6699bce7b986adc45‘,
‘qq‘:‘907728701‘
}
r = requests.get(url,params=par) #发送get请求
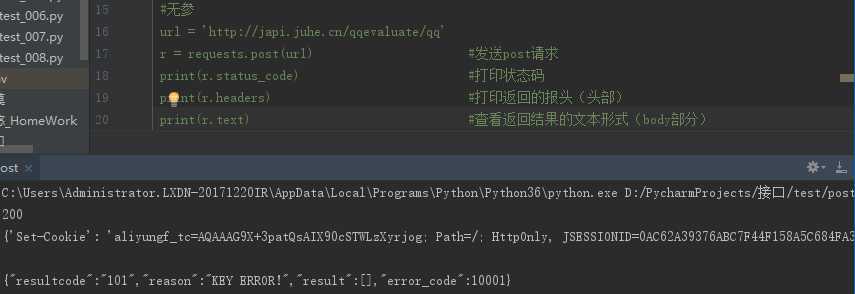
Post请求:
1、 post请求(无参数):
url = ‘http://japi.juhe.cn/qqevaluate/qq‘
r = requests.post(url) #发送post请求
print(r.status_code) #打印状态码
print(r.headers) #打印返回的报头(头部)
print(r.text) #查看返回结果的文本形式(body部分)
2、 post请求(有参数):
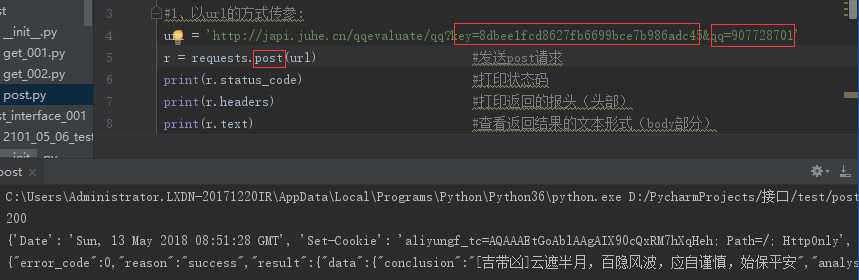
2.1、以url的方式传参:
url = ‘http://japi.juhe.cn/qqevaluate/qq?key= 8dbee1fcd8627fb6699bce7b986adc45&qq=907728701‘
r = requests.post(url) #发送post请求
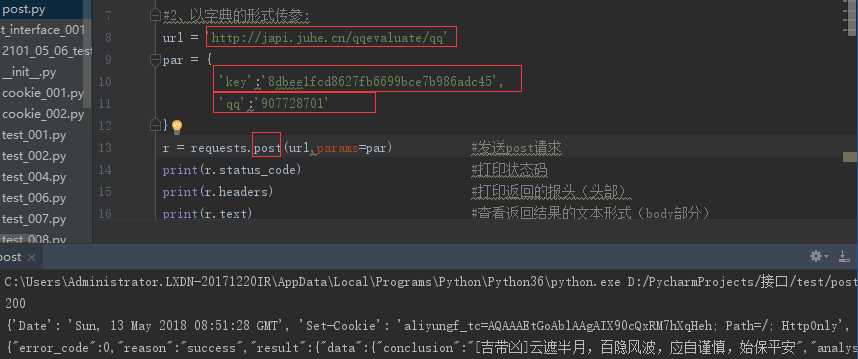
2.2、以字典的形式传参:
url = ‘http://japi.juhe.cn/qqevaluate/qq‘
par = {
‘key‘:‘8dbee1fcd8627fb6699bce7b986adc45‘,
‘qq‘:‘907728701‘
}
r = requests.post(url,params=par) #发送get请求
