标签:更新 详细 符号 操作 人气 不可 结合 法则 alt
在上一篇文章中,介绍了在GC机制中,GC是以什么标准判定对象可以被标记的,以及最有效最常用的可达性分析法。
今天介绍另外一种非常常用的标记算法,它的应用面也相当广泛。这就是:
引用计数法 Reference Counting
这个算法的本质,其实就是上篇文章中判断一个对象要被回收的另外一种思路,即如果没有其它对象调用当前对象,那么当前对象就可以被回收了。判断有多少调用当前对象有两种方法,一种是看看其它对象,有多少对象持有当前对象的引用。还有一种办法就是,当前对象自身实现一个计数机制。统计来自外界引用的调用。第一个办法就是上篇文章中可达性分析的最初思路。而第二个办法就是现在要介绍的引用计数法的最初思路:我们不关心谁保存了我们的引用,我们只关心保存我们引用的对象究竟有多少个。
在引用计数法中,每个对象拥有一个记录自身引用被持有的个数,当这个对象的计数器的值为0时,也就是不再有其它对象持有该对象的引用了,那么也就是不再有对象可以调用到当前对象的方法或者变量了。这一刻也就是当前对象可以被回收的时刻了。
在《垃圾回收的算法与实现》这本书中,对于该算法又一个很有意思的描述;
每个对象就像是一个明星。这个对象的引用计数的大小,就像是这个明星的人气指数。当明星的人气指数为0时,也就是这个明星黯然离场的时候了。
在引用计数法中,每个对象的引用计数器初始(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )值为0。没当有一个新对象持有当前对象的引用时,计数器就会加1。没当有一个已经持有引用的对象消失,或者抛弃持有的引用时。计数器就会-1。当计数器的值再次为0,这个计数器所代表的对象就会被回收掉。(更准确的说,是会让空闲链表持有自己的引用,将自己所占用的内存空间标记为可以重新分配的区域)。
接下来说说这个算法的优缺点:
优点:
1、随时随地的回收垃圾
当计数器变为0的瞬间,当前对象就会被放置到空闲队列中,作为可以被重新分配的内存空间。而其他的GC算法,如之前讲到的可达性分析法,都需要进行一次全局的清理,才会统一的清理掉这个周期内的所有已知的垃圾空间。
2、最大暂停时间短
引用计数法师在每次生成、或销毁对象或者是变更指针的时候进行一次计算的,因此对程序的影响时间是非常短暂的。
而其他的GC算法则由于需要统一的清除或者是复制等,所以暂停的时间会比较长,对程序的影响也比较长。有时这个时间长到性能上已经无法忍受时,就需要不断的调优,减短单次暂停的最大时长。
3、核心思路简单
引用计数法。不需要从根节点依次开始进行遍历。每个对象只关心直接持有自己引用的对象是否发生了变化。这样当对象发生回收时,也只影响这个对象直接持有的引用对象,而不会直接影响到更深路径的对象。
如A持有B/C,B持有D/E。当A被回收时,只会影响B,C对象的引用计数器。当B的计数器值因此降为0时,才会影响到D/E节点。整体的计算成本非常的低。而其他的GC方式需要从根依次进行遍历。整个过程非常复杂(如涉及到一个网状的引用关系,如何终止掉无意义的遍历就尤为重要)。
缺点:
1、计算的频率过快
每次执行一条命令时,都可能会引起若干次的引用计数变化。尤其是对于一些根节点持有的对象(从根对象)的引用计数,其变化的速度更是惊人。因此计数器的工作量非常繁重。
2、计数器所占用的内存空间非常的大
引用计数法中。每个对象都需要一个属于自己的引用计数器,尽管这个计数器使用无符号型来存储,但是也只能节约一个bit位的空间。由于可能会发生所有对象都持有一个对象的极端条件,所以计数器所允许的最大值一定是要非常大。(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )相应的所占用的控件也会非常的大。这是一种是典型的空间换取时间的算法。
3、实现非常复杂,一旦出错后果会非常的严重
尽管该算法的优点是思路非常简单,但是实现起来却要复杂的多。每当一个对象回收时,都需要刷新每一处使用到的对象的计数器。一旦有一处错误,则可能会出现永远无法修复的内存泄露问题。
4、循环依赖
这个问题可以是引用计数法被公认的最难处理问题:当两个(也可以使是多个)内存对象互相依赖,同时也不与外界有引用关系,从而形成一种类似孤岛链的关系。此时每一个对象计数器都不为0,GC也就无法回收掉这些内存了。这种情况下,典型的引用计数法是无法解决掉的。往往需要结合其他的回收算法,进行改良才能解决问题。
针对这些缺点。业界提供了很多的改良算法
1、延迟引用计数法 Deffered Reference Counting
deferred [d?‘f?:d] adj. 延期的,缓召的;
针对从根对象的引用非常频繁的更新,从而导致其计数器的计算任务非常繁重的这个问题。有人提出了一种特别的思路:不维护从根引用对象的计数器。这些计数器的值始终为0。其他对象仍然正常采用引用计数器的方式。但是这就会有一个问题,GC无法判断哪些对象是可以回收的,哪些是不能回收。因此就需要把计数器降为0(decr_ref_cnt函数)的对象暂时先放置在一个容器中,延迟它的回收。这个容器称为ZCT(Zero Count Table)。它专门用来记录那些计数器经过减持计算而变为0的对象。
如下图:
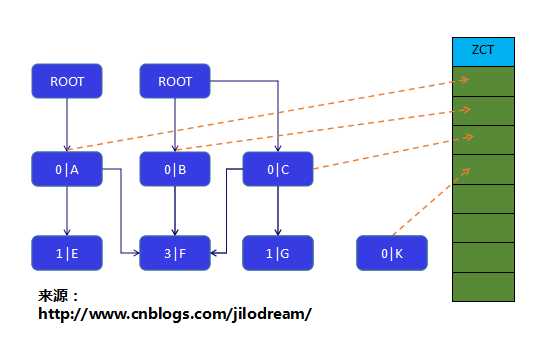
那么什么时候开始真正的标记垃圾对象呢?
