标签:request 服务器 选择 find uri 前言 简单 env pass
偶然间发现 Google 收录了学校实验打卡系统的接口,正好要做数据库课设,便拿来作为 environment。
机房居然装了 python ,早就听说 python 写爬虫速度一流,课上的 DDL 做完也闲,便决定用 python 完成这次数据库课设。
爬虫访问网页需要 import 一个 HTTP 访问包,由于接口过于简单,直接 GET 请求即可得到数据,连 COOKIES 都不用,直接用 urllib 即可。
url="yoururladdress"
req=urllib.request.Request(url)
resp=urllib.request.urlopen(req)
data=resp.read().decode('GBK')爬到的网页需要批量取出两个已知字符串的中间文本,可以使用正则表达式轻松解决,import re 包即可。
w1='<td width=\'610\' height=\'25\' style=\'padding-left:5px;\'>'
w2='</td></tr>'
pat=re.compile(w1+'(.*?)'+w2,re.S)
sybz=pat.findall(data)
试了好几种包,最后发现还是 pyodbc 好用
pyodbc 官方文档:https://github.com/mkleehammer/pyodbc/wiki
首先在命令行中输入 pip install pyodbc 安装 pyodbc 包
打开 SQL server Configuration Manager,选择 SQL Server 网络配置 - MSSQLSERVER 的协议 - TCP/IP
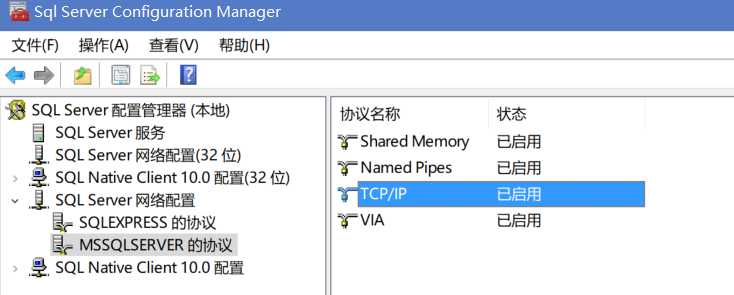
右击属性找到设置的端口,一般是 127.0.0.1:1433
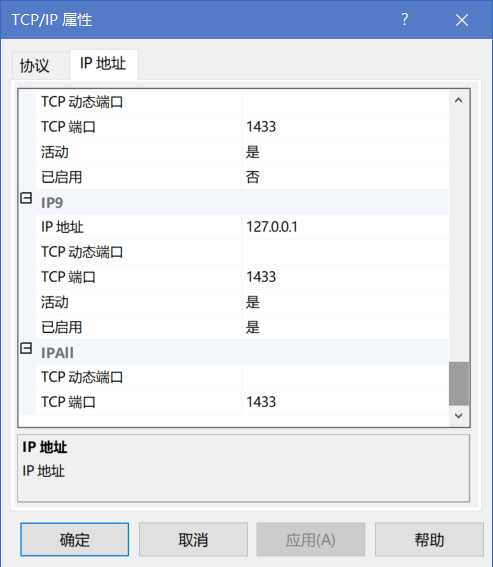
打开 Microsoft SQL Server Management Studio,连接上本地数据库后右击属性,选择安全性,将服务器身份验证中 SQL SERVER 和 WINDOWS 身份验证模式复选栏勾上。
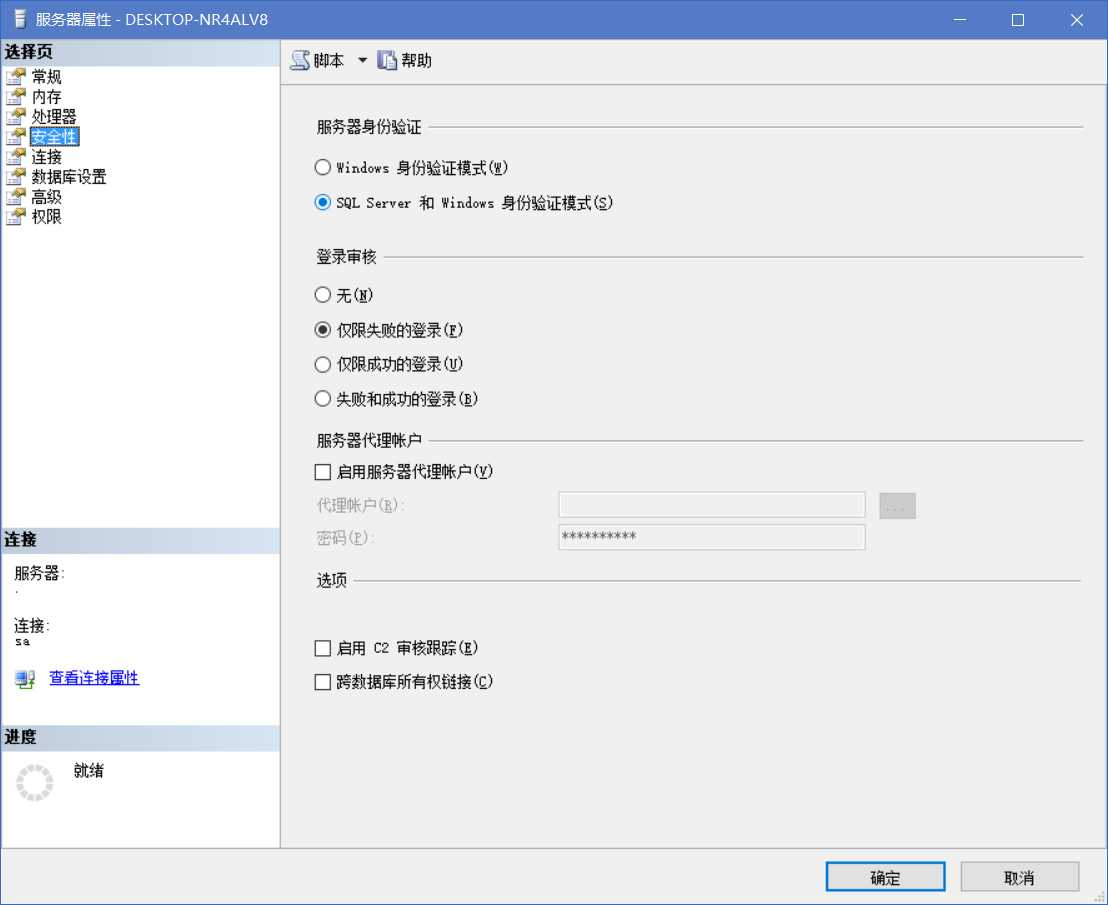
打开左侧个人数据库的属性,选择文件,将 sa 赋予所有者权限