二、HTTPS:
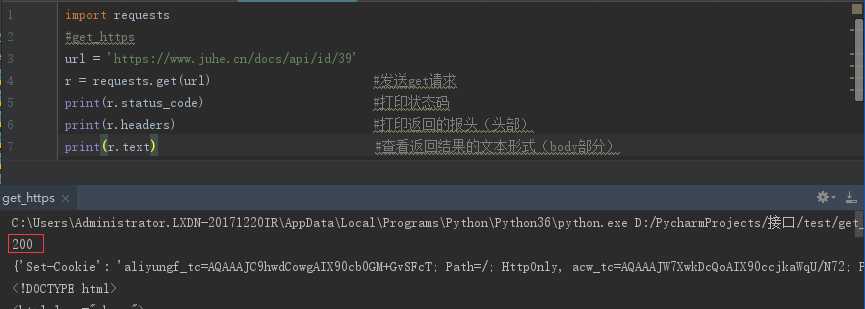
1、get:
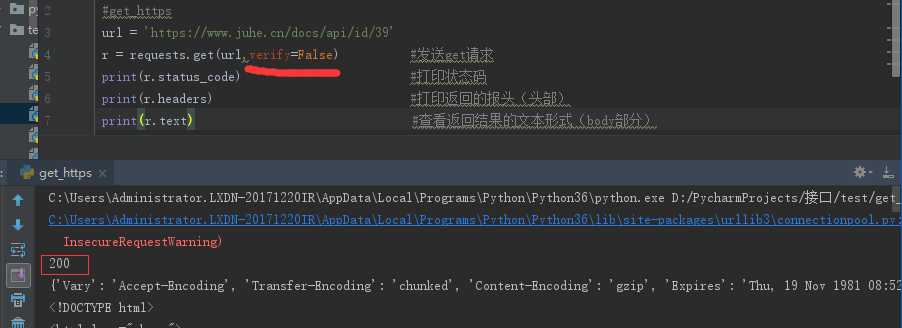
url = ‘https://www.juhe.cn/docs/api/id/39‘
r = requests.get(url) #发送get请求
print(r.status_code) #打印状态码
print(r.headers) #打印返回的报头(头部)
print(r.text) #查看返回结果的文本形式(body部分)
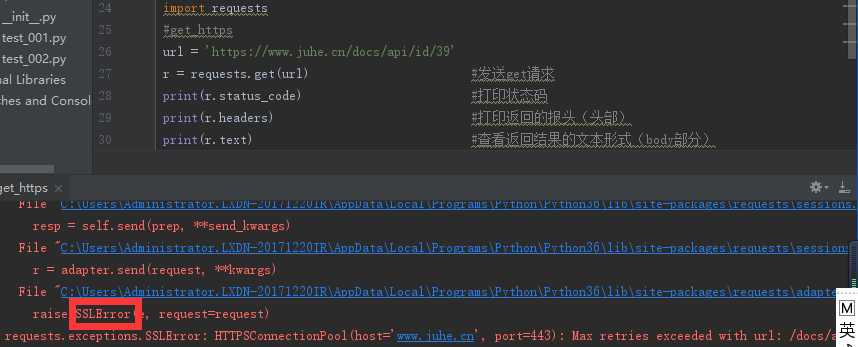
SSLError:证书问题:
方法1.检查faddler是否关闭,关闭后,访问成功:
方法2.请求参数后加上:verify=False
verify默认为True,此时会验证证书,改为False将不会验证证书
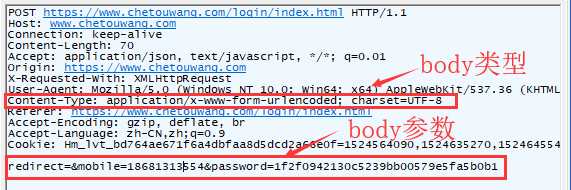
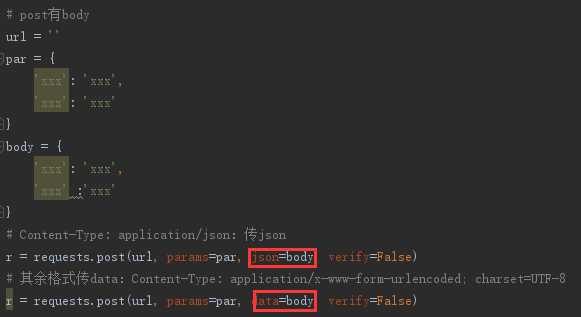
有Body部分:
Content-Type: application/x-www-form-urlencoded; charset=UTF-8:传data
Content-Type: application/json:传json
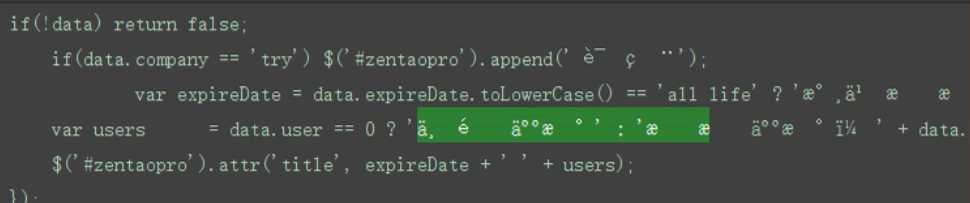
把返回的内容解析为json格式:
前提:一定内容为json格式