一般来说当我们创建(new_obj函数)对象时,发现已经没有空余的内存空间可以分配时。就会进行一次ZCT扫描(scan_zct函数)来清理掉这些对象。然后再次尝试分配内存,如果仍然不能成功,那么这时候就认为内存溢出了。
ZCT扫描(scan_zct函数)的步骤如下:
(1)首先将从根引用的计数器调整到正常的数值;
可见下图:
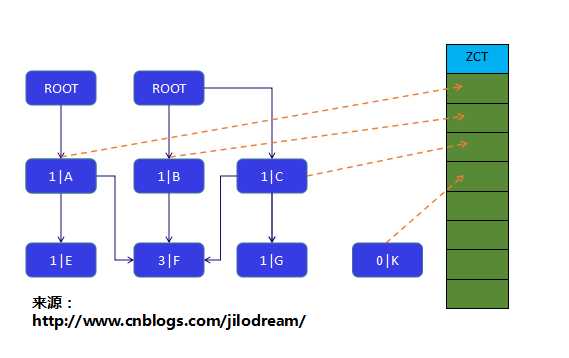
(2)然后遍历ZCT,将值为0的对象都清理掉(delete(obj)函数),放置到前文说的空闲队列中。(此时这些对象的空间就可以被用来分配新的对象了)
(3)然后将所有的从根引用的计数器再调整回去。
这个算法的好处是,废弃掉从根引用对象的计数器被频繁刷新这些无意义的繁重耗时的操作,大大减轻了处理器的负担。
当然它的缺点也很明显,内存不再会被立即回收掉。只有当内存空间不够时(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ ),才开始扫描ZCT,统一进行回收。而扫描ZCT的耗时一般会随着ZCT的增大而增大,这样就导致了GC的最大的暂停时间变大。当然也可以通过调小ZCT来减小最大暂停时间,但是这样又会让GC更频繁的进行ZCT扫描(空间与时间不可兼得)。从而导致内存回收处理的吞吐量下降。2、Sticky引用计数法
sticky 英 [?st?ki] adj. 粘性的; 不动的;
前文有提到计数器的控件占用非常的大。这是为了保证极端场景计数下,计数器可以正常使用。但这种算法却恰恰是将计数器所占用的空间(计数上限)缩小。这是因为对于大部分对象来说,计数器中所能达到的最大值都不大,对象很快就会被回收了。为了保证计数器每一个对象的计数器都不会溢出,而给每一个对象都开辟一块非常大的空间来计数,这是一种非常愚蠢的行为。
对于个别计数器会溢出的对象来说:
(1)那么就让它溢出好了
反正它都被这么多对象引用了,概率上讲,基本也不太会被回收了,可以说默认它为永生对象了。
(2)如果认为计数器溢出不好,可以加入从根寻址的变相算法,大致思路是这个样子的:
<1>计数器归0
<2>从根依次寻址,增加引用计数值
<3>清理掉引用计数器为0的对象
这个算法的好处是:
<1>降低计数器占用的空间
<2>清理掉循环引用的场景
3、1位引用计数算法
这个算法可以说是Sticky引用计数法的一种极端体现,也就是计数器只有1位。一旦出现共有一个内存的场景下就“溢出”了。
尽管场景很极端,但是他代表了很多的内存:这些对象从创造出来之后,只被一个对象持有,不存在多个对象共同持有的情况。
这种算法中,计数器更多像是一个标记值,标记当前对象是被其他对象引用,而不再是一个对象的计数器。
4、部分标记清除算法
这个算法可以说是纯粹就是为了解决循环依赖的。算法的大致思路如下:将内存对象标记为四种状态:
A绝对不是垃圾的对象;
B绝对是垃圾的对象;
C可能存在循环引用的对象;
D搜索完毕的对象。
这样就可以针对对象的状态采用不同的回收算法计算。由于内存中的大部分对象都处于循环引用的孤岛连之外(防盗连接:本文首发自http://www.cnblogs.com/jilodream/ )。因此大部分的对象仍然采用的是引用计数法进行计算。只有少部分的对象可能存在循环引用中,因此只对这部分对象进行进行根可达性的计算。
尽管引用计数法自身存在诸多的缺陷,但是仍然有很多地方采用了这种回收算法:如Python的GC、Flash player的内存管理等。可惜由于循环依赖等原因,到目前为止,主流的JVM还均没有将引用计数法作为GC的回收算法来使用。
对于这篇文章中提到的这些GC标记算法,以及这些GC标记算法的实现,在这里推荐一本前文提到的书:《垃圾回收的算法与实现》。这本书写的非常详细,书中的插图也非常形象。有兴趣的同学可以找来阅读下。
标签:更新 详细 符号 操作 人气 不可 结合 法则 alt
原文地址:https://www.cnblogs.com/jilodream/p/9180860.html