标签:star clust sts 之间 ike check arch lib64 man
MySQL的高可以有三种实现方式:多主模式(Multi Master MySQL),MHA(Master High Availability)和 Galera Cluster:wresp
? 对主节点进行监控,可实现自动故障转移至其它从节点;通过提升某一从节点为新的主节点,基于主从复制实现,还需要客户端配合实现,目前MHA主要支持一主多从的架构,要搭建MHA,要求一个复制集群中必须最少有三台数据库服务器,一主二从,即一台充当master,一台充当备用master,另外一台充当从库。
MHA软件由两部分组成,Manager工具包和Node工具包;
Manager工具包主要包括以下几个工具:
Node工具包:这些工具通常由MHA Manager的脚本触发,无需人为操作
提示:为了尽可能的减少主库硬件损坏宕机造成的数据丢失,因此在配置MHA的同时建议配置成MySQL 5.5的半同步复制。
自定义扩展:
下载地址:https://code.google.com/archive/p/mysql-master-ha/downloads
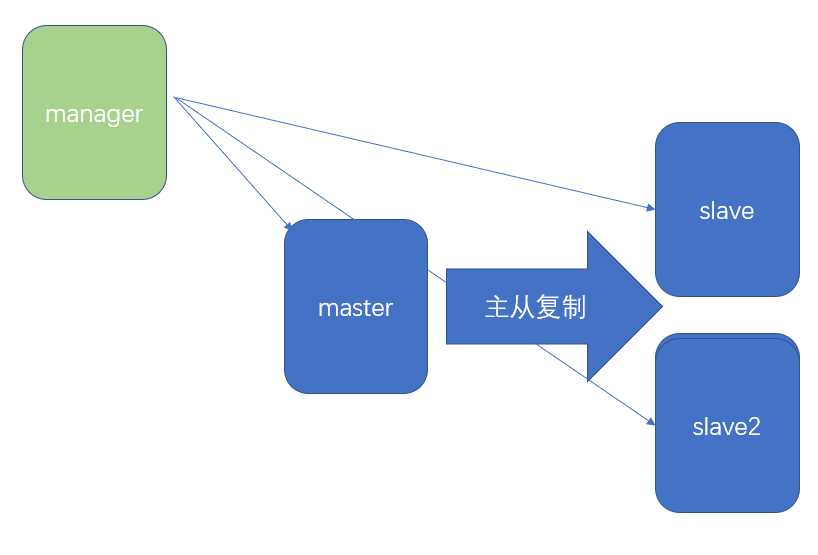
环境:基于秘钥认证,参考:
https://www.cnblogs.com/L-dongf/p/9058265.html,时间必须同步,执行:ntpdate cn.pool.ntp.org
1)manager节点
[root@manager ~]# yum install mha4mysql-manager-0.56-0.el6.noarch.rpm mha4mysql-node-0.56-0.el6.noarch.rpm -y #安装mha软件
[root@manager ~]# scp mha4mysql-node-0.56-0.el6.noarch.rpm 192.168.0.7:
[root@manager ~]# scp mha4mysql-node-0.56-0.el6.noarch.rpm 192.168.0.8:
[root@manager ~]# scp mha4mysql-node-0.56-0.el6.noarch.rpm 192.168.0.9:
[root@manager ~]# mkdir /etc/mha/
[root@manager ~]# vim /etc/mha/cluster1.cnf
[server default]
user=mhauser
password=mhapass
manager_workdir=/data/mastermha/cluster1/
manager_log=/data/mastermha/cluster1/manager.log
remote_workdir=/data/mastermha/cluster1/
ssh_user=root
repl_user=repluser
repl_password=replpass
ping_interval=1 #每秒检测一次
[server1]
hostname=192.168.0.7
candidate_master=1 #可以成为主节点
[server2]
hostname=192.168.0.8
candidate_master=1 #可以成为主节点
[server3]
hostname=192.168.0.9
[root@manager ~]# masterha_check_ssh --conf=/etc/mha/cluster1.cnf #检查ssh秘钥环境
All SSH connection tests passed successfully.
[root@manager ~]# masterha_check_repl --conf=/etc/mha/cluster1.cnf #检查MySQL状态
MySQL Replication Health is OK.
