标签:dev move 函数 分组 表示 data 删除目录 timestamp count
# (@+函数名),需要记住关键两点:
#功能:
#1、自动执行outer函数,并且将其下面的函数名f1当作参数传递
#2、将outer函数的返回值,重新赋值给f1
# #装饰器必备
# ####第一:函数名和执行函数####
# def foo(): #创建函数
# print(‘hello‘) #函数体
# foo #表示是函数名,代指整个函数
# foo() #表示执行f00函数
# # 输出:hello
# ####第二:函数被重新定义###
# def foo():
# print("foo1")
#
# foo = lambda : print("foo2") #lambda表达式,无参数
#
# foo() #执行下面的lambda表达式,而不是原来的foo函数,foo函数已经被重新定义
import time
import datetime
print(time.time()) # 返回当前时间的时间戳
print(time.ctime()) # 将时间戳转化为字符串格式Wed Feb 17 11:41:27 2016,默认是当前系统时间的时间戳 print(time.ctime(time.time()-3600)) # ctime可以接收一个时间戳作为参数,返回该时间戳的字符串形式 Wed Feb 17 10:43:04 2016
print(time.gmtime()) # 将时间戳转化为struct_time格式,默认是当前系统时间戳 print(time.gmtime(time.time() - 3600))
print(time.localtime()) # 同样是将时间戳转化为struct_time,只不过显示的是本地时间,gmtime显示的是标准时间(格里尼治时间)
print(time.mktime(time.localtime())) # 将struct_time时间格式转化为时间戳
print(time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())) # 将struct_time时间格式转化为自定义的字符串格式
print(time.strptime("2016-02-17", "%Y-%m-%d")) # 与trftime相反,将字符串格式转化为struct_time格式
print(time.asctime(time.localtime())) # 将struct_time转化为字符串形式
print(datetime.date.today()) # 返回当前日期的字符串形式2016-02-17
print(datetime.date.fromtimestamp(time.time() - 3600 * 24)) # 将时间戳转化为日期字符串形式2016-02-16
print(datetime.datetime.now()) # 返回的时间的字符串形式2016-02-17 13:53:30.719803 print(datetime.datetime.now().timetuple()) # 转化为struct_time格式
datetime.timedelta()返回的是一时间间隔对象,常与datetime.datetime.now()合用计算时间
print(datetime.datetime.now() - datetime.timedelta(days = 2))
random模块主要用来生成随机数
生成大于0小于1的浮点类型随机数
print(random.random()) #生成大于0小于1的浮点类型随机数
Python中用于序列化的两个模块
Json模块提供了四个功能:dumps、dump、loads、load
pickle模块提供了四个功能:dumps、dump、loads、load
提供对操作系统进行调用的接口
>>> import os
>>> os.getcwd() # 获取当前工作目录,类似linux的pwd命令
‘/data/python/day5‘
>>> os.chdir(‘..‘) # 进入某个目录,类似linux的cd命令
>>> os.getcwd()
‘/data/python‘
>>> os.curdir # 获取当前目录
‘.‘
>>> os.pardir # 获取当前目录的父目录
‘..‘
>>> os.chdir(‘day5‘)
>>> os.getcwd()
‘/data/python/day5‘
>>> os.makedirs(‘testdir1/testdir2‘) # 递归创建目录相当于 mkdir -p命令
>>> os.makedirs(‘test_dir1/test_dir2‘) # 递归创建目录相当于 mkdir -p命令
>>> os.listdir(‘.‘) # 显示目录下多所有文件 相当于linux的ls -a
[‘test_dir1‘]
>>> os.removedirs(‘test_dir1/test_dir2‘) # 删除多级(递归)目录,注意目录必须是空的,若目录为空删除,并递归到上以及目录,如果也为空则也删除
>>> os.mkdir(‘test2‘) # 创建目录,相当于mkdir
>>> os.rmdir(‘test2‘) # 删除目录,相当于rm
>>> f = open(‘test.txt‘, ‘w‘)
>>> f.write(‘testline‘)
8
>>> f.close()
>>> os.listdir()
[‘testdir2‘, ‘test.txt‘, ‘testdir1‘]
>>> os.rename(‘test.txt‘, ‘new_test.txt‘) #重命名
>>> os.stat(‘.‘) # 显示目录或文件的状态,包括权限等
os.stat_result(st_mode=16877, st_ino=786731, st_dev=64784, st_nlink=4, st_uid=0, st_gid=0, st_size=4096, st_atime=1455695375, st_mtime=1455696066, st_ctime=1455696066)
>>> os.sep # 获取文件分割符,linux为/,windows为\‘/‘
>>> os.name # 返回平台名,linux为posix,win为nt
‘posix‘
>>> os.linesep # 返回系统换行符,win下为\r\n
‘\n‘
>>> os.pathsep # 返回用于分割文件路径的字符串,vin下为;
‘:‘
>>> os.system(‘ls‘) # 执行shell命令
testdir1 testdir2
0
>>> os.environ # 获取系统环境变量
environ({‘USER‘: ‘root‘, ‘PATH‘: ‘/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin‘, ‘SHELL‘: ‘/bin/bash‘, ‘HOME‘: ‘/root‘, ‘SHLVL‘: ‘1‘, ‘HISTTIMEFORMAT‘: ‘%
...省略n多好...
