标签:自动化 raise 控制 save 读取 下标 new 循环 文件内容
编码使我快乐!!!
我也不知道为什么,遇到自己喜欢的事情,就越想做下去,可以一个月不出门,但是不能一天没有电脑
掌握程度:对python有了一个更清晰的认识,自动化运维,也许可以用python实现呢,加油
实现功能:
爬取响应的网页,并且存入本地文件和DB
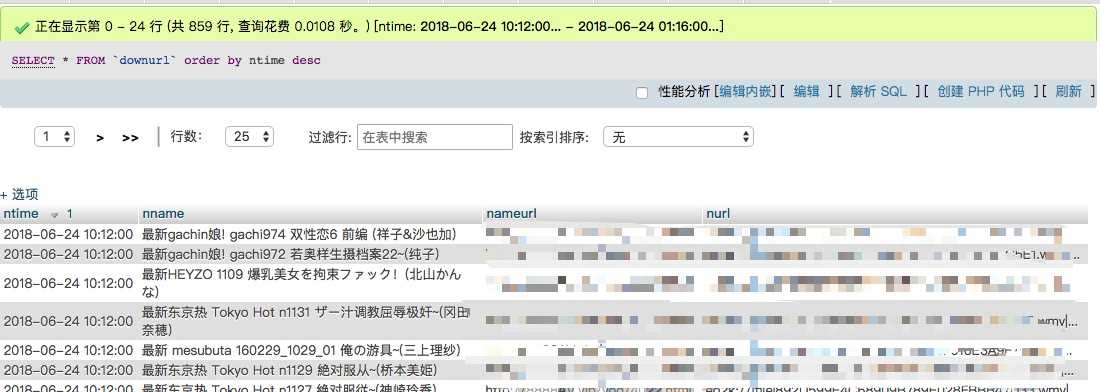
本地文件:

DB:
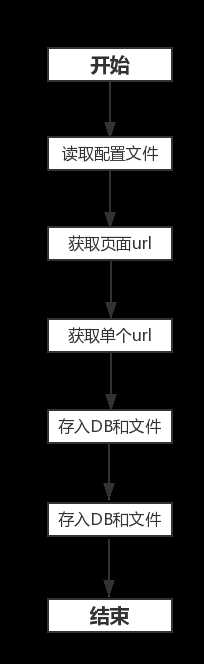
整体逻辑:
1.读取配置文件
1 def ReadLocalFiles() : 2 #定义字典用于存储conf中的变量与值 3 returndict={} 4 5 #定义变量用于存储行数 6 linenumber = 0 7 8 #以只读方式获取文件内容,因为文件需要放在crontab中,故需写全路径 9 localfiles = open(r‘/root/python-script/geturl/main.conf‘) 10 11 #获取文件所有值,以list的方式存储在readfilelines中 12 readfilelines = localfiles.readlines() 13 14 #定义for用于循环list进行抓值 15 for line in readfilelines : 16 17 #使行数自增1,用于报错显示 18 linenumber = linenumber + 1 19 20 #利用rstrip进行去除多余的空格 21 line = line.rstrip() 22 23 #判断如果文件开头为#,则continue继续循环 24 if line.startswith(‘#‘) : 25 continue 26 27 #判断如果line的长度为0,则continue继续循环 28 elif len(line) == 0 : 29 continue 30 31 #如果依上条件均不满足 32 else: 33 34 #执行try语句,如果有异常,使之在控制范围内 35 try: 36 returndict[line.split(‘=‘)[0]] = line.split(‘=‘)[1] 37 38 #抛出异常 39 except: 40 #打印错误语句 41 print (time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))+"line %d %s error,please check" % (linenumber,line)) 42 # 43 localfiles.close() 44 #使程序异常退出 45 sys.exit(-1) 46 47 #返回字典 48 localfiles.close() 49 return returndict
2.清除已经下载的文件内容
1 def DeleteHisFiles(update_file): 2 3 #判断是否存在update_file这个文件 4 if os.path.isfile(update_file): 5 6 try: 7 #以可读可写方式打开文件 8 download_files = open(update_file,‘r+‘) 9 #清除文件内容 10 download_files.truncate() 11 #关闭文件 12 download_files.close() 13 except: 14 #报错,清除失败 15 print (time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))+"Truncate " + update_file + "error , please check it") 16 #如果文件在路径下不存在 17 else : 18 #新建文件 19 print (time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))+"Build New downfiles ok")
3.检测网址是否有更新
1 def DealwithURL(url): 2 #获取url的内容传入r 3 r = requests.get(url) 4 5 #定义需要查找的正则表达式的值 6 pattern = re.compile(‘<meta http-equiv="refresh" content="0.1;url=‘) 7 8 #在r.text中查找pattern的值 9 findurl=re.findall(pattern,r.text) 10 11 #如果有找到值 12 if findurl: 13 #定义需要查找正则表达式的值,此值为去url=后面的内容直至"结尾 14 pattern = re.compile(‘<meta http-equiv="refresh" content="0.1;url=(.*)"‘) 15 16 #在r.text中查找pattern的值,并将下标为0的值赋值给transferurl 17 transferurl = re.findall(pattern,r.text)[0] 18 19 #返回transferurl的值 20 return transferurl 21 else : 22 #否则返回true 23 return True
4.获取更新后的网址
1 def GetNewURL(url): 2 #获取url的内容传入r 3 r = requests.get(url) 4 5 #编码为utf-8 6 r.encoding=‘utf-8‘ 7 8 #定义需要查找的正则表达式的值,以alert开头,以">结尾的值 9 pattern = re.compile(‘alert(.*)">‘) 10 #在r.text中查找pattern的值 11 findurl=re.findall(pattern,r.text) 12 #将传入的值修改为str格式 13 findurl_str = (" ".join(findurl)) 14 #1.返回findurl_str以空格分割后的下标为1的值 15 #2.返回第1步的下标为0的值 16 #3.返回第2步的下标为2的值至最后 17 return (findurl_str.split(‘ ‘,1)[0][2:])
