标签:nload 程序 tin files 磁盘io int res 页面 cacti
1.1 iostat
系统systat包里的工具,以kB/s为单位统计,2表示以2秒为频率统计一次:
iostat –x –k 2 10000

|
rrqm/s:每秒这个设备相关的读取请求有多少被Merge了(当系统调用需要读取数据的时候,VFS将请求发到各个FS,如果FS发现不同的读取请求读取的是相同Block的数据,FS会将这个请求合并Merge);wrqm/s:每秒这个设备相关的写入请求有多少被Merge了。
rsec/s:每秒读取的扇区数;
wsec/:每秒写入的扇区数。
rKB/s:The number of read requests that were issued to the device per second;
wKB/s:The number of write requests that were issued to the device per second;
avgrq-sz 平均请求扇区的大小
avgqu-sz 是平均请求队列的长度。毫无疑问,队列长度越短越好。
await: 每一个IO请求的处理的平均时间(单位是微秒毫秒)。这里可以理解为IO的响应时间,一般地系统IO响应时间应该低于5ms,如果大于10ms就比较大了。这个时间包括了队列时间和服务时间,也就是说,一般情况下,await大于svctm,它们的差值越小,则说明队列时间越短,反之差值越大,队列时间越长,说明系统出了问题。
svctm 表示平均每次设备I/O操作的服务时间(以毫秒为单位)。如果svctm的值与await很接近,表示几乎没有I/O等待,磁盘性能很好,如果await的值远高于svctm的值,则表示I/O队列等待太长,系统上运行的应用程序将变慢。
%util: 在统计时间内所有处理IO时间,除以总共统计时间。例如,如果统计间隔1秒,该设备有0.8秒在处理IO,而0.2秒闲置,那么该设备的%util = 0.8/1 = 80%,所以该参数暗示了设备的繁忙程度。一般地,如果该参数是100%表示设备已经接近满负荷运行了(当然如果是多磁盘,即使%util是100%,因为磁盘的并发能力,所以磁盘使用未必就到了瓶颈)。
|
1.2 iotop
需单独安装 yum install iotop
用法:iotop -d 1 -o

|
-o:只显示有io操作的进程
-b:批量显示,无交互,主要用作记录到文件。
-n NUM:显示NUM次,主要用于非交互式模式。
-d SEC:间隔SEC秒显示一次。
-p PID:监控的进程pid。
-u USER:监控的进程用户。
|
常用快捷键:
|
1 左右箭头:改变排序方式,默认是按IO排序。
2 r:改变排序顺序。
3 o:只显示有IO输出的进程。
4 p:进程/线程的显示方式的切换。
5 a:显示累积使用量。
6 q:退出。
|
1.3 sar
sar –p –d 2 1000

