标签:href 一个 code 优先级 为什么 地址 point 有一个 exp
想了好久索引的重要性应该怎么写?讲原理结构?我估计大部分人不愿意看,也不愿意花那么多时间仔细研究。光写应用?感觉不明白原理一样不会用。举例说明?情况太多也写不全....到底该怎么写呢?
随便写吧,想到哪写到哪!
前面很多篇不管CPU、内存、磁盘、语句等等等都提到了索引的重要,我想刚刚开始学数据库的在校学生都知道索引对语句性能的重要性。但他们可能不知道,对语句的重要性就是对系统的重要性!
抛出一个问题 :你相信一条语句就能让你的大系统挂掉么?
--------------博客地址---------------------------------------------------------------------------------------
Expert 诊断优化系列 http://www.cnblogs.com/double-K/
废话不多说,直接开整-----------------------------------------------------------------------------------------
下面这样一个小SQL 你该怎么样添加最优索引
两个表上现在只有聚集索引
bigproduct 表上已经有聚集索引 ProductID
bigtransactionhistory 表上已经有聚集索引 TransactionID
select p.productnumber,p.reorderpoint,th.Quantity from bigproduct as p join bigtransactionhistory as th on th.productid=p.productid and th.TransactionDate > p.SellStartDate where p.name in (‘LL Crankarm1000‘,‘ML Crankarm1000‘) and th.TransactionDate > ‘2010-01-01‘
你是否一眼就能看出来呢?
答案将在文章中逐步揭晓~~~
看过我前面文章的看官们一定会发现我很喜欢用“简单粗暴”这个词,一是因为词汇量小文笔也差,真心用不出高大上的词儿! 再一个,你们不喜欢简单粗暴么~~干货最重要,不是么?
首先我们看一下没有优化前的执行计划
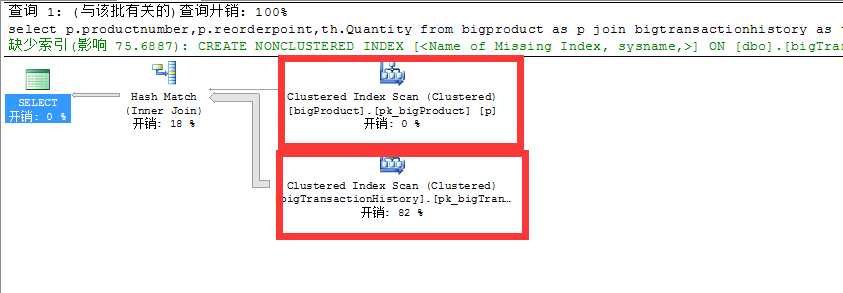

clustered index scan 这其实就是表扫描,不是table scan 只是因为表上有聚集索引
可以看出这个查询俩表都使用了表扫描!
where 条件添加索引
首先大多数人都知道 where 条件中的字段需要添加索引! 我们添加一下看看效果创建
在 bigproduct 表上创建 name 列索引 ,在bigtransactionhistory表上创建 TransactionDate 列索引。
再次执行语句看一下效果!
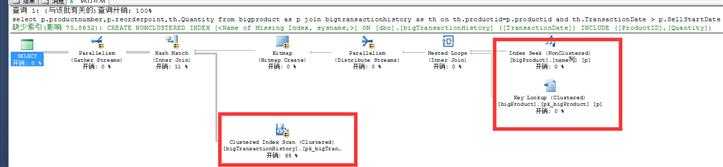

添加where索引以后可以看到以下几个现象
解释一下出现的现象 : 首先一点bigproduct 边添加的where 条件索引,起到了作用,执行的时候不是全表扫描了,逻辑读有明显的下降,出现的 KEY Lookup 是因为选择(select)的列,在索引中没有,而需要通过聚集索引再查找一次,再找一次也意味着多一部分开销!
那么同样添加了where 条件索引的bigtransactionhistory 表为什么没起作用呢? 那是因为SQL优化器在选择计划的时候认为,不使用TransactionDate 列索引查找效率会更好!
真的么? 我们来验证一下,通过指定选择索引,来让优化器选择索引查找!