[root@manager ~]# yum install screen -y
[root@manager ~]# screen -S mha #mha是工作在前台的进程,不能用终端实时检测
[root@manager ~]# masterha_manager --conf=/etc/mha/cluster1.cnf #开始监测2)master节点
[root@master ~]# yum install mha4mysql-node-0.56-0.el6.noarch.rpm -y #安装node包
[root@master ~]# vim /etc/my.cnf
[mysqld]
server_id=1
log_bin
binlog_format=row
skip_name_resolve
[root@master ~]# systemctl start mariadb
MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO repluser@'192.168.0.%' IDENTIFIED BY 'replpass'; #创建主从复制账号,可能切换为主的节点都要创建此账号
MariaDB [(none)]> SHOW MASTER LOGS;
+--------------------+-----------+
| Log_name | File_size |
+--------------------+-----------+
| mariadb-bin.000001 | 401 |
+--------------------+-----------+
MariaDB [(none)]> GRANT ALL ON *.* TO mhauser@'192.168.0.%' IDENTIFIED BY 'mhapass'; #创建mha的管理用户,确保所有节点都已经同步此账号3)slave节点
[root@slave ~]# yum install mha4mysql-node-0.56-0.el6.noarch.rpm -y
[root@slave ~]# vim /etc/my.cnf
[mysqld]
read_only=1
log_bin
binlog_format=row
server_id=2
relay_log_purge=0
skip_name_resolve=1
[root@slave ~]# systemctl start mariadb
MariaDB [(none)]> GRANT REPLICATION SLAVE ON *.* TO repluser@'192.168.0.%' IDENTIFIED BY 'replpass';
MariaDB [(none)]> CHANGE MASTER TO
-> MASTER_HOST='192.168.0.7', #此时主节点为0.7
-> MASTER_USER='repluser',
-> MASTER_PASSWORD='replpass',
-> MASTER_PORT=3306,
-> MASTER_LOG_FILE='mariadb-bin.000001',
-> MASTER_LOG_POS=401,
-> MASTER_CONNECT_RETRY=10;
MariaDB [(none)]> START SLAVE;4)slave2节点
[root@slave2 ~]# yum install mha4mysql-node-0.56-0.el6.noarch.rpm -y
[root@slave2 ~]# vim /etc/my.cnf
[mysqld]
server_id=3
read_only=1
relay_log_purge=0
skip_name_resolve=1
[root@slave2 ~]# systemctl start mariadb
MariaDB [(none)]> CHANGE MASTER TO
-> MASTER_HOST='192.168.0.7',
-> MASTER_USER='repluser',
-> MASTER_PASSWORD='replpass',
-> MASTER_PORT=3306,
-> MASTER_LOG_FILE='mariadb-bin.000001',
-> MASTER_LOG_POS=401,
-> MASTER_CONNECT_RETRY=10;
MariaDB [(none)]> START SLAVE;4)测试
当master的服务停止:[root@master ~]# systemctl stop mariadb
在slave2上执行:MariaDB [(none)]> SHOW SLAVE STATUS\G命令,看到Master_Server_Id: 2
说明:切换成功
将故障的master修复后重新上线,手动配置成为现在主节点的从
[root@master ~]# systemctl start mariadb
MariaDB [(none)]> CHANGE MASTER TO
-> MASTER_HOST='192.168.0.8', #此时的主为0.8
-> MASTER_USER='repluser',
-> MASTER_PASSWORD='replpass',
-> MASTER_PORT=3306,
-> MASTER_LOG_FILE='mariadb-bin.000001',
-> MASTER_LOG_POS=482,
-> MASTER_CONNECT_RETRY=10;
MariaDB [(none)]> START SLAVE;管理节点:
[root@manager ~]# screen -S mha
[root@manager ~]# masterha_manager --conf=/etc/mha/cluster1.cnf #重新开启监测? Galera Cluster:集成了Galera插件的MySQL集群,是一种新型的,数据不共享的,高度冗余的高可用方案,目前Galera Cluster有两个版本,分别是Percona Xtradb Cluster及MariaDB Cluster,Galera本身是具有多主特性的,即采用multi-master的集群架构,是一个既稳健,又在数据一致性、完整性及高性能方面有出色表现的高可用解决方案
