标签:题解 get gen service 一个 打开 需要 效果 truncate
1 [yun@mini05 zhangliang]$ hadoop fs 2 Usage: hadoop fs [generic options] 3 [-appendToFile <localsrc> ... <dst>] 4 [-cat [-ignoreCrc] <src> ...] 5 [-checksum <src> ...] 6 [-chgrp [-R] GROUP PATH...] 7 [-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...] 8 [-chown [-R] [OWNER][:[GROUP]] PATH...] 9 [-copyFromLocal [-f] [-p] [-l] <localsrc> ... <dst>] 10 [-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] 11 [-count [-q] [-h] <path> ...] 12 [-cp [-f] [-p | -p[topax]] <src> ... <dst>] 13 [-createSnapshot <snapshotDir> [<snapshotName>]] 14 [-deleteSnapshot <snapshotDir> <snapshotName>] 15 [-df [-h] [<path> ...]] 16 [-du [-s] [-h] <path> ...] 17 [-expunge] 18 [-find <path> ... <expression> ...] 19 [-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>] 20 [-getfacl [-R] <path>] 21 [-getfattr [-R] {-n name | -d} [-e en] <path>] 22 [-getmerge [-nl] <src> <localdst>] 23 [-help [cmd ...]] 24 [-ls [-d] [-h] [-R] [<path> ...]] 25 [-mkdir [-p] <path> ...] 26 [-moveFromLocal <localsrc> ... <dst>] 27 [-moveToLocal <src> <localdst>] 28 [-mv <src> ... <dst>] 29 [-put [-f] [-p] [-l] <localsrc> ... <dst>] 30 [-renameSnapshot <snapshotDir> <oldName> <newName>] 31 [-rm [-f] [-r|-R] [-skipTrash] <src> ...] 32 [-rmdir [--ignore-fail-on-non-empty] <dir> ...] 33 [-setfacl [-R] [{-b|-k} {-m|-x <acl_spec>} <path>]|[--set <acl_spec> <path>]] 34 [-setfattr {-n name [-v value] | -x name} <path>] 35 [-setrep [-R] [-w] <rep> <path> ...] 36 [-stat [format] <path> ...] 37 [-tail [-f] <file>] 38 [-test -[defsz] <path>] 39 [-text [-ignoreCrc] <src> ...] 40 [-touchz <path> ...] 41 [-truncate [-w] <length> <path> ...] 42 [-usage [cmd ...]] 43 44 Generic options supported are 45 -conf <configuration file> specify an application configuration file 46 -D <property=value> use value for given property 47 -fs <local|namenode:port> specify a namenode 48 -jt <local|resourcemanager:port> specify a ResourceManager 49 -files <comma separated list of files> specify comma separated files to be copied to the map reduce cluster 50 -libjars <comma separated list of jars> specify comma separated jar files to include in the classpath. 51 -archives <comma separated list of archives> specify comma separated archives to be unarchived on the compute machines. 52 53 The general command line syntax is 54 bin/hadoop command [genericOptions] [commandOptions]
|
-help 功能:输出这个命令参数手册 |
|
-ls 功能:显示目录信息 示例: hadoop fs -ls hdfs://hadoop-server01:9000/ 备注:这些参数中,所有的hdfs路径都可以简写 -->hadoop fs -ls / 等同于上一条命令的效果 |
|
-mkdir 功能:在hdfs上创建目录 示例:hadoop fs -mkdir -p /aaa/bbb/cc/dd |
|
-moveFromLocal 功能:从本地剪切粘贴到hdfs 示例:hadoop fs - moveFromLocal /home/hadoop/a.txt /aaa/bbb/cc/dd -moveToLocal 功能:从hdfs剪切粘贴到本地 示例:hadoop fs - moveToLocal /aaa/bbb/cc/dd /home/hadoop/a.txt |