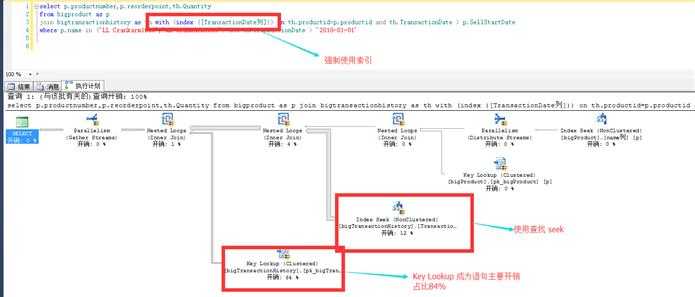

强制使用索引以后,可以看出逻辑读由 14W 变成1961W,语句时间也变得很长,这就是优化器为什么不选用你加的索引!优化器还是很智能的吧。
高能预警:优化器可不是什么时候都这么智能的...由于缓存计划或优化器抽风等原因,也会出现优化器用了这种索引,导致你的语句奇慢,读飙升直接影响到你的内存、磁盘、CPU资源!另外如果这样一条语句是系统中一条很频繁运行的语句,你的系统就挂了!没错就挂了!这就是开篇抛出的问题就是因为一条语句!
消灭Key Lookup 添加select 字段
这就是传说中的覆盖索引!
看到执行计划中存在Key Lookup 而且消耗占比很高,如上面强制索引的计划,那么我们就要想到的 在索引中包含那些SELECT 的列!如果消耗低,逻辑读少,如上面bigproduct 表中的Key Lookup 就可以忽略(如果你追求完美,也一样优化就可以了)。
包含列的图形化创建 : @秋仙 特意给你的说明
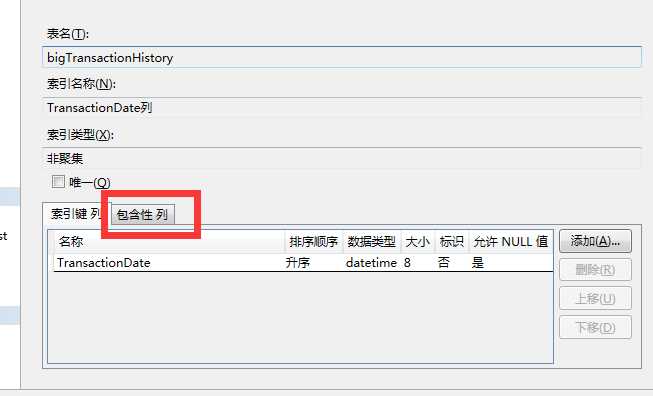
语句创建就是 :

CREATE NONCLUSTERED INDEX TransactionDate包含ProductID_Quantity ON [dbo].[bigTransactionHistory] ([TransactionDate]) ------INCLUDE 就是包含列 INCLUDE ([ProductID],[Quantity]) GO
下面我们添加一下看看效果 :
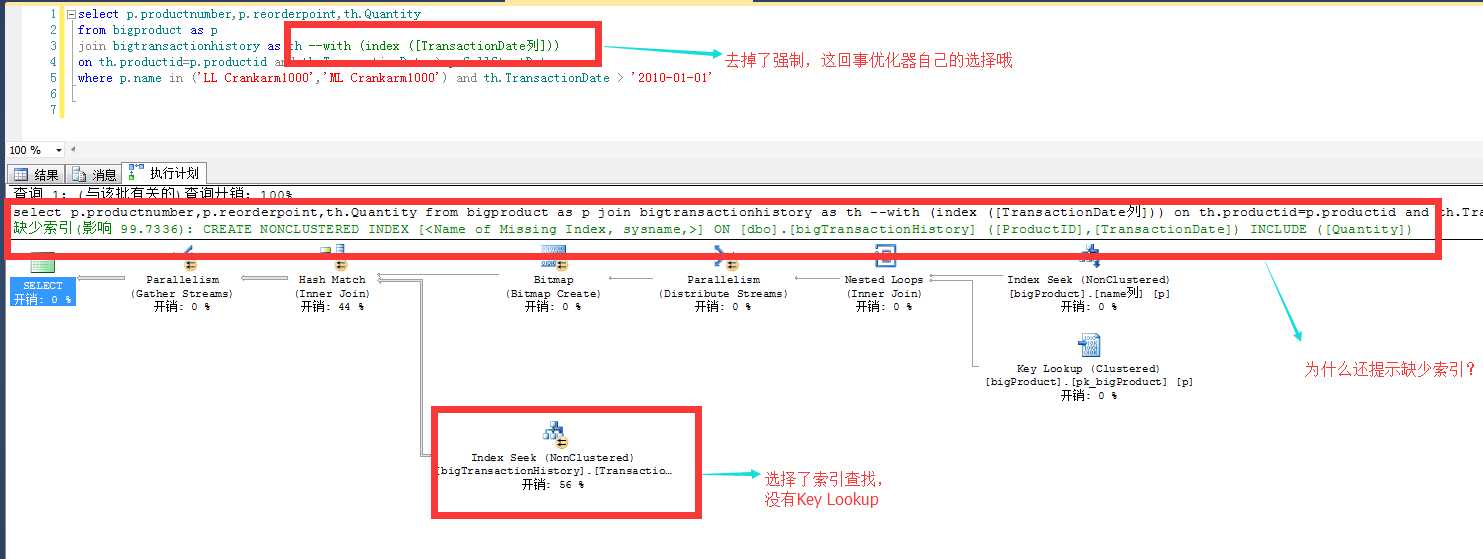

添加select 索引字段后可以看出的现象:
通过优化索引添加select 字段,我们看出语句又一次得到了提升 bigtransactionhistory 从表扫描变成索引查找,逻辑读由14W变成 1W!这是一个质的飞跃啊!