5.存储新的网址进本地配置文件
1 def SaveLocalUrl(untreatedurl,treatedurl): 2 #如果两个值相等 3 if untreatedurl == treatedurl : 4 pass 5 6 else : 7 #执行try语句,如果有异常,使之在控制范围内 8 try: 9 #以只读的方式打开文件 10 fileconf = open(r‘/root/python-script/geturl/main.conf‘,‘r‘) 11 #设置rewritestr为空 12 rewritestr = "" 13 14 #执行fileconf的for循环 15 for readline in fileconf: 16 17 #如果在readline中有搜索到untreatedurl 18 if re.search(untreatedurl,readline): 19 20 #在readline中将untreatedurl值替换为treatedurl值 21 readline = re.sub(untreatedurl,treatedurl,readline) 22 #试rewritestr加上新的readline 23 rewritestr = rewritestr + readline 24 else : 25 #否则的话,也使rewritestr加上新的readline 26 rewritestr = rewritestr + readline 27 #读入完毕将文件关闭 28 fileconf.close() 29 30 #以只写的方式打开文件 31 fileconf = open(r‘/root/python-script/geturl/main.conf‘,‘w‘) 32 #将rewritestr写入文件 33 fileconf.write(rewritestr) 34 #关闭文件 35 fileconf.close() 36 37 except: 38 #打印异常 39 print ("get new url but open files ng write to logs,please check main.conf")
6.随机获取一个网页并且取得总页数
1 def GetTitleInfo(url,down_page,update_file,headers): 2 3 #定义title的值,随机从1——8中抽取一个出来 4 title = ‘/list/‘+str(random.randint(1,8)) 5 6 #定义titleurl的值,为url+title+.html 7 titleurl = url + title + ‘.html‘ 8 9 #获取当前的url内容并返回给r 10 r = requests.get(titleurl) 11 #设置r的编码为当前页面的编码 12 r.encoding = chardet.detect(r.content)[‘encoding‘] 13 ##定义需要查找的正则表达式的值,以‘ 当前:.*‘开头,以‘页 ‘结尾的值 14 pattern = re.compile(‘ 当前:.*/(.*)页 ‘) 15 #在r.text中查找符合pattern的值 16 getpagenumber = re.findall(pattern,r.text) 17 18 #将getpagenumber值转换为str格式 19 getpagenumber = (" ".join(getpagenumber)) 20 21 GetListURLinfo(url , title , int(getpagenumber) , int(down_page),update_file,headers)
7.Download详细URL
1 def GetListURLinfo(sourceurl , title , getpagenumber , total,update_file,headers): 2 3 #将total的值控制在范围内 4 if total >= 100: 5 total = 100 6 7 if total <= 1: 8 total = 2 9 10 #将total的值赋值给getpagenumber 11 getpagenumber = total 12 13 #定义for循环,循环次数为total的总数 14 for number in range(0,total) : 15 try: 16 #定义信号值 17 signal.signal(signal.SIGALRM,handler) 18 #设置alarm为3,若超过3秒,则被抛送异常 19 signal.alarm(3) 20 21 #定义url的值为小于getpagenumber的随机页面 22 url = sourceurl + title + ‘-‘ + str(random.randint(1,getpagenumber)) + ‘.html‘ 23 24 #获取url的内容,并且传值给r 25 r = requests.get(url) 26 27 #定义需要查找的正则表达式的值,以<div class="info"><h2>开头,以</a><em></em></h2>结尾的值 28 pattern = re.compile(‘<div class="info"><h2>(.