标签:end 占位符 地方 -- 种类 size section 基本运算符 and
1、通过%进行格式化输出
格式化输出是为了按照固定的格式对字符串等进行输出,因为涉及到外部输入或者因某一需求需要利用某一种模板进行输出,导致了需要利用%对某些输出内容进行占位。
现有格式化输出主要学习 %s 和 %d。
1 name = input("请输入名字:") 2 age = int(input("请输入年龄:")) 3 job = input("请输入工作:") 4 hobby = input("请输入爱好:") 5 print("""------------ info of %s ----------- 6 Name : %s 7 Age : %d 8 job : %s 9 Hobbie: %s 10 ------------- end -----------------""" % (name,name,age,job,hobby))
某些时候如果你的字符串中用了%s或者%d这种形式,那么后面的%会被认为是占位符,如果需要用到%,需要写成%%,表示对该%进行转义。
1 print("我叫%s,我学python的课程已经完成了2%%了。")
如果字符串中没有出现占位符,那么你的 % 还是你的 %,未发生任何变化。
1 print("我叫刘立明,我学python的课程已经完成了2%了。")
运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为算数运算、比较运算、逻辑运算、赋值运算、成员运算、身份运算、位运算,今天我们暂只学习算数运算、比较运算、逻辑运算、赋值运算
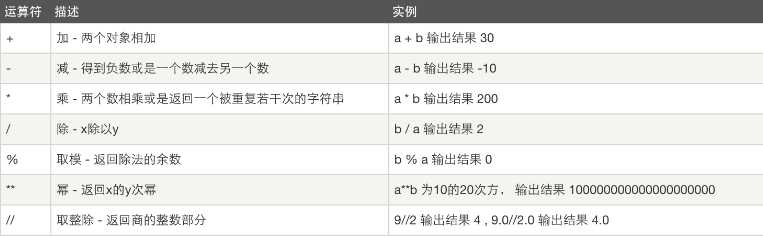
算数运算
以下假设变量:a=10,b=20
比较运算
以下假设变量:a=10,b=20

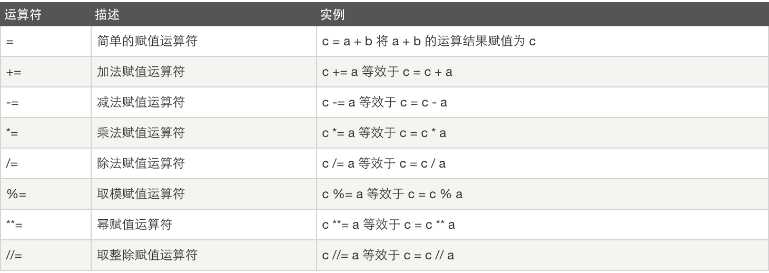
赋值运算
以下假设变量:a=10,b=20
逻辑运算

针对逻辑运算的进一步研究:
1,在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
例题:
判断下列逻辑语句的True,False。
3>4 or 4<3 and 1==1 1 < 2 and 3 < 4 or 1>2 2 > 1 and 3 < 4 or 4 > 5 and 2 < 1 1 > 2 and 3 < 4 or 4 > 5 and 2 > 1 or 9 < 8 1 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
not 2 > 1 and 3 < 4 or 4 > 5 and 2 > 1 and 9 > 8 or 7 < 6
2 , x or y , x为真,值就是x,x为假,值是y;
x and y, x为真,值是y,x为假,值是x。

例题:求出下列逻辑语句的值。
8 or 4 0 and 3 0 or 4 and 3 or 7 or 9 and 6
in,not in :
判断子元素是否在原字符串(字典,列表,集合)中:
例如:
#print(‘喜欢‘ in ‘dkfljadklf喜欢hfjdkas‘) #print(‘a‘ in ‘bcvd‘) #print(‘y‘ not in ‘ofkjdslaf‘)
编码是一项很重要的工作,可能目前的学习可能没有那么重要,但涉及到网络传输、前端等内容的时候就需要对编码有一个详细的了解,今天先来初识一下编码。
最早出现计算机的时候由美国创建了ASCII码,ASCII码不能装中文,8个bit组成,最多可有256种可能,美国使用了0-127,剩余留作扩展;
因为美国ASCII码中留了128个扩展,但相对于像中国这样的国家来说,128个无法完全表示汉字,因此中国在ASCII的基础上设计了GBK,GBK支持中文,16bit =>2byte。但这种扩展不能够在世界上通用,可能某一文件在中国能用,但到了其他地方就不一定通用了。
为了解决各个国家间对编码的标准同一,扩展出了unicode,简称万国码,目的是把所有国家的文字都进行编码,占32位。但是其缺点是浪费。ASCII码的内容是不能改变的,编码还应该是原来的编码,但unicode占用32个位置,ASCII会强制在前面补24个0。在网络传输和数据存储上会浪费空间。
为了解决unicode浪费的问题,于是有了一个可变长度的unicode编码,称为UTF-8,8的意思是一个字符最少8位。
英文:8bit 2byte
欧洲:16bit 2byte
中文:24bit 3byte
计算机存储系统单位换算
8bit => 1byte
1024byte => 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
python-fullstack-s13-day02-python基础
标签:end 占位符 地方 -- 种类 size section 基本运算符 and
原文地址:https://www.cnblogs.com/bug-ming/p/9116825.html