|
--appendToFile 功能:追加一个文件到已经存在的文件末尾 示例:hadoop fs -appendToFile ./hello.txt hdfs://hadoop-server01:9000/hello.txt 可以简写为: Hadoop fs -appendToFile ./hello.txt /hello.txt
|
|
-cat 功能:显示文件内容 示例:hadoop fs -cat /hello.txt
-tail 功能:显示一个文件的末尾 示例:hadoop fs -tail /weblog/access_log.1 -text 功能:以字符形式打印一个文件的内容 示例:hadoop fs -text /weblog/access_log.1 |
|
-chgrp -chmod -chown 功能:linux文件系统中的用法一样,对文件所属权限 示例: hadoop fs -chmod 666 /hello.txt hadoop fs -chown someuser:somegrp /hello.txt |
|
-copyFromLocal 功能:从本地文件系统中拷贝文件到hdfs路径去 示例:hadoop fs -copyFromLocal ./jdk.tar.gz /aaa/ -copyToLocal 功能:从hdfs拷贝到本地 示例:hadoop fs -copyToLocal /aaa/jdk.tar.gz |
|
-cp 功能:从hdfs的一个路径拷贝hdfs的另一个路径 示例: hadoop fs -cp /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
-mv 功能:在hdfs目录中移动文件 示例: hadoop fs -mv /aaa/jdk.tar.gz / |
|
-get 功能:等同于copyToLocal,就是从hdfs下载文件到本地 示例:hadoop fs -get /aaa/jdk.tar.gz -getmerge 功能:合并下载多个文件 示例:比如hdfs的目录 /aaa/下有多个文件:log.1, log.2,log.3,... hadoop fs -getmerge /aaa/log.* ./log.sum |
|
-put 功能:等同于copyFromLocal 示例:hadoop fs -put /aaa/jdk.tar.gz /bbb/jdk.tar.gz.2
|
|
-rm 功能:删除文件或文件夹 示例:hadoop fs -rm -r /aaa/bbb/
-rmdir 功能:删除空目录 示例:hadoop fs -rmdir /aaa/bbb/ccc |
|
-df 功能:统计文件系统的可用空间信息 示例:hadoop fs -df -h /
-du 功能:统计文件夹的大小信息 示例: hadoop fs -du -s -h /aaa/*
|
|
-count 功能:统计一个指定目录下的文件节点数量 示例:hadoop fs -count /aaa/
|
|
-setrep 功能:设置hdfs中文件的副本数量 示例:hadoop fs -setrep 3 /aaa/jdk.tar.gz <这里设置的副本数只是记录在namenode的元数据中,是否真的会有这么多副本,还得看datanode的数量>
|
1、集群启动后,可以查看文件,但是上传文件时报错,打开web页面可看到namenode正处于safemode状态,怎么处理?
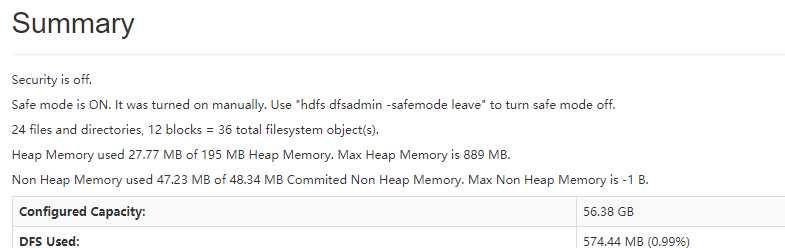
1 ## 模拟场景如下 2 [yun@mini04 ~]$ hdfs dfsadmin -safemode get 3 Safe mode is OFF 4 [yun@mini04 ~]$ hdfs dfsadmin -safemode enter 5 Safe mode is ON 6 [yun@mini04 ~]$ hdfs dfsadmin -safemode get 7 Safe mode is ON 8 [yun@mini04 ~]$ hdfs dfsadmin -safemode leave # 关闭safemode状态 9 Safe mode is OFF 10 [yun@mini04 ~]$ hdfs dfsadmin -safemode get 11 Safe mode is OFF
2、Namenode服务器的磁盘故障导致namenode宕机,如何挽救集群及数据?
1 1、如何减少宕机,保证数据不丢失 2 1) 对namenode机器的磁盘做raid10 3 2) 通过配置 dfs.namenode.name.dir 如下:dfs namenode 的目录,可以有多个目录,然后每个目录挂不同的磁盘,每个目录下的文件信息是一样的,相当于备份 4 <property> 5 <name>dfs.namenode.name.dir</name> 6 <value> file://${hadoop.tmp.dir}/dfs/name,file://${hadoop.tmp.dir}/dfs/name1,file://${hadoop.tmp.dir}/dfs/name2</value> 7 </property> 8 9 2、如果namenode的数据丢失,怎么最大限度恢复数据。 10 将 namesecondary 元数据目录的数据复制到namenode下即可(可以最大限度恢复数据)
3、Namenode是否可以有多个?namenode内存要配置多大?namenode跟集群数据存储能力有关系吗?
1、Namenode不能有多个
2、内存配置参考: hadoop内存大小设置问题【转】 HDFS NameNode内存详解
3、有一定关系,但是也和datanode自身有关。比如:如果都是存储小文件,那肯定是存不了多少的
4、现在datanode有3个,之前配置副本为2,现在副本配置改为4,会存在什么现象?
1 副本配置改为4之后,之前的副本数量不会改变,还是为2。 原因:之前上传的文件副本数已经定了。【即副本数的增加不会对已上传文件的副本数生效,之前的仍然为2】。 2 但是之后上传的文件,副本会为3,而不是4. 原因:3台机器存4个副本,没有意义,所以只会有3个副本。
5、现在datanode有3个,某个目录下文件的副本数为2,现在改为3怎么操作?
