标签:blog http io 使用 ar 文件 数据 sp 2014
首先咋们看一个图: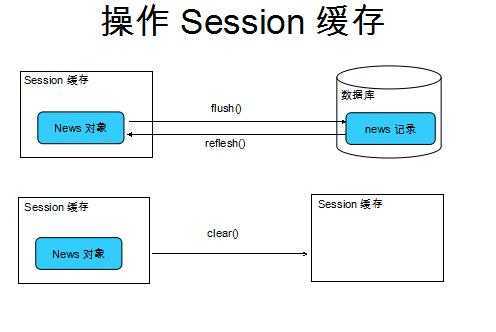
flush:首先箭头是由缓存指向数据库,即当我调用 Session.flush()方法时它会强制使数据库的记录跟缓存 中的对象状态保持同步 ,如果不一致,就会发送Sql语句 ,保持一致,而Hibernate在Session的声明周期能自动感知缓存对象的状态是否和数据库一致,如果不一致,会自 动调用flush()方法
flush: 使数据表中的记录和 Session 缓存中的对象的状态保持一致. 为了保持一致, 则可能会发送对应的 SQL 语句.
1. 在 Transaction 的 commit() 方法中: 先调用 session 的 flush 方法, 再提交事务
2. flush() 方法会可能会发送 SQL 语句, 但不会提交事务.
3. 注意: 在未提交事务或显式的调用 session.flush() 方法之前, 也有可能会进行 flush() 操作.
1). 执行 HQL 或 QBC 查询, 会先进行 flush() 操作, 以得到数据表的最新的记录
2). 若记录的 ID 是由底层数据库使用自增的方式生成的(生成OID的方式为native), 则在调用 save() 方法时, 就会立即发送 INSERT 语句. 因为 save 方法后, 必须保证对象的 ID 是存在的!
refresh():强制使缓存中对象的状态和数据库的记录保持 一致,换句话说refresh()方法会强制的发送一条select语句,
:当时Mysql数据库的事务隔离级别有四个如下:

脏读: 对于两个事物 T1, T2, T1 读取了已经被 T2 更新但还没有被提交的字段. 之后, 若 T2 回滚, T1读取的内容就是临时且无效的.
不可重复读: 对于两个事物 T1, T2, T1 读取了一个字段, 然后 T2 更新了该字段. 之后, T1再次读取同一个字段, 值就不同了.
幻读: 对于两个事物 T1, T2, T1 从一个表中读取了一个字段, 然后 T2 在该表中插入了一些新的行. 之后, 如果 T1 再次读取同一个表, 就会多出几行.
Mysql默认的隔离事务是:repeatable read(可重复读):
修改数据库隔离事务的办法:
Hibernate 的配置文件中可以显式的设置隔离级别.
每一个隔离级别都对应一个整数: 1. READ UNCOMMITED 2. READ COMMITED 3. REPEATABLE READ 4.SERIALIZEABLE
Hibernate 通过为 Hibernate 映射文件指定 hibernate.connection.isolation 属性来设置事务的隔离级别
例如: <property name="connection.isolation">2</property>
clear():清理缓存:
标签:blog http io 使用 ar 文件 数据 sp 2014
原文地址:http://www.cnblogs.com/jeremy-blog/p/3999626.html