标签:multi 单个字符 大小写 不同 单词 结束 表达式 索引 循环
正则表达式的写法:
var reg = new RegExp("str","gim"); new正则对象
var reg1 = /str/gim; 正则字面量(常用)
g 全局匹配
i 不区分大小写
m 执行多行匹配
根据需求选择: i im img ig gm g m
比较new RegExp()与RegExp():
当我们在new正则对象,里面传递的参数是正则对象时,如:var reg2 = new RegExp(reg1,‘g‘),此时生成的是一个新的正则对象,也就是reg2 === reg1 返回false;
我们不用new时,直接写RegExp(),如:var reg3 = RegExp(reg1,‘g‘),此时没有生成新的对象,reg3的值还是原来的正则对象,reg3 === reg1 返回true;
正则字面量:
var reg = /[abcde]/; 一个[]表示一个字符,匹配abcde中的任意一个字符
var reg = /[a-z]/; "-"写在范围中间,就认为成一个区间,如需匹配“-”,不要将它写在中间就行;匹配所有的小写字母中的一个
var reg = /[^abc]/; "^"写在[]里表示取反,匹配除了abc字符外的所有字符中的一个
var reg = /^[abc]/; ”^“写在[]外面表示以它后面的字符为开头,也就是abc中谁是字符串的开头,就匹配谁
var reg = /a$/; ”^“写在a后面,表示以a结尾
var reg = /[u4e00-u9fa5]/; 匹配所有的汉字中的一个
(元字符)
var reg = /./; "."查找单个字符,除了换行和行结束符 /[^\n\r]/
var reg = /\w/; "\w"查找单个的单词字符,含字母数字下划线 /[A-z0-9_]/
var reg = /\W/; "\W"查找单个的非单词字符 /[^\w]/ /[^A-z0-9_]/
var reg = /\d/; "\d"查找数字 /[0-9]/
var reg = /\D/; "\D"查找非数字字符 /[^\d]/ /[^0-9]/
var reg = /\s/; "\s"查找空白字符 /[\r\f\t\v\n ]/
var reg = /\S/; "\S"查找非空白字符 /[^\s]/
var reg = /\b/; "\b"匹配单词边界 /a\b/ 字符a的后面为空,则匹配a
var reg = /\B/; "\B"匹配非单词边界 /[^\b]/
var reg = /\n/; "\n"查找换行符
(量词)
/n{x}/ "{x}"匹配x次,x=1 》 /n/; x=2 》 /nn/; x=3 》 /nnn/ (当x为0时;)
/n{x,y}/ "{x,y}"匹配x-y之间任意次,因为正则表达式是贪婪模式,它会优先匹配y次,不足y次,则匹配y-1次,依次递减到x次为止
/n{x,}/ "{x,}"匹配最少出现x次
/n+/ "+"匹配任何包含至少一个 n 的字符串 /n{1,}/
/n*/ "*"匹配任何包含零个或多个 n 的字符串 /n{0,}/
/n?/ "?"匹配任何包含零个或一个 n 的字符串 /a{0,1}/
示例:
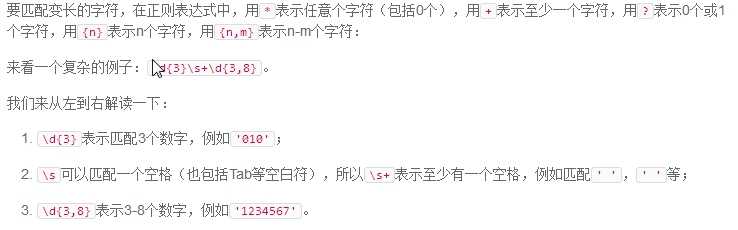
/n(?=a)/ "?=" 匹配后面紧接着指定字符串a的n字符
/n(?!a)/ "?!" 匹配后面没有紧接着指定字符串a的n字符
reg.global 判断RegExp 对象是否具有标志 g 返回boolead值
reg.ignoreCase 判断RegExp 对象是否具有标志 i 返回boolead值
reg.multiline 判断RegExp 对象是否具有标志 m 返回boolead值
reg.source 返回正则表达式的源文本
reg.lastIndex 用于规定下次匹配的起始位置
重要事项:不具有标志 g 和不表示全局模式的 RegExp 对象不能使用 lastIndex 属性。
提示:如果在成功地匹配了某个字符串之后就开始检索另一个新的字符串,需要手动地把这个属性设置为 0。
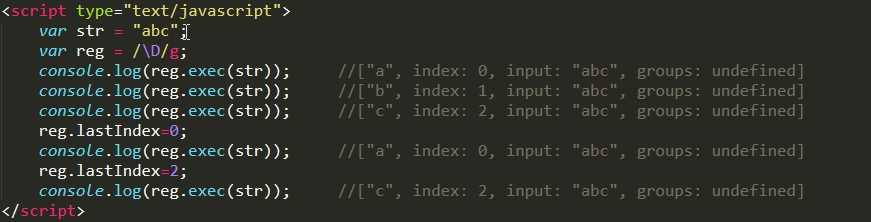
reg.exec(string) 用于检索字符串中的正则表达式的匹配,返回一个数组,其中存放匹配的结果。如果未找到匹配,则返回值为 null。
重要事项:如果在一个字符串中完成了一次模式匹配之后要开始检索新的字符串,就必须手动地把 lastIndex 属性重置为 0。
提示:请注意,无论 RegExpObject 是否是全局模式,exec() 都会把完整的细节添加到它返回的数组中。这就是 exec() 与 String.match() 的不同之处,后者在全局模式下返回的信息要少得多。因此我们可以这么说,在循环中反复地调用 exec() 方法是唯一一种获得全局模式的完整模式匹配信息的方法。
reg.test(string) 如果存在返回true,如果不存在返回false
reg.compile(正则表达式,[img]) 重新编译正则表达式
reg = /\d/g; reg = /[123]/g; reg.compile(reg) //用后面的(reg = /[123]/g;)替换了前面的(reg = /\d/g;)
string.match() 找到一个或多个正则表达式的匹配
string.search() 匹配到了就返回对应的索引值,没有匹配到就返回-1;
string.replace(正则,"替换的内容") 将正则表达式匹配到的内容进行替换,并返回替换后新的字符串
贪婪模式和非贪婪模式
贪婪模式:正则表达式本就是贪婪模式,尽量往多的匹配
非贪婪模式: 在量词后加"?" 例如 /\d{3,6}?/g
var str = "12345678912";
var reg = /\d{3,6}?/g;
console.log(str.match(reg));//["123", "456", "789"]
标签:multi 单个字符 大小写 不同 单词 结束 表达式 索引 循环
原文地址:https://www.cnblogs.com/d-laowu/p/9171354.html