标签:技术 基本 size 标记 com 图片 数据集 分享图片 形状
一.基本概念
dbscan算法
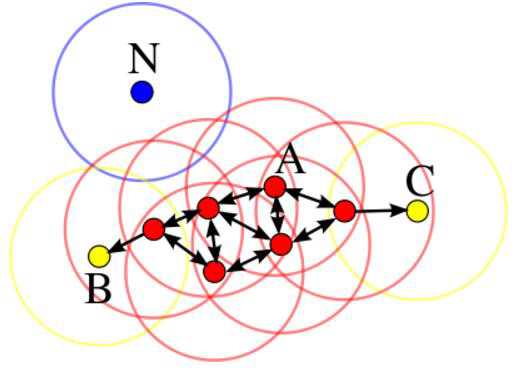
二.基本过程
算法流程:(数据集、半径、密度阈值)
参数选择:
K距离:给定数据集P={p(i); i=0,1,…n},计算点P(i)到集合D的子集S中所有点
之间的距离,距离按照从小到大的顺序排序,d(k)就被称为k-距离。
三.优缺点
优势
劣势
标签:技术 基本 size 标记 com 图片 数据集 分享图片 形状
原文地址:https://www.cnblogs.com/xyp666/p/9201585.html