标签:statistic 分享图片 growth font tin replica detail primary 行操作
概述:sql server是以文件形式存储数据与日志
1.数据文件
sql server数据文件分为2类
(1)主数据库文件
主数据库文件包含数据库的启动信息、系统对象,并指向数据库的其他文件(从数据文件),主数据文件也可以存用户数据和对象。每个数据库必须且只能有一个主数据文件,其后缀名为.mdf。
(2)从数据文件
由用户自定义而成,用户存储用户数据与对象,其后缀名为.ndf.
(3)文件组的概念
分为2类
【1】主文件组
主文件组的名称是primary,它包含主要文件,以及未放入用户定义文件组的任何次要文件,所有系统表都会被分配到主文件组中,如果不指定文件组,默认也是放入主文件组中。
默认文件组可以通过Alter database语句设置为primary之外的文件组,但是任何时候一个数据库都只能有一个默认文件组。
【2】用户定义文件组
用户定义文件组由用户在首次创建数据库时创建,或者是数据库创建后,通过修改数据库的方式创建。
sql server数据库中读取和存储数据时,不以数据文件为单位,而是以文件组为单位进行操作。数据库中的每个对象都存储在某个文件组上(而不是数据库文件上),每个文件组包含至少一个数据文件。
使用文件组而不是数据文件的好处在于:可以简化管理,增加可管理的数据文件的数目;逻辑上管理好数据库文件的分部与使用;另一方面可以突破系统的一些限制,例如:两个可用于存储数据的磁盘,但他们的大小都不足以存储整个数据库,则可以在两个磁盘上各建立一个数据文件,并加入到同一个文件组中,这样就可以同时使用2个磁盘的空间。
使用多个文件的好处
在大多数情况下,小型的数据库并不需要创建多个文件来存放数据。但是随着数据的增长,单个文件的弊端就会出现。
如何创建多文件与文件组?

--1.用创建数据库的方式创建文件与文件组
-- Create a new database CREATE DATABASE MultipleFileGroups ON PRIMARY ( -- Primary File Group NAME = ‘MultipleFileGroups‘, FILENAME = ‘C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\MultipleFileGroups.mdf‘, SIZE = 5MB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ), -- Secondary File Group FILEGROUP FileGroup1 ( -- 1st file in the first secondary File Group NAME = ‘MultipleFileGroups1‘, FILENAME = ‘C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\MultipleFileGroups1.ndf‘, SIZE = 1MB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ), ( -- 2nd file in the first secondary File Group NAME = ‘MultipleFileGroups2‘, FILENAME = ‘C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\MultipleFileGroups2.ndf‘, SIZE = 1MB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ) LOG ON ( -- Log File NAME = ‘MultipleFileGroups_Log‘, FILENAME = ‘C:\Program Files\Microsoft SQL Server\MSSQL11.SQL2012\MSSQL\DATA\MultipleFileGroups.ldf‘, SIZE = 5MB, MAXSIZE = UNLIMITED, FILEGROWTH = 1024KB ) GO
--2.创建文件组 ALTER DATABASE [Test] ADD FILEGROUP [FG_Test_Id_01] ALTER DATABASE [Test] ADD FILEGROUP [FG_Test_Id_02]
--3.创建文件 ALTER DATABASE [Test] ADD FILE (NAME = N‘FG_TestUnique_Id_01_data‘,FILENAME = N‘E:\FG_TestUnique_Id_01_data.ndf‘,SIZE = 1MB, FILEGROWTH = 1MB ) TO FILEGROUP [FG_Test_Id_01]; ALTER DATABASE [Test] ADD FILE (NAME = N‘FG_TestUnique_Id_02_data‘,FILENAME = N‘E:\FG_TestUnique_Id_02_data.ndf‘,SIZE = 1MB, FILEGROWTH = 1MB ) TO FILEGROUP [FG_Test_Id_02];
如何把表或索引放到特定的文件组?如何建立文件组
CREATE TABLE Customers ( FirstName CHAR(50) NOT NULL, LastName CHAR(50) NOT NULL, Address CHAR(100) NOT NULL, ZipCode CHAR(5) NOT NULL, Rating INT NOT NULL, ModifiedDate DATETIME NOT NULL, ) ON [FileGroup1] GO
如何标记特定文件组为默认文件组?
-- FileGroup1 gets the default filegroup, where new database objects -- will be created ALTER DATABASE MultipleFileGroups MODIFY FILEGROUP FileGroup1 DEFAULT GO
这是我通常推荐的方法,因为你不需要再考虑,在创建完你的数据库对象后。因此现在让我们创建一个新的表,它会自动存储在FileGroup1文件组。
-- The table will be created in the file group "FileGroup1"
CREATE TABLE Test
(
Filler CHAR(8000)
)
GO
现在我们进行简单的测试:我们插入40000条记录到表。每条记录8K大小。因此我们插入了320MB数据到表。这是我刚才提的轮询调度分配算法,会进行操作:SQL Server会在2个文件间发放数据:第一个文件有160M的数据,第二个文件也会有160M的数据。
-- Insert 40.000 records, results in about 312MB data (40.000 x 8KB / 1024 = 312,5MB)
-- They are distributed in a round-robin fashion between the files in the file group "FileGroup1"
-- Each file will get about 160MB
DECLARE @i INT = 1
WHILE (@i <= 40000)
BEGIN
INSERT INTO Test VALUES
(
REPLICATE(‘x‘, 8000)
)
SET @i += 1
END
GO
接下来你可以在硬盘上看下,你会看到2个文件时同样的大小。
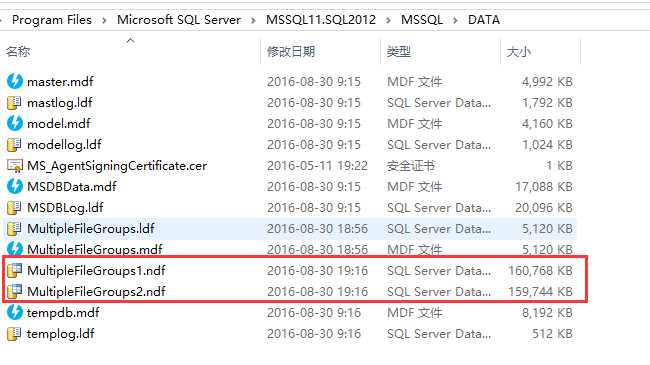
当你把这些文件放在不同的物理硬盘上,你可以同时访问它们。那就是在一个文件组里有多个文件的强大。
你也可以使用下列脚本获取数据库文件的相关信息。
-- Retrieve file statistics information about the created database files
DECLARE @dbId INT
SELECT @dbId = database_id FROM sys.databases WHERE name = ‘MultipleFileGroups‘
SELECT
sys.database_files.type_desc,
sys.database_files.physical_name,
sys.dm_io_virtual_file_stats.* FROM sys.dm_io_virtual_file_stats
(
@dbId,
NULL
)
INNER JOIN sys.database_files ON sys.database_files.file_id = sys.dm_io_virtual_file_stats.file_id
GO
参考文章:
https://www.sqlpassion.at/archive/2016/08/29/files-and-file-groups-in-sql-server/
(2)https://www.cnblogs.com/lyhabc/p/3480917.html (精品推荐)
标签:statistic 分享图片 growth font tin replica detail primary 行操作
原文地址:https://www.cnblogs.com/gered/p/9175134.html