*)</a><em></em></h2>‘) 29 #设置编码为页面编码 30 r.encoding = chardet.detect(r.content)[‘encoding‘] 31 #在r.text中查找符合pattern的值 32 allurl = re.findall(pattern,r.text) 33 34 #为allurl定义for循环 35 for lineurl in allurl: 36 try: 37 #定义信号值 38 signal.signal(signal.SIGALRM,handler) 39 #设置alarm为3,若超过3秒,则被抛送异常 40 signal.alarm(3) 41 42 #定义需要查找的正则表达式的值,以<a href="开头,以" title结尾的值 43 pattern = re.compile(‘<a href="(.*)" title‘) 44 #在r.text中查找符合pattern的值并且赋值给titleurl 45 titleurl = re.findall(pattern,lineurl) 46 47 #定义需要查找的正则表达式的值,以<a href="开头,以” target=结尾的值 48 pattern = re.compile(‘title="(.*)" target=‘) 49 #在r.text中查找符合pattern的值并且赋值给titlename 50 titlename = re.findall(pattern,lineurl) 51 52 signal.alarm(0) 53 54 #超时抛出异常 55 except AssertionError: 56 print (lineurl,titlename , "Timeout Error: the cmd 10s have not finished") 57 continue 58 59 except AssertionError: 60 print ("GetlistURL Error Continue") 61 continue
8.获取每个url的ed2k地址
1 def GetDownloadURL(sourceurl,titleurl,titlename,update_file,headers): 2 #将downurlstr,downnamestr转换str类型 3 downurlstr = (" ".join(titleurl)) 4 downnamestr = (" ".join(titlename)) 5 6 #获取url的内容,并且传值给r 7 r = requests.get((sourceurl+downurlstr)) 8 9 #定义需要查找的正则表达式的值,以autocomplete="on">开头,以/</textarea></div>结尾的值 10 pattern = re.compile(‘autocomplete="on">(.*)/</textarea></div>‘) 11 12 #在r.text中查找符合pattern的值并且赋值给downurled2k 13 downurled2k = re.findall(pattern,r.text) 14 #将downurled2k的值修改为str并且赋值给downurled2kstr 15 downurled2kstr = (" ".join(downurled2k)) 16 17 WriteLocalDownloadURL(update_file , downurled2kstr,titlename) 18 19 #输出downnamestr 和 downurled2kstr 20 print (downnamestr , downurled2kstr) 21 22 #定义savedburl为sourceurl + downurlstr的值 23 savedburl = sourceurl + downurlstr 24 SaveDB(time.strftime(‘%Y-%m-%d %H:%M‘,time.localtime(time.time())),titlename[0],downurled2kstr,savedburl) 25 # print (time.strftime(‘%Y-%m-%d %H:%M‘,time.localtime(time.time())))
9.将文件内容写进本地
1 def WriteLocalDownloadURL(downfile,listfile): 2 3 #以追加的方式打开downfile文件 4 urlfile = open(downfile,‘a+‘) 5 6 #定义循环语句 7 for line in listfile : 8 urlfile.write(line+‘\n‘) 9 10 #关闭文件 11 urlfile.close()
10.将文件内容写进DB
1 def SaveDB(nowdate,tilename,downurl,savedburl): 2 3 #获取游标 4 cursor = db.cursor() 5 6 #定义select查询语句 7 sql = "select count(nurl) from downurl where nurl = ‘%s‘;" % (downurl) 8 cursor.execute(sql) 9 10 #获取执行的结果 11 data = cursor.fetchone() 12 13 #判断结果是否为‘0’ 14 if ‘0‘ == str(data[0]): 15 #定义insert插入语句 16 sql = "insert into downurl values (‘%s‘,‘%s‘,‘%s‘,‘%s‘);" % (nowdate,tilename,savedburl,downurl) 17 18 #定义try语句 19 try: 20 #执行sql语句 21 cursor.execute(sql) 22 #执行commit语句 23 db.commit() 24 except: 25 #否则执行rollback语句 26 db.rollback()