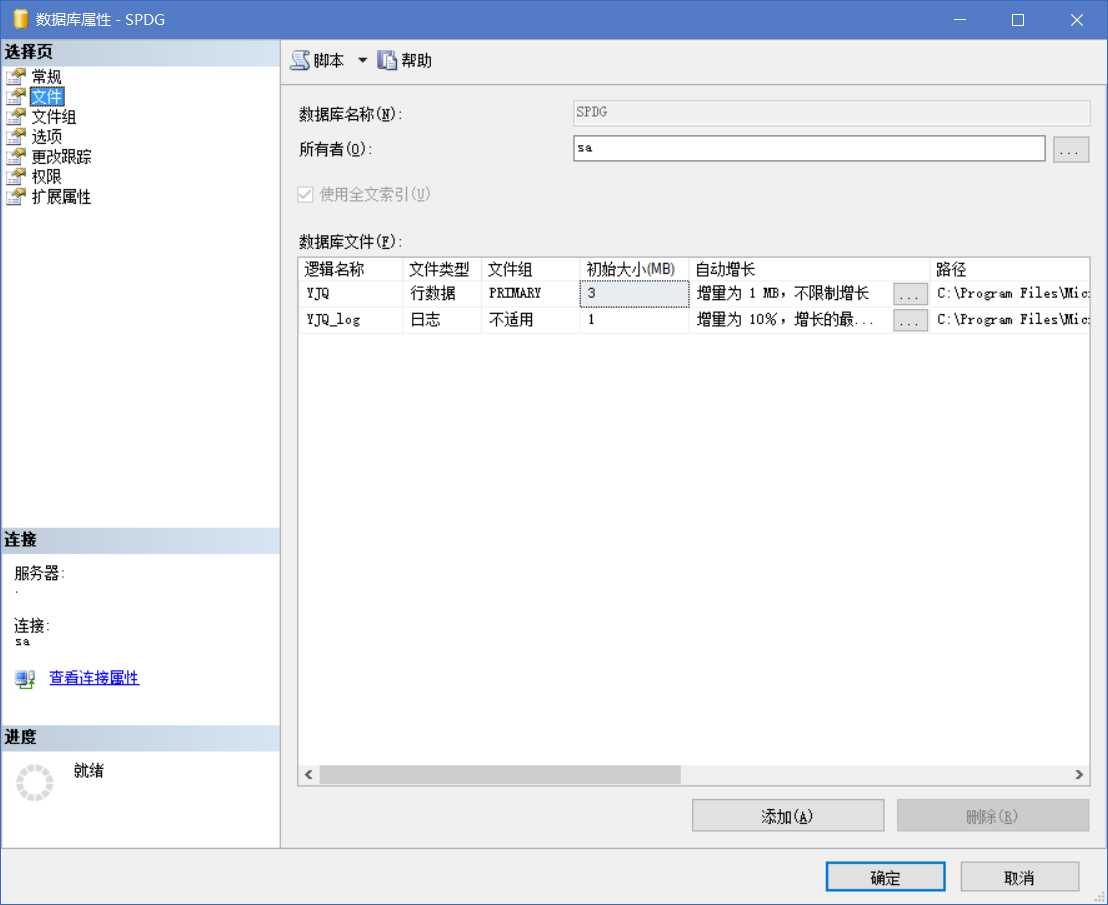
打开安全性 - 登录名 - sa,右击属性给 sa 指定一个密码,并将强制实施密码策略取消选择
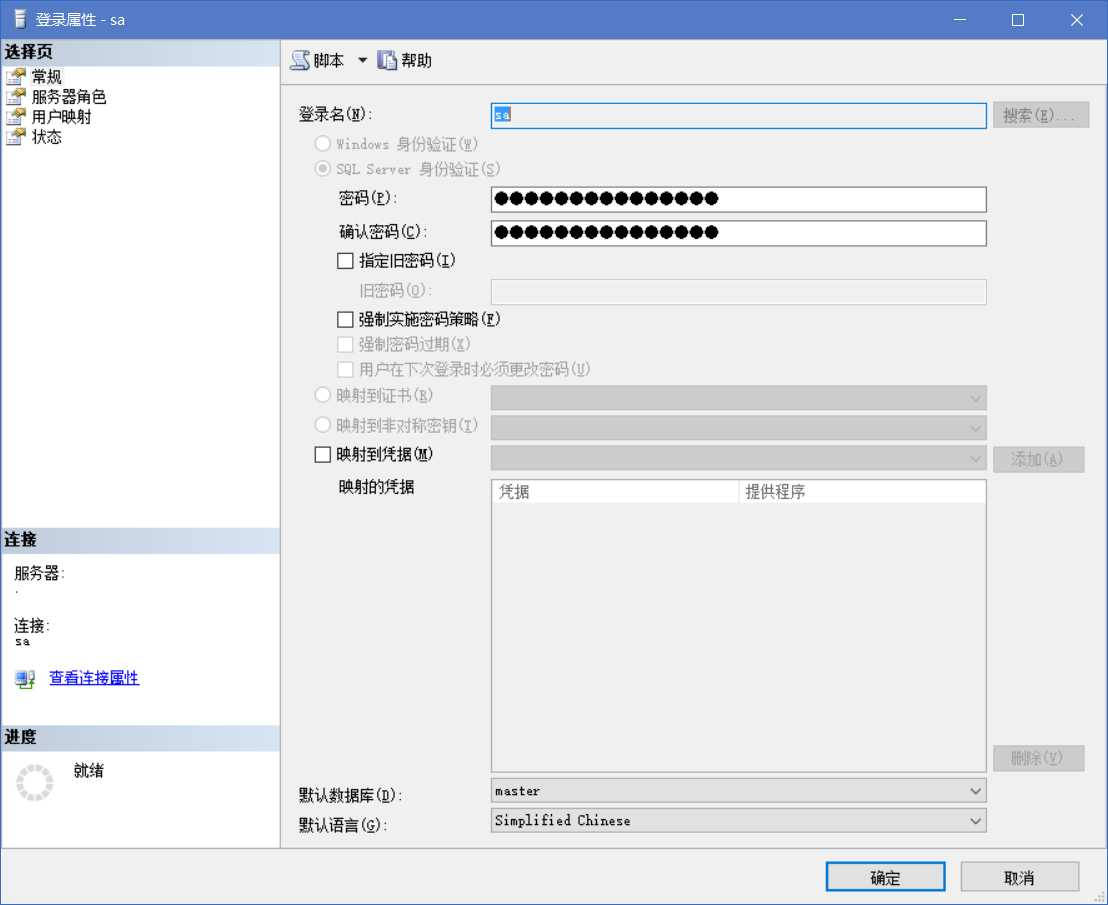
选择状态,如图所示,将设置完成:
新建一个 py 文件,输入下列代码(注意将 yourpassword 处改为自己的密码):
import pyodbc
cnxn = pyodbc.connect('DRIVER={SQL Server};SERVER=127.0.0.1;DATABASE=SPDG;UID=sa;PWD=yourpassword')
cursor = cnxn.cursor()随便执行一个命令看看效果:
cursor.execute("SELECT * FROM SPB")
row = cursor.fetchall()
print(row)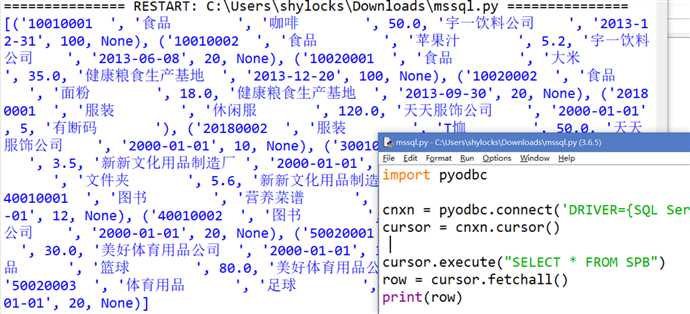
标签:request 服务器 选择 find uri 前言 简单 env pass
原文地址:https://www.cnblogs.com/shy-/p/9157911.html