CREATE NONCLUSTERED INDEX TransactionDate包含ProductID_Quantity ON [dbo].[bigTransactionHistory] ([TransactionDate]) ------INCLUDE 就是包含列 INCLUDE ([ProductID],[Quantity]) GO
那为什么还提示缺少索引呢? 创建一下试试吧!
索引再优化加入表关联列
按照提示我们创建索引 : 和上一个索引的不同 ProductID 列由包含列变成了索引列!
USE [AdventureWorks2012] GO CREATE NONCLUSTERED INDEX ProductID_TransactionDate包含Quantity ON [dbo].[bigTransactionHistory] ([ProductID],[TransactionDate]) INCLUDE ([Quantity])
我们看一下效果:
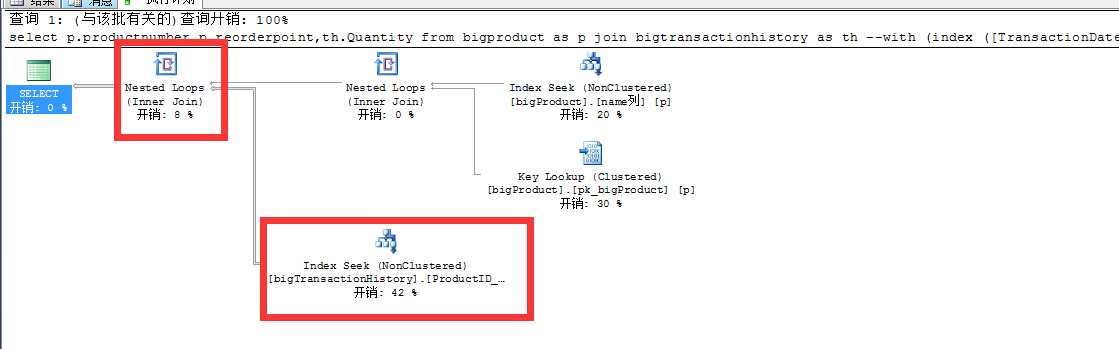

再次优化索引以后可以看到以下几个现象
又一次质的飞跃!读从原来的14W 变成1W 又变成18,这样大大减少了内存和IO的消耗,另外并行计划也变成了串行,无疑又减少了大量CPU的消耗!语句时间,我想这里就不用多说了吧?
高能预警:这里所说的hash join,并行变串行,不懂的朋友可以在百度自行学习,这里只是针对当前语句的情况,不能一概而论!
精简你的索引
大家都知道,索引会导致update、insert、delete操作变慢!那么尽量精简你的索引就是一个很重要的话题了!
上面的优化过程中我们创建了几个索引,以bigTransactionHistory为例来看一下:

脚本这里就不贴了,其实我们最后创建的索引 ProductID_TransactionDate包含Quantity 已经包含了前两个索引,而且可以说无论任何类似语句都使用ProductID_TransactionDate包含Quantity 就可以了!