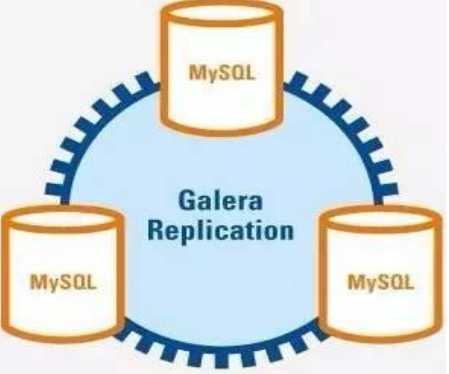
? 三个节点组成了一个集群,与普通的主从架构不同,它们都可以作为主节点,三个节点是对等的,称为multi-master架构,当有客户端要写入或者读取数据时,连接哪个实例都是一样的,读到的数据是相同的,写入某一个节点之后,集群自己会将新数据同步到其它节点上面,这种架构不共享任何数据,是一种高冗余架构
特性:
工作原理:
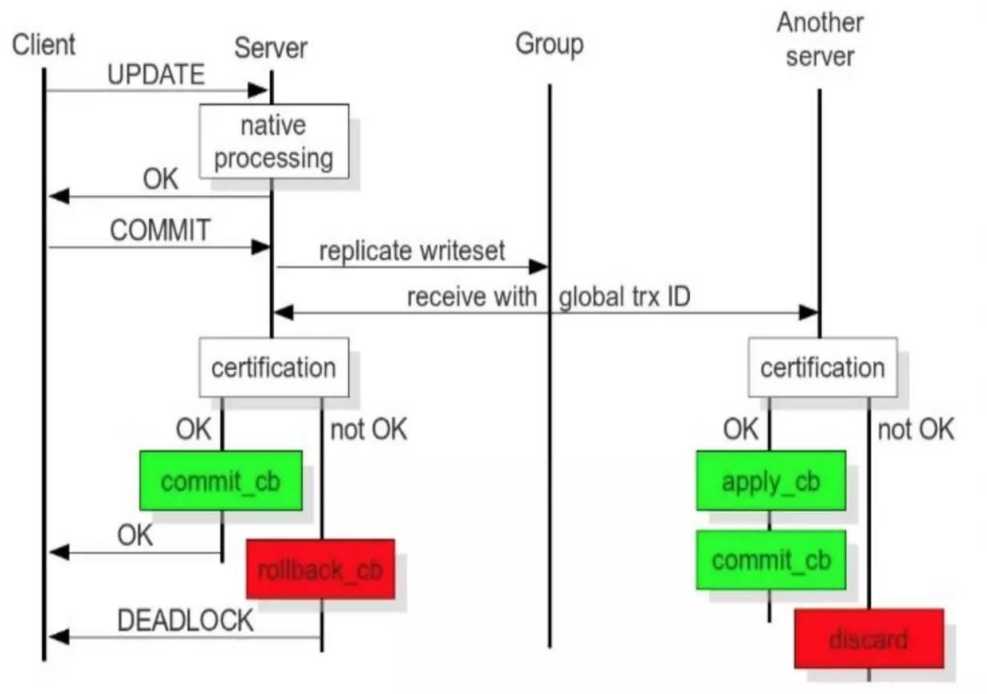
参考官方文档:
http://galeracluster.com/documentation-webpages/galera-documentation.pdf
http://galeracluster.com/documentation-webpages/index.html
https://mariadb.com/kb/en/mariadb/getting-started-with-mariadb-galera-cluster/
至少需要三台节点,不能安装 mariadb-server 包,需要安装特定的软件包
清华开源镜像源:https://mirrors.tuna.tsinghua.edu.cn/mariadb/mariadb-5.5.60/yum/centos7-amd64/
# vim /etc/yum.repos.d/mariadb_galera_server.repo
[mariadb]
name=mariadb_galera_server.repo
baseurl=https://mirrors.tuna.tsinghua.edu.cn/mariadb/mariadb-5.5.60/yum/centos7-amd64/
gpgcheck=0
# yum install MariaDB-Galera-server -y? 1)mysql-1
[root@mysql-1 ~]# vim /etc/my.cnf.d/server.cnf
[galera]
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_cluster_address="gcomm://192.168.0.7,192.168.0.8,192.168.0.9" #将所有IP都定义在此
binlog_format=row
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
wsrep_cluster_name='my_wsrep_cluster'
wsrep_node_name='node1'
wsrep_node_address='192.168.0.7'? 2)mysql-2
[root@mysql-2 ~]# vim /etc/my.cnf.d/server.cnf
[galera]
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_cluster_address="gcomm://192.168.0.7,192.168.0.8,192.168.0.9"
binlog_format=row
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
wsrep_cluster_name='my_wsrep_cluster'
wsrep_node_name='node2'
wsrep_node_address='192.168.0.8'? 3)mysql-3
[root@mysql-3 ~]# vim /etc/my.cnf.d/server.cnf
[galera]
wsrep_provider=/usr/lib64/galera/libgalera_smm.so
wsrep_cluster_address="gcomm://192.168.0.7,192.168.0.8,192.168.0.9"
binlog_format=row
default_storage_engine=InnoDB
innodb_autoinc_lock_mode=2
bind-address=0.0.0.0
wsrep_cluster_name='my_wsrep_cluster'
wsrep_node_name='node3'
wsrep_node_address='192.168.0.9'? 4)启动
[root@mysql-1 ~]# /etc/init.d/mysql start --wsrep-new-cluster #第一台启动加此参数
[root@mysql-2 ~]# /etc/init.d/mysql start #后续服务直接启动即可
[root@mysql-3 ~]# /etc/init.d/mysql start? 5)测试
? 在任何一个节点上操作数据库,其他节点同步操作;如果发生同时操作同条记录,则只有一台节点操作成功。
? 6)查看工作状态
MariaDB [(none)]> SHOW VARIABLES LIKE 'wsrep_%'\G
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_%'\G
MariaDB [(none)]> SHOW STATUS LIKE 'wsrep_cluster_size';
+--------------------+-------+
| Variable_name | Value |
+--------------------+-------+
| wsrep_cluster_size | 3 | #集群中有三台节点在线
+--------------------+-------+记录时间 2018.6.17 父亲节
标签:star clust sts 之间 ike check arch lib64 man
原文地址:https://www.cnblogs.com/L-dongf/p/9192710.html