>>> os.path.abspath(‘.‘) # 返回目录的绝对路径
‘/data/python/day5‘
>>> os.path.split(‘/data/python/day5‘) # 将path分割成目录和文件,元祖返回
(‘/data/python‘, ‘day5‘)
>>> os.path.dirname(‘/data/python/day5‘) # 返回path也即是split的第一个元素
‘/data/python‘
>>> os.path.basename(‘/data/python/day5‘) # 返回文件名也即是split的第一个元素
‘day5‘
>>> os.path.exists(‘/data/python/day5‘) # 判断目录或文件是否存在
True
>>> os.path.isabs(‘/data/python/day5‘) # 判断是否是绝对目录,不考虑是否存在,说白了就是字符串符合绝对路径的规范就返回True
True
>>> os.path.isabs(‘day5‘)
False
>>> os.path.isabs(‘/data/python/day6‘) #
True
>>> os.path.isfile(‘/data/python/day5‘) # 判断是否是文件
False
>>> os.path.isdir(‘/data/python/day5‘) # 判断是否是目录
True
>>> os.path.isdir(‘/data/python/day6‘)
False
>>> os.path.join(‘/data/python/day6‘, ‘test‘) # 组合目录
‘/data/python/day6/test‘
>>> os.path.getatime(‘/data/python/day5‘) # 返回文件或目录的最后访问时间
1455695375.9394312
>>> os.path.getmtime(‘/data/python/day5‘) # 返回文件或目录的最后修改时间
1455696066.0034554
>>> os.path.getctime(‘/data/python/day5‘) # 返回文件或目录的创建时间
1455696066.0034554
字符串是编程时涉及到的最多的一种数据结构,对字符串进行操作的需求几乎无处不在。比如判断一个字符串是否是合法的Email地址,虽然可以编程提取@前后的子串,再分别判断是否是单词和域名,但这样做不但麻烦,而且代码难以复用。
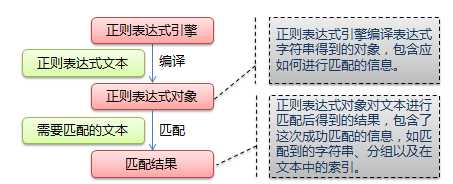
Python通过re模块提供对正则表达式的支持。使用re的一般步骤是先将正则表达式的字符串形式编译为Pattern实例,然后使用Pattern实例处理文本并获得匹配结果(一个Match实例),最后使用Match实例获得信息,进行其他的操作。
import re
# 将正则表达式编译成Pattern对象
pattern = re.compile(r‘hello‘)
# 使用Pattern匹配文本,获得匹配结果,无法匹配时将返回None
match = pattern.match(‘hello world!‘)
if match:
# 使用Match获得分组信息
print match.group()
>>> import re
>>> s = ‘hello world‘
>>> print(re.match(‘ello‘, s))
None
>>> print(re.search(‘ello‘,s ))
<_sre.SRE_Match object; span=(1, 5), match=‘ello‘>
说明:可以看到macth只匹配开头,开头不匹配,就不算匹配到,search则可以从中间,只要能有匹配到就算匹配
findall(string[, pos[, endpos]]) | re.findall(pattern, string[, flags])
搜索string,以列表形式返回全部能匹配的子串。有点像search的扩展,把所有匹配的子串放到一个列表
参数:同match
返回值:所有匹配的子串,没有匹配则返回空列表
>>> import re
>>> s = ‘one1two2three3four4‘
>>> re.findall(‘\d+‘, s)
[‘1‘, ‘2‘, ‘3‘, ‘4‘]
>>> import re
>>> s = ‘one1two2three3four4‘
>>> re.split(‘\d+‘, s)
[‘one‘, ‘two‘, ‘three‘, ‘four‘, ‘‘]
if __name__ == ‘__main__‘:
import re
s = ‘--(1.1+1+1-(-1)-(1+1+(1+1+2.2)))+-----111+--++--3-+++++++---+---1+4+4/2+(1+3)*4.1+(2-1.1)*2/2*3‘
def replace_sign(expression):
‘‘‘
替换多个连续+-符号的问题,例如+-----,遵循奇数个负号等于正否则为负的原则进行替换
:param expression: 表达式,包括有括号的情况
:return: 返回经过处理的表达式
‘‘‘
def re_sign(m):
if m:
if m.group().count(‘-‘)%2 == 1:
return ‘-‘
else:
return ‘+‘
else:
return ‘‘
expression = re.sub(‘[\+\-]{2,}‘, re_sign, expression)
return expression
s = replace_sign(s)
print(s)
执行结果
24 +(1.1+1+1-(-1)-(1+1+(1+1+2.2)))-111+3-1+4+4/2+(1+3)*4.1+(2-1.1)*2/2*3
标签:dev move 函数 分组 表示 data 删除目录 timestamp count
原文地址:https://www.cnblogs.com/yuanyuan1015/p/9221883.html