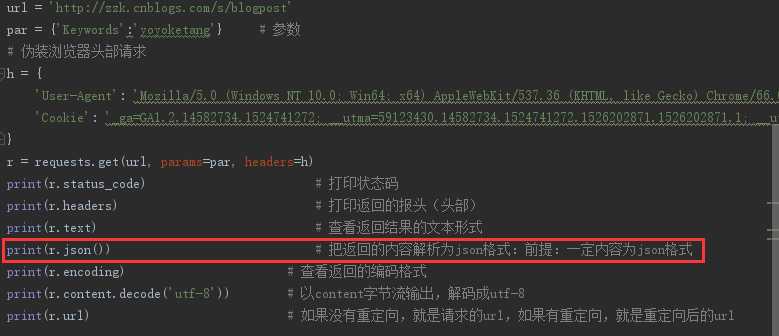
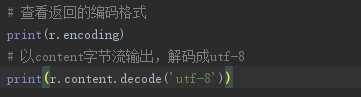
若乱码::
以content字节流输出,解码成utf-8:
print(r.encoding) # 查看返回的编码格式:
去掉Warning警告:
import urllib3
urllib3.disable_warnings()
错误处理:
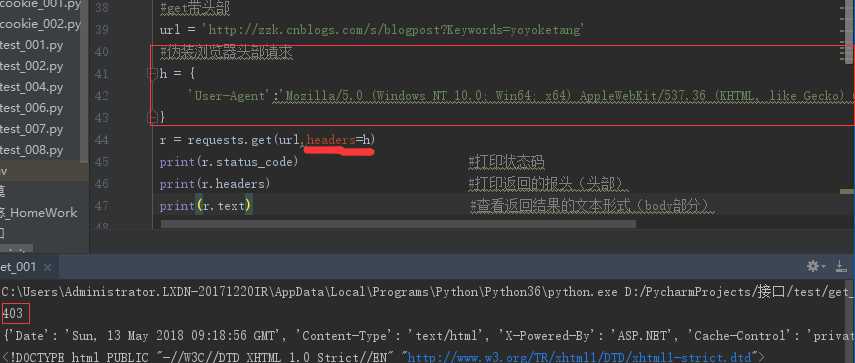
403:拒绝或者禁止访问:须伪装头部(头部详情根据接口文档)

1、服务器识别出为代码访问:
1.1.代码访问的头部:User-Agent为python

1.2.浏览器访问的头部:User-Agent为浏览器

1.3.在头部加上User-Agent:
2、伪装头部后仍然403:服务器校验Cookic (Cookic有时效性)
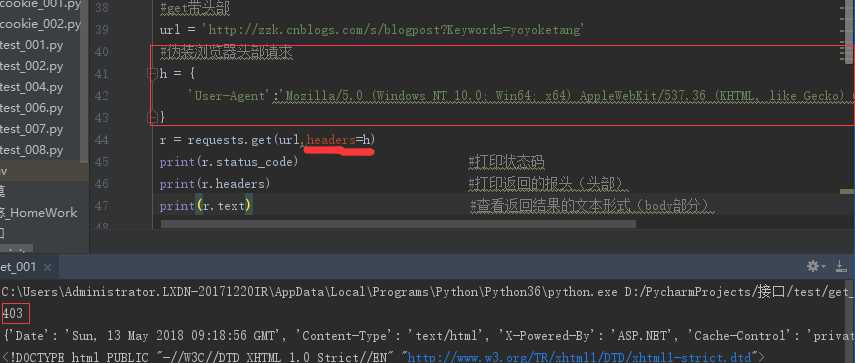
2.1.代码访问时没有加Cookic
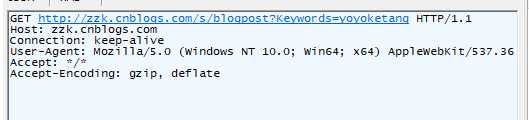
2.2.浏览器访问时有Cookic
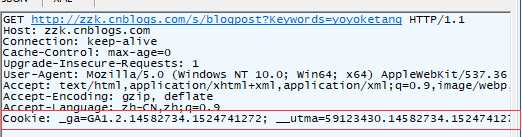
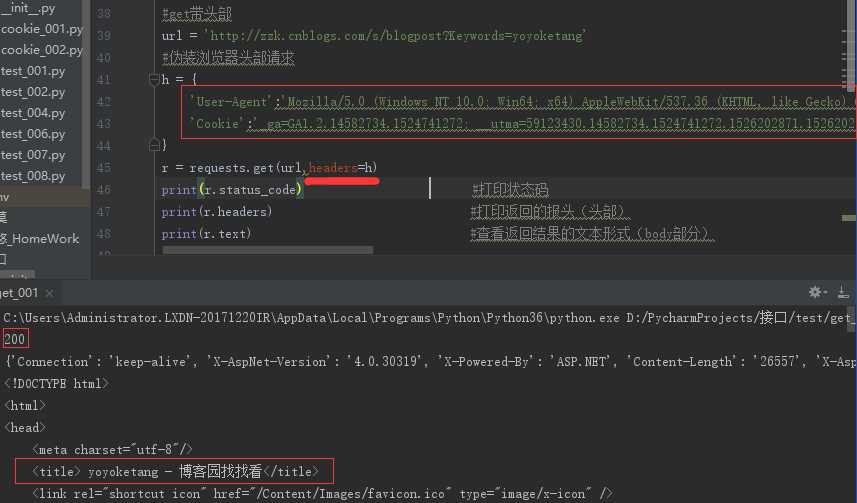
2.3.在头部加上Cookic访问成功
标签:code 需要 校验 存在 decode xls lse string www
原文地址:https://www.cnblogs.com/zhongyehai/p/9159282.html