代码综合:
1 root@Linux:~/python-script/geturl # cat main.py 2 #!/usr/bin/python3 3 import requests 4 import re 5 import chardet 6 import random 7 import signal 8 import time 9 import os 10 import sys 11 import pymysql 12 13 14 def DealwithURL(url): 15 r = requests.get(url) 16 pattern = re.compile(‘<meta http-equiv="refresh" content="0.1;url=‘) 17 findurl=re.findall(pattern,r.text) 18 19 if findurl: 20 pattern = re.compile(‘<meta http-equiv="refresh" content="0.1;url=(.*)"‘) 21 22 transferurl = re.findall(pattern,r.text)[0] 23 24 return transferurl 25 else : 26 return True 27 28 def GetNewURL(url): 29 r = requests.get(url) 30 31 r.encoding=‘utf-8‘ 32 pattern = re.compile(‘alert(.*)">‘) 33 findurl=re.findall(pattern,r.text) 34 findurl_str = (" ".join(findurl)) 35 return (findurl_str.split(‘ ‘,1)[0][2:]) 36 37 def gettrueurl(url): 38 if DealwithURL(url)==True: 39 return url 40 else : 41 return GetNewURL(DealwithURL(url)) 42 43 def SaveLocalUrl(untreatedurl,treatedurl): 44 if untreatedurl == treatedurl : 45 pass 46 else : 47 try: 48 fileconf = open(r‘/root/python-script/geturl/main.conf‘,‘r‘) 49 rewritestr = "" 50 51 for readline in fileconf: 52 if re.search(untreatedurl,readline): 53 readline = re.sub(untreatedurl,treatedurl,readline) 54 rewritestr = rewritestr + readline 55 else : 56 rewritestr = rewritestr + readline 57 fileconf.close() 58 59 fileconf = open(r‘/root/python-script/geturl/main.conf‘,‘w‘) 60 fileconf.write(rewritestr) 61 fileconf.close() 62 63 except: 64 print ("get new url but open files ng write to logs") 65 66 def handler(signum,frame): 67 raise AssertionError 68 69 def SaveDB(nowdate,tilename,downurl,savedburl): 70 cursor = db.cursor() 71 72 sql = "select count(nurl) from downurl where nurl = ‘%s‘;" % (downurl) 73 cursor.execute(sql) 74 75 data = cursor.fetchone() 76 77 if ‘0‘ == str(data[0]): 78 sql = "insert into downurl values (‘%s‘,‘%s‘,‘%s‘,‘%s‘);" % (nowdate,tilename,savedburl,downurl) 79 80 try: 81 cursor.execute(sql) 82 db.commit() 83 except: 84 db.rollback() 85 86 def WriteLocalDownloadURL(downfile,listfile): 87 88 urlfile = open(downfile,‘a+‘) 89 90 for line in listfile : 91 urlfile.write(line+‘\n‘) 92 93 urlfile.close() 94 95 def GetDownloadURL(sourceurl,titleurl,titlename,update_file,headers,enabledb): 96 97 downurlstr = (" ".join(titleurl)) 98 downnamestr = (" ".join(titlename)) 99 100 r = requests.get((sourceurl+downurlstr)) 101 pattern = re.compile(‘autocomplete="on">(.