|
说明:
tps: 每秒向磁盘设备请求数据的次数,包括读、写请求,为rtps与wtps的和。出于效率考虑,每一次IO下发后并不是立即处理请求,而是将请求合并(merge),这里tps指请求合并后的请求计数。
rtps: 每秒向磁盘设备的读请求次数
wtps: 每秒向磁盘设备的写请求次数
bread: 每秒从磁盘读的bytes数量
bwrtn: 每秒向磁盘写的bytes数量
或者用:sar –b 2 1000
|
或者用:sar –b 2 1000
1.4 dstat
dstat命令是一个用来替换vmstat、iostat、netstat、nfsstat和ifstat这些命令的工具,是一个全能系统信息统计工具。与sysstat相比,dstat拥有一个彩色的界面,在手动观察性能状况时,数据比较显眼容易观察;而且dstat支持即时刷新,譬如输入dstat 3即每三秒收集一次,但最新的数据都会每秒刷新显示。和sysstat相同的是,dstat也可以收集指定的性能资源,譬如dstat -c即显示CPU的使用情况。
常用选项
|
-c:显示CPU系统占用,用户占用,空闲,等待,中断,软件中断等信息。
-C:当有多个CPU时候,此参数可按需分别显示cpu状态,例:-C 0,1 是显示cpu0和cpu1的信息。
-d:显示磁盘读写数据大小。
-D hda,total:include hda and total。
-n:显示网络状态。
-N eth1,total:有多块网卡时,指定要显示的网卡。
-l:显示系统负载情况。
-m:显示内存使用情况。
-g:显示页面使用情况。
-p:显示进程状态。
-s:显示交换分区使用情况。
-S:类似D/N。
-r:I/O请求情况。
-y:系统状态。
--ipc:显示ipc消息队列,信号等信息。
--socket:用来显示tcp udp端口状态。
-a:此为默认选项,等同于-cdngy。
-v:等同于 -pmgdsc -D total。
--output 文件:此选项也比较有用,可以把状态信息以csv的格式重定向到指定的文件中,以便日后查看。例:dstat --output /root/dstat.csv & 此时让程序默默的在后台运行并把结果输出到/root/dstat.csv文件中。
|
二、监控工具
说明一下,其实这些工具都是全能选手,cpu,内存,磁盘空间,网络流量都可以监控,不仅仅是用来监控磁盘IOPS的。
2.1 nmon
Linux下安装:
|
[root@iZ28jwgor8mZ ~]# wget http://sourceforge.net/projects/nmon/files/download/nmon_x86_12a.zip/download
[root@iZ28jwgor8mZ ~]# unzip download
Archive: download
inflating: nmon_x86_rhel45
inflating: nmon_x86_rhel52
inflating: nmon_x86_sles9
inflating: nmon_x86_sles10
inflating: nmon_x86_ubuntu810
inflating: nmon_x86_fedora10
inflating: nmon_x86_opensuse10
[root@iZ28jwgor8mZ ~]# yum install ld-linux.so.2; yum install libncurses.so.5
[root@iZ28jwgor8mZ ~]# chmod +x nmon_x86_rhel52
[root@iZ28jwgor8mZ ~]# mv nmon_x86_rhel52 /usr/local/bin/nmon
#在后台自动以10秒为单位采集60次的样,即10分钟
[root@iZ28jwgor8mZ ~]# nmon -s10 -c60 -f -m ./
#检查后台进程
[root@iZ28jwgor8mZ ~]# ps -ef|grep -i nmon
root 16872 1 0 13:32 pts/0 00:00:00 nmon -s10 -c60 -f -m ./
|
分析工具:nmon_analyser
参考:
Nmon说明:
http://www.ibm.com/developerworks/cn/aix/library/analyze_aix/index.html
nmon_analyser的说明:
http://www.ibm.com/developerworks/cn/aix/library/nmon_analyser/index.html
分析也比较较单,启用excel的宏,打开一个生成的nmon文件即可:
2.2 zabbix
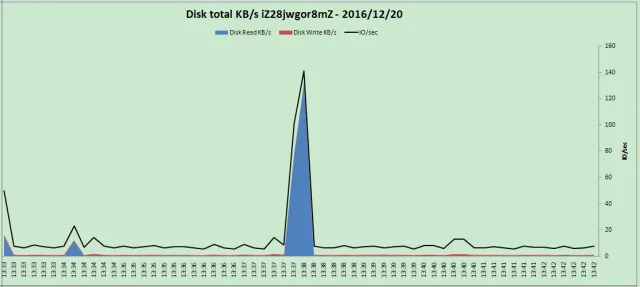
Zabbix现在用的比较多了,其配置IOPS监控的模板有现成的,直接导入即可,出图效果如下:
2.3 cacti
这里不是介绍cacti,cacti作为一个老牌工具,部署文档网上比较成熟了。其IOPS模板下载地址:
http://forums.cacti.net/about8777.html
安装步骤参见:
1. Unzip Cacti_Net-SNMP_DevIO_v3.1.zip (5 Files)
2. Copy net-snmp_devio.xml to <path_cacti>/resource/snmp_queries/net-snmp_devio.xml
3. Import all *_TMPL.xml files via Cacti "Import Templates" interface- These templates should include all their dependancies
4. Import the net-snmp_devIO-Data_query.xml file LAST
5. Add "ucd/net - Get Device I/O" Data Query to your SNMP Enabled host using the "Index Count Changed" Re-index Method.
6. Create Graphs for your desired Disk and/or Memory devices.
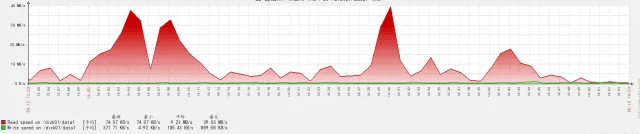
完成后:
Linux磁盘监控工具说明
标签:nload 程序 tin files 磁盘io int res 页面 cacti
原文地址:https://www.cnblogs.com/moss_tan_jun/p/9206274.html