那么我们就可以清除前两个索引!
--------------博客地址---------------------------------------------------------------------------------------
Expert 诊断优化系列 http://www.cnblogs.com/double-K/
-----------------------------------------------------------------------------------------------------
至此语句的优化算是结束了,留下的就是bigproduct 依然有一个Key Lookup可以优化,可以仿照上面的继续优化,这里就不细说了。语句只是经过了简单的索引优化就从一辆2手QQ变成了法拉利,是不是很神奇?
这就是索引的重要性!
开篇小测试你做对了么?如果没做对那么这么请你自行模拟一个场景再现本篇的话题吧!
-----------------------------------------------------------------------------------------------------
总结 : 往往一个系统的整体缓慢都是因为索引问题导致的,优化索引是对你系统最简单的保养!
不要小看一条语句的威力,一条语句足可以让你的系统彻底无法工作!
一个问题随之而来语句一条一条漫无目的的优化么?我怎么找出系统的问题语句?怎么样的一个优先级?
请参见前文 : Expert 诊断优化系列------------------语句调优三板斧
后一篇我将使用 Expert for sqlserver 工具讲述怎么样针对重点语句调索引,喜欢的看官请mark了!
----------------------------------------------------------------------------------------------------
原创链接:http://www.cnblogs.com/double-K/archive/2016/06/02/5538249.html
为了方便阅读给出系列文章的导读链接:
----------------------深入索引原理推荐博客--------------------------
目测这几篇文章每篇的编写时间都要超过10小时,非常值得阅读!
pursuer.chen 的博客
桦仔的博客
下面这样一个小SQL 你该怎么样添加最优索引
两个表上现在只有聚集索引
bigproduct 表上已经有聚集索引 ProductID
bigtransactionhistory 表上已经有聚集索引 TransactionID
select p.productnumber,p.reorderpoint,th.Quantity from bigproduct as p join bigtransactionhistory as th on th.productid=p.productid and th.TransactionDate > p.SellStartDate where p.name in (‘LL Crankarm1000‘,‘ML Crankarm1000‘) and th.TransactionDate > ‘2010-01-01‘
你是否一眼就能看出来呢?
答案将在文章中逐步揭晓~~~
看过我前面文章的看官们一定会发现我很喜欢用“简单粗暴”这个词,一是因为词汇量小文笔也差,真心用不出高大上的词儿! 再一个,你们不喜欢简单粗暴么~~干货最重要,不是么?
首先我们看一下没有优化前的执行计划
clustered index scan 这其实就是表扫描,不是table scan 只是因为表上有聚集索引
可以看出这个查询俩表都使用了表扫描!
where 条件添加索引
首先大多数人都知道 where 条件中的字段需要添加索引! 我们添加一下看看效果创建
在 bigproduct 表上创建 name 列索引 ,在bigtransactionhistory表上创建 TransactionDate 列索引。
再次执行语句看一下效果!
添加where索引以后可以看到以下几个现象
解释一下出现的现象 : 首先一点bigproduct 边添加的where 条件索引,起到了作用,执行的时候不是全表扫描了,逻辑读有明显的下降,出现的 KEY Lookup 是因为选择(select)的列,在索引中没有,而需要通过聚集索引再查找一次,再找一次也意味着多一部分开销!
那么同样添加了where 条件索引的bigtransactionhistory 表为什么没起作用呢? 那是因为SQL优化器在选择计划的时候认为,不使用TransactionDate 列索引查找效率会更好!
真的么? 我们来验证一下,通过指定选择索引,来让优化器选择索引查找!
强制使用索引以后,可以看出逻辑读由 14W 变成1961W,语句时间也变得很长,这就是优化器为什么不选用你加的索引!优化器还是很智能的吧。
高能预警:优化器可不是什么时候都这么智能的...由于缓存计划或优化器抽风等原因,也会出现优化器用了这种索引,导致你的语句奇慢,读飙升直接影响到你的内存、磁盘、CPU资源!另外如果这样一条语句是系统中一条很频繁运行的语句,你的系统就挂了!没错就挂了!这就是开篇抛出的问题就是因为一条语句!
消灭Key Lookup 添加select 字段
这就是传说中的覆盖索引!