1 [yun@mini01 logs]$ hadoop fs -ls /data/webservice/20180614 2 Found 319 items 3 -rw-r--r-- 2 yun supergroup 10268 2018-06-14 17:05 /data/webservice/20180614/access.log.100_20180614170537 4 -rw-r--r-- 2 yun supergroup 10268 2018-06-14 17:05 /data/webservice/20180614/access.log.101_20180614170537 5 -rw-r--r-- 2 yun supergroup 10268 2018-06-14 17:05 /data/webservice/20180614/access.log.102_20180614170537 6 ……………… 7 [yun@mini01 logs]$ hadoop fs -setrep -R -w 3 /data/ # 设置副本数 8 Replication 3 set: /data/webservice/20180614/access.log.100_20180614170537 9 Replication 3 set: /data/webservice/20180614/access.log.101_20180614170537 10 Replication 3 set: /data/webservice/20180614/access.log.102_20180614170537 11 ……………… 12 [yun@mini01 logs]$ hadoop fs -ls /data/webservice/20180614 # 已经变为3 13 Found 319 items 14 -rw-r--r-- 3 yun supergroup 10268 2018-06-14 17:05 /data/webservice/20180614/access.log.100_20180614170537 15 -rw-r--r-- 3 yun supergroup 10268 2018-06-14 17:05 /data/webservice/20180614/access.log.101_20180614170537 16 -rw-r--r-- 3 yun supergroup 10268 2018-06-14 17:05 /data/webservice/20180614/access.log.102_20180614170537 17 ………………
6、怎么快速删除冗余数据块?
在日常维护hadoop集群的过程中发现这样一种情况:
某个节点由于网络故障或者DataNode进程死亡,被NameNode判定为死亡,HDFS马上自动开始数据块的容错拷贝;当该节点重新添加到集群中时,由于该节点上的数据其实并没有损坏,所以造成了HDFS上某些block的备份数超过了设定的备份数。通过观察发现,这些多余的数据块经过很长的一段时间才会被完全删除掉,那么这个时间取决于什么呢?
1 该时间的长短跟数据块报告的间隔时间有关。Datanode会定期将当前该结点上所有的BLOCK信息报告给Namenode,参数dfs.blockreport.intervalMsec就是控制这个报告间隔的参数。 2 hdfs-site.xml文件中有一个参数: 3 <property> 4 <name>dfs.blockreport.intervalMsec</name> 5 <value>3600000</value> 6 <description>Determines block reporting interval in milliseconds.</description> 7 </property> 8 其中3600000为默认设置,3600000毫秒,即1个小时,也就是说,块报告的时间间隔为1个小时,所以经过了很长时间这些多余的块才被删除掉。 9 通过实际测试发现,当把该参数调整的稍小一点的时候(60秒),多余的数据块确实很快就被删除了。
1 # 配置文件 2 [yun@mini01 hadoop]$ pwd 3 /app/hadoop/etc/hadoop 4 [yun@mini01 hadoop]$ cat hdfs-site.xml 5 <?xml version="1.0" encoding="UTF-8"?> 6 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 7 <!-- 8 ……………… 9 --> 10 11 <!-- Put site-specific property overrides in this file. --> 12 13 <configuration> 14 <!-- 指定HDFS副本的数量 --> 15 <property> 16 <name>dfs.replication</name> 17 <value>2</value> 18 </property> 19 20 <property> 21 <!-- <name>dfs.secondary.http.address</name> --> 22 <name>dfs.namenode.secondary.http-address</name> 23 <value>mini01:50090</value> 24 </property> 25 26 <!-- dfs block报告周期 单位毫秒 --> 27 <property> 28 <name>dfs.blockreport.intervalMsec</name> 29 <value>60000</value> 30 <description>Determines block reporting interval in milliseconds.</description> 31 </property> 32 33 </configuration>
7、hadoop datanode节点超时时间设置?
datanode进程死亡或者网络故障造成datanode无法与namenode通信,namenode不会立即把该节点判定为死亡,要经过一段时间,这段时间暂称作超时时长。HDFS默认的超时时长为10分钟+30秒。如果定义超时时间为timeout,则超时时长的计算公式为:
timeout = 2 * heartbeat.recheck.interval + 10 * dfs.heartbeat.interval。
而默认的heartbeat.recheck.interval 大小为5分钟,dfs.heartbeat.interval默认为3秒。
需要注意的是hdfs-site.xml 配置文件中的heartbeat.recheck.interval的单位为毫秒,dfs.heartbeat.interval的单位为秒。所以,举个例子,如果heartbeat.recheck.interval设置为5000(毫秒),dfs.heartbeat.interval设置为3(秒,默认),则总的超时时间为40秒。
1 ## hdfs-site.xml中的参数设置格式: 2 3 <property> 4 <name>heartbeat.recheck.interval</name> 5 <value>2000</value> 6 </property> 7 <property> 8 <name>dfs.heartbeat.interval</name> 9 <value>1</value> 10 </property>
8、HDFS存放策略
1 1、如果该节点为写入节点,那么在该节点会保留一个副本。 2 2、尽量将一个块不同的副本分布到其他机架上【跨机架】,以便集群能够在整个机架损失中生存。 3 3、其中一个副本通常放置在与向文件写入节点相同的机架上,以便减少跨机架网络I/O。 4 4、将HDFS数据统一分布在集群中的DataNodes中。
Hadoop2.7.6_04_HDFS的Shell操作与常见问题
标签:题解 get gen service 一个 打开 需要 效果 truncate
原文地址:https://www.cnblogs.com/zhanglianghhh/p/9195450.html