标签:对象 nocache asc enc tab 关联 控制 作用 feedback
用来产生主键的值(自己控制主键值,很容易重复,用sequence可以自动增长产生主键值)
序列可以产生1.0*10^38个数
create sequence 序列名; (和建立表一样)
用序列放入的主键值绝对不会重复
序列名。nextval(使用序列值的下一个数)
序列名。currval(使用当前序列数,基本不会用到)
一张表只能用一个序列,不能用两个序列,否则可能重复
可以两张表用一个序列,但是这样数会比较乱
(1) 创建表(之前要先删表)
create table testseq( id number primary key, name varchar2(30), salary number, );

(2) 创建序列
create sequence testseq_id;

(3) 使用序列,向表中插入数据
insert into testseq values( testseq_id, nextval, ‘test‘|| testseq_id.currval, 1000*testseq_id.currval, );
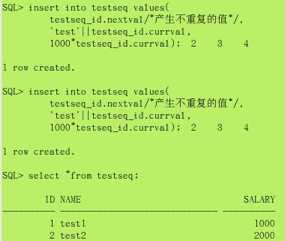
drop sequence 序列名 ;(和删除表一样,不存在就说删不到)
drop sequence testseq_id;

drop sequence testseq_id;
加速查询速度
底层通过树状结构组织数据,消耗了大量的空间和时间来加速查询。消耗的是建立索引的时间,一旦索引建立完毕,查询就很快。组织数据的树状结构消耗的空间很大。
索引就像书的目录,正常的查找数据像在书中一页一页查询数据量越大,索引的优势越大
ps:set timing on 如此设置后就会统计每条操作的时间
假设有3亿条数据,要查询其中一条数据:
不用索引:
用oracle(配置为2G内存,i3处理器时)
查询一条数据大概需要60*8=480s
用索引:0.01s
对唯一性的字段,系统会自动建立索引,叫唯一性索引
非唯一性索引建立:在表的某个字段上创建索引
正常用法:
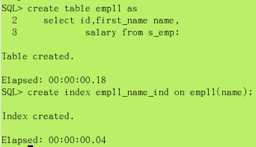
create index 索引名 on 表名(要创建索引的字段名);
快速建表(非正常用法)
create table 表名 as select id,first_name name,salary from 查询的表名
(即建的表的数据和查询的数据一样)
![]()
drop index 索引名;
数据库脚本(xxx.sql)里是怎样写的?(大小写不敏感)
drop sequence 序列名;
drop table 表名 cascade constraint /* 解除关联*/ ;
create sequence 序列名 属性;
create table 表名(字段以及约束);
insert into 表名 values( 匹配表的要求的要增加的数据 );
commit ;
alter table 子表名 add constraint 子表名_加外键的字段名_fk foreign key(加外键的字段名)reference(父表名_被加外键的字段名);
Prompt table and sequences created and populated.set feedback on
标签:对象 nocache asc enc tab 关联 控制 作用 feedback
原文地址:https://www.cnblogs.com/cjaaron/p/9216920.html