*)/</textarea></div>‘) 102 103 downurled2k = re.findall(pattern,r.text) 104 downurled2kstr = (" ".join(downurled2k)) 105 106 107 print (downnamestr , downurled2kstr) 108 109 if 1 == enabledb : 110 savedburl = sourceurl + downurlstr 111 SaveDB(time.strftime(‘%Y-%m-%d %H:%M‘,time.localtime(time.time())),titlename[0],downurled2kstr,savedburl) 112 113 returnstr = titlename[0]+" "+downurled2kstr 114 return returnstr 115 116 def ReadLocalFiles() : 117 returndict={} 118 119 linenumber = 0 120 121 localfiles = open(r‘/root/python-script/geturl/main.conf‘) 122 123 readfilelines = localfiles.readlines() 124 125 for line in readfilelines : 126 linenumber = linenumber + 1 127 128 line = line.rstrip() 129 130 if line.startswith(‘#‘) : 131 continue 132 elif len(line) == 0 : 133 continue 134 else: 135 try: 136 returndict[line.split(‘=‘)[0]] = line.split(‘=‘)[1] 137 except: 138 print ("line %d %s error,please check" % (linenumber,line)) 139 sys.exit(-1) 140 141 return returndict 142 143 def GetListURLinfo(sourceurl , title , getpagenumber , total,update_file,headers,enablewritefile,enabledb): 144 145 returnwriteurl = [] 146 147 if total >= 100: 148 total = 100 149 150 if total <= 1: 151 total = 2 152 153 getpagenumber = total 154 155 for number in range(0,total) : 156 try: 157 signal.signal(signal.SIGALRM,handler) 158 signal.alarm(3) 159 160 url = sourceurl + title + ‘-‘ + str(random.randint(1,getpagenumber)) + ‘.html‘ 161 162 r = requests.get(url) 163 164 pattern = re.compile(‘<div class="info"><h2>(.*)</a><em></em></h2>‘) 165 r.encoding = chardet.detect(r.content)[‘encoding‘] 166 allurl = re.findall(pattern,r.text) 167 168 169 for lineurl in allurl: 170 try: 171 signal.signal(signal.SIGALRM,handler) 172 signal.alarm(3) 173 174 pattern = re.compile(‘<a href="(.*)" title‘) 175 titleurl = re.findall(pattern,lineurl) 176 177 pattern = re.compile(‘title="(.*)" target=‘) 178 titlename = re.findall(pattern,lineurl) 179 180 returnwriteurl.append(GetDownloadURL(sourceurl,titleurl,titlename,update_file,headers,enabledb)) 181 signal.alarm(0) 182 except AssertionError: 183 print (lineurl,titlename , "Timeout Error: the cmd 10s have not finished") 184 continue 185 186 except AssertionError: 187 print ("GetlistURL Error Continue") 188 continue 189 190 if 1 == enablewritefile: 191 WriteLocalDownloadURL(update_file,returnwriteurl) 192 193 def GetTitleInfo(url,down_page,update_file,headers,savelocalfileenable,savedbenable): 194 195 title = ‘/list/‘+str(random.randint(1,8)) 196 197 titleurl = url + title + ‘.html‘ 198 199 r = requests.get(titleurl) 200 r.encoding = chardet.detect(r.content)[‘encoding‘] 201 pattern = re.compile(‘ 当前:.*/(.