标签:简单 针对性 tutorials build 理解 sources bing analysis 新版
微软在Build 2018大会上推出的一款面向.NET开发人员的开源,跨平台机器学习框架ML.NET。 ML.NET将允许.NET开发人员开发他们自己的模型,并将自定义ML集成到他们的应用程序中,而无需事先掌握开发或调整机器学习模型的专业知识。在采用通用机器学习语言(如R和Python)开发的模型,并将它们集成到用C#等语言编写的企业应用程序中需要付出相当大的努力。ML.NET填平了机器学习专家和软件开发者之间的差距,从而使得机器学习的平民化,即使没有机器学习背景的人们能够建立和运行模型。通过为.NET创建高质量的机器学习框架,微软已经使得将机器学习转化为企业(或通过Xamarin移动应用程序)变得更容易。这是一种使机器学习更加可用的形式。
基于微软内部Windows,Bing和Azure等主要微软产品使用多年的机器学习构建的库目前处于预览阶段,最新版本是0.2 。该框架目前支持的学习模型包括
其他技术,如推荐引擎和异常检测,正在开发的路线图上。ML.NET将最终将接口暴露给其他流行的机器学习库,如TensorFlow,CNTK和Accord.NET。最后,还会有一些工具和语言增强功能,包括Azure和GUI / Visual Studio功能中的扩展功能。

ML.NET以NuGet包的形式提供,可以轻松安装到新的或现有的.NET应用程序中。
该框架采用了用于其他机器学习库(如scikit-learn和Apache Spark MLlib)的“管道(LearningPipeline)”方法。数据通过多个阶段“传送”以产生有用的结果(例如预测)。典型的管道可能涉及
管道为使用机器学习模型提供了一个标准API。这使得在测试和实验过程中更容易切换一个模型。它还将建模工作分解为定义明确的步骤,以便更容易理解现有代码。scikit-learn库实现了很多机器学习算法,我们可以多多参考scikit-learn :http://sklearn.apachecn.org/cn/0.19.0/index.html
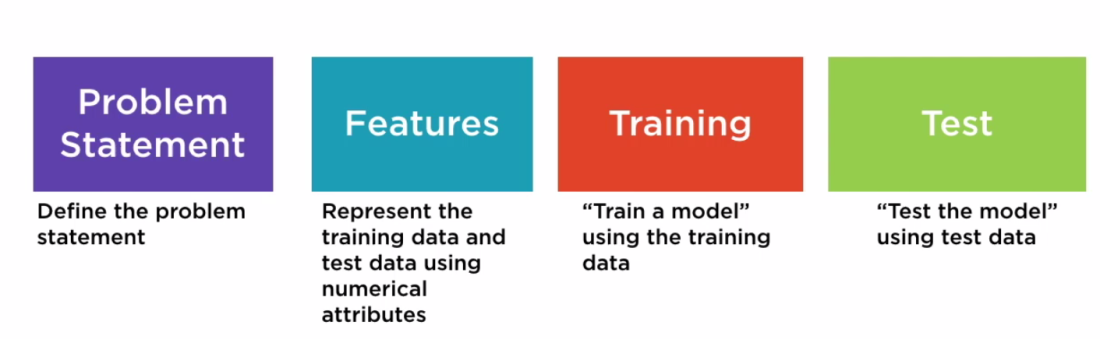
在构建机器学习模型时,首先需要定义您希望通过数据实现的目标。之后,您可以针对您的情况选择正确的机器学习任务。以下列表描述了您可以选择的不同机器学习任务以及一些常见用例。
二元分类属于 监督学习,用于预测数据的一个实例属于哪些两个类(类别)任务。分类算法的输入是一组标记示例,其中每个标记都是0或1的整数。二进制分类算法的输出是一个分类器,您可以使用该分类器来预测新的未标记实例的类。二元分类场景的例子包括:
将Twitter评论的情绪理解为“积极”或“消极”。
诊断患者是否患有某种疾病。
决定将电子邮件标记为“垃圾邮件”。
有关更多信息,请参阅Wikipedia上的二元分类 文章。
多元分类属于 监督学习,用于预测的数据的实例的类(类别)的任务。分类算法的输入是一组标记示例。每个标签都是0到k-1之间的整数,其中k是类的数量。分类算法的输出是一个分类器,您可以使用它来预测新的未标记实例的类。多类分类方案的例子包括:
有关更多信息,请参阅Wikipedia上的多类分类文章。
分类步骤设置:
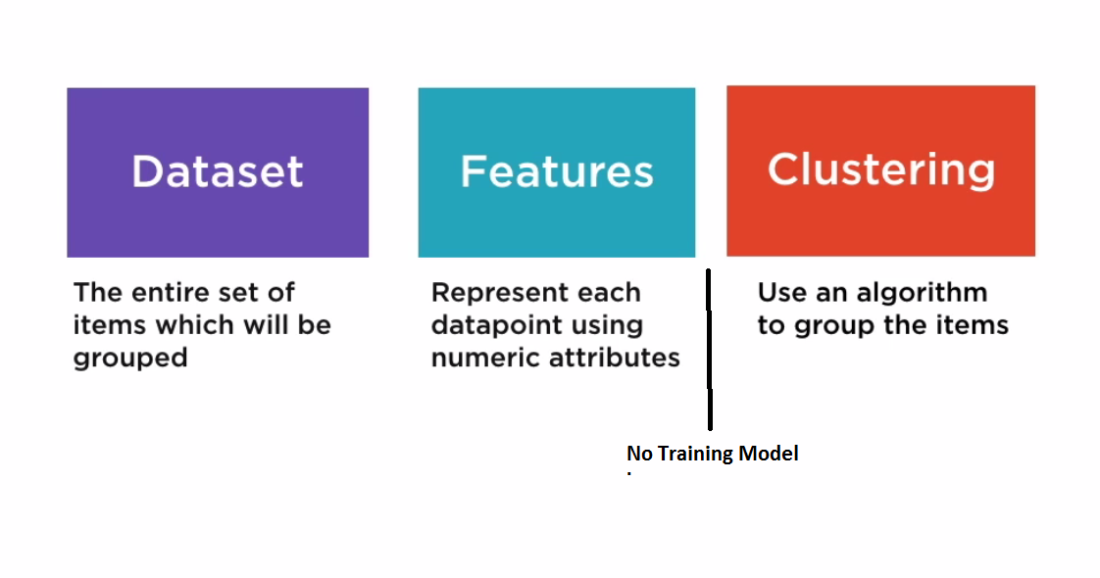
聚类属于无监督机器学习,用于数据的一组实例为包含类似特征的簇的任务。聚类还可用于识别数据集中的关系,这些关系可能不是通过浏览或简单观察而在逻辑上得出的。聚类算法的输入和输出取决于所选择的方法。您可以采用分布、质心、连通性或基于密度的方法。ML.NET目前支持使用K-Means聚类的基于质心的方法。聚类场景的例子包括:
聚类设置步骤:
回归是 监督的机器学习,用于从一组相关的功能预测标签的值。标签可以具有任何实际价值,并且不像分类任务那样来自有限的一组值。回归算法对标签对其相关特征的依赖性进行建模,以确定标签随着特征值的变化而如何变化。回归算法的输入是一组具有已知值标签的示例。回归算法的输出是一个函数,您可以使用该函数来预测任何新的输入要素集的标注值。回归情景的例子包括:
标签:简单 针对性 tutorials build 理解 sources bing analysis 新版
原文地址:https://www.cnblogs.com/shanyou/p/9190701.html