看到执行计划中存在Key Lookup 而且消耗占比很高,如上面强制索引的计划,那么我们就要想到的 在索引中包含那些SELECT 的列!如果消耗低,逻辑读少,如上面bigproduct 表中的Key Lookup 就可以忽略(如果你追求完美,也一样优化就可以了)。
包含列的图形化创建 : @秋仙 特意给你的说明
语句创建就是 :
CREATE NONCLUSTERED INDEX TransactionDate包含ProductID_Quantity ON [dbo].[bigTransactionHistory] ([TransactionDate]) ------INCLUDE 就是包含列 INCLUDE ([ProductID],[Quantity]) GO
下面我们添加一下看看效果 :
添加select 索引字段后可以看出的现象:
通过优化索引添加select 字段,我们看出语句又一次得到了提升 bigtransactionhistory 从表扫描变成索引查找,逻辑读由14W变成 1W!这是一个质的飞跃啊!
CREATE NONCLUSTERED INDEX TransactionDate包含ProductID_Quantity ON [dbo].[bigTransactionHistory] ([TransactionDate]) ------INCLUDE 就是包含列 INCLUDE ([ProductID],[Quantity]) GO
那为什么还提示缺少索引呢? 创建一下试试吧!
索引再优化加入表关联列
按照提示我们创建索引 : 和上一个索引的不同 ProductID 列由包含列变成了索引列!
USE [AdventureWorks2012] GO CREATE NONCLUSTERED INDEX ProductID_TransactionDate包含Quantity ON [dbo].[bigTransactionHistory] ([ProductID],[TransactionDate]) INCLUDE ([Quantity])
我们看一下效果:
再次优化索引以后可以看到以下几个现象
又一次质的飞跃!读从原来的14W 变成1W 又变成18,这样大大减少了内存和IO的消耗,另外并行计划也变成了串行,无疑又减少了大量CPU的消耗!语句时间,我想这里就不用多说了吧?
高能预警:这里所说的hash join,并行变串行,不懂的朋友可以在百度自行学习,这里只是针对当前语句的情况,不能一概而论!
精简你的索引
大家都知道,索引会导致update、insert、delete操作变慢!那么尽量精简你的索引就是一个很重要的话题了!
上面的优化过程中我们创建了几个索引,以bigTransactionHistory为例来看一下:
脚本这里就不贴了,其实我们最后创建的索引 ProductID_TransactionDate包含Quantity 已经包含了前两个索引,而且可以说无论任何类似语句都使用ProductID_TransactionDate包含Quantity 就可以了!
那么我们就可以清除前两个索引!
--------------博客地址---------------------------------------------------------------------------------------
Expert 诊断优化系列 http://www.cnblogs.com/double-K/
-----------------------------------------------------------------------------------------------------
至此语句的优化算是结束了,留下的就是bigproduct 依然有一个Key Lookup可以优化,可以仿照上面的继续优化,这里就不细说了。语句只是经过了简单的索引优化就从一辆2手QQ变成了法拉利,是不是很神奇?
这就是索引的重要性!
开篇小测试你做对了么?如果没做对那么这么请你自行模拟一个场景再现本篇的话题吧!
-----------------------------------------------------------------------------------------------------
总结 : 往往一个系统的整体缓慢都是因为索引问题导致的,优化索引是对你系统最简单的保养!
不要小看一条语句的威力,一条语句足可以让你的系统彻底无法工作!
一个问题随之而来语句一条一条漫无目的的优化么?我怎么找出系统的问题语句?怎么样的一个优先级?
请参见前文 : Expert 诊断优化系列------------------语句调优三板斧
后一篇我将使用 Expert for sqlserver 工具讲述怎么样针对重点语句调索引,喜欢的看官请mark了!
----------------------------------------------------------------------------------------------------
原创链接:http://www.cnblogs.com/double-K/archive/2016/06/02/5538249.html
为了方便阅读给出系列文章的导读链接:
----------------------深入索引原理推荐博客--------------------------
目测这几篇文章每篇的编写时间都要超过10小时,非常值得阅读!
pursuer.chen 的博客
桦仔的博客
标签:href 一个 code 优先级 为什么 地址 point 有一个 exp
原文地址:https://www.cnblogs.com/binghou/p/9171679.html