*)页 ‘) 202 getpagenumber = re.findall(pattern,r.text) 203 204 getpagenumber = (" ".join(getpagenumber)) 205 206 GetListURLinfo(url , title , getpagenumber , down_page,update_file,headers,int(savelocalfileenable),int(savedbenable)) 207 208 209 def write_logs(time,logs): 210 loginfo = str(time)+logs 211 try: 212 logfile = open(r‘logs‘,‘a+‘) 213 logfile.write(loginfo) 214 logfile.close() 215 except: 216 print ("Write logs error,code:154") 217 218 219 def DeleteHisFiles(update_file): 220 if os.path.isfile(update_file): 221 try: 222 download_files = open(update_file,‘r+‘) 223 download_files.truncate() 224 download_files.close() 225 except: 226 print ("Delete " + update_file + "Error --code:166") 227 else : 228 print ("Build New downfiles") 229 230 def main(): 231 headers = {"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit 537.36 (KHTML, like Gecko) Chrome","Accept": "text/html,application/xhtml+xml,application/xml; q=0.9,image/webp,*/*;q=0.8"} 232 233 readconf = ReadLocalFiles() 234 235 try: 236 file_url = readconf[‘url‘] 237 down_page = readconf[‘download_page‘] 238 savelocalfileenable = readconf[‘savelocalfileenable‘] 239 savedbenable = readconf[‘savedbenable‘] 240 241 if 1 == int(savelocalfileenable) : 242 update_file = readconf[‘download_local_files‘] 243 244 if 1 == int(savedbenable) : 245 dbhost = readconf[‘dbhost‘] 246 dbport = readconf[‘dbport‘] 247 dbuser = readconf[‘dbuser‘] 248 dbpasswd = readconf[‘dbpasswd‘] 249 dbschema = readconf[‘dbschema‘] 250 dbcharset = readconf[‘dbcharset‘] 251 except: 252 print ("Get local conf error,please check url or down_page conf") 253 sys.exit(-1) 254 255 if 1 == int(savelocalfileenable) : 256 DeleteHisFiles(update_file) 257 258 untreatedurl = file_url 259 260 treatedurl = gettrueurl(untreatedurl) 261 SaveLocalUrl(untreatedurl,treatedurl) 262 263 url = treatedurl 264 265 if 1 == int(savedbenable): 266 global db 267 268 # dbconnect =‘‘‘ 269 # host=‘localhost‘,port=3306,user=‘root‘,passwd=‘flzx3QC#‘,db=‘downpage‘,charset=‘utf8‘ 270 # ‘‘‘ 271 db = pymysql.connect(host=‘localhost‘,port=3306,user=‘root‘,passwd=‘flzx3QC#‘,db=‘downpage‘,charset=‘utf8‘) 272 273 # print (dbconnect) 274 275 # db = pymysql.connect(dbconnect) 276 277 else: 278 db = ‘‘ 279 280 if 1 == int(savelocalfileenable) or 0 == int(savelocalfileenable): 281 GetTitleInfo(url,int(down_page),update_file,headers,int(savelocalfileenable),int(savedbenable)) 282 db.close() 283 284 285 if __name__=="__main__": 286 main() 287 root@Linux:~/python-script/geturl #
End
标签:自动化 raise 控制 save 读取 下标 new 循环 文件内容
原文地址:https://www.cnblogs.com/wang-li/p/9220030.html