标签:举例 分享 ali api 场景 性能 怎么 完整 请求转发
需要掌握的要点总结:
下面开始HTTP详解学习:
HTTP使用统一资源标识符(Uniform Resource Identifiers, URI)来传输数据和建立连接。URL是一种特殊类型的URI,包含了用于查找某个资源的足够的信息。
http://www.163.com 是个 URL,叫作统一资源定位符。之所以叫统一,是因为它是有格式的。HTTP 称为协议,www.163.com 是一个域名,表示互联网上的一个位置。有的 URL 会有更详细的位置标识,例如 http://www.163.com/index.html 。
第一步浏览器先会将 www.163.com 这个域名发送给 DNS 服务器,让它解析为 IP 地址
第二步然后当然是要先建立 TCP 连接了,因为HTTP 是基于 TCP 协议的;
使用的 HTTP 协议大部分都是 1.1。在 1.1 的协议里面,默认是开启了 Keep-Alive 的,这样建立的 TCP 连接,就可以在多次请求中复用。
建立了连接以后,浏览器就要发送 HTTP 的请求。
请求的格式:
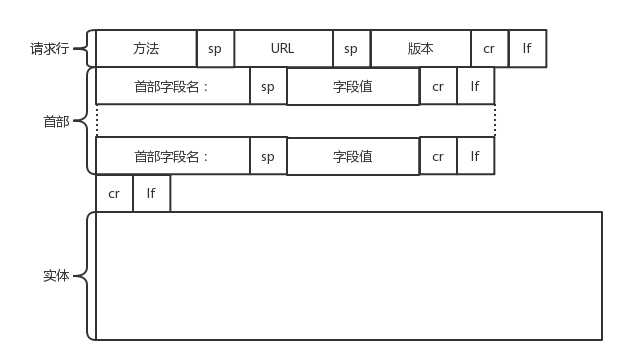
HTTP 的报文大概分为三大部分。第一部分是请求行,第二部分是请求的首部,第三部分才是请求的正文实体。
在请求行中,URL 就是 http://www.163.com ,版本为 HTTP 1.1;
方法列出以下常用方法:
补充内容见:HTTP协议中GET和POST方法的区别
方法举例:
GET方法:
在浏览器的地址栏中输入网址的方式访问网页时,浏览器采用GET方法向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)。
POST方法:
HEAD方法:
与GET方法几乎是一样的,对于HEAD请求的回应部分来说,它的HTTP头部中包含的信息与通过GET请求所得到的信息是相同的。
利用这个方法,不必传输整个资源内容,就可以得到Request-URI所标识的资源的信息。该方法常用于测试超链接的有效性,是否可以访问,以及最近是否更新。
DELETE方法:
我们要删除一个云主机,就会调用 DELETE 方法。
请求行下面就是我们的首部字段。首部是 key value,通过冒号分隔。这里面,往往保存了一些非常重要的字段。
架构图:
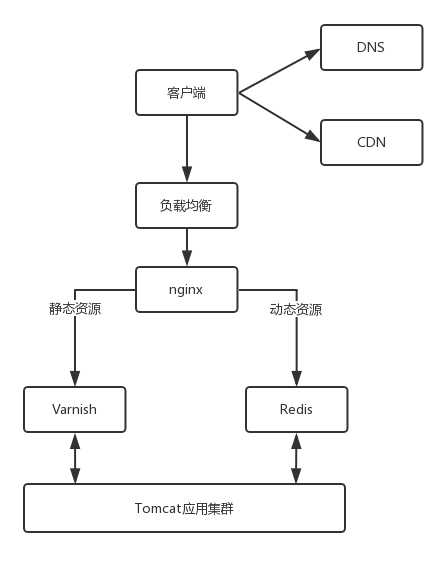
这里主要讲Nginx 这一层,Varnish和Redis缓存。
使用缓存的作用为:对于像淘宝购物车需加载大量图片与库存瞬息变化这种高并发场景下的系统,在真正的业务逻辑之前,都需要有个接入层,将这些静态资源的请求拦在最外面。
对于静态资源,有 Vanish 缓存层。当缓存过期的时候,才会访问真正的 Tomcat 应用集群。
在 HTTP 头里面
到此为止,我们仅仅是拼凑起了 HTTP 请求的报文格式,接下来,浏览器会把它交给下一层传输层。怎么交给传输层呢?其实也无非是用 Socket 这些东西,只不过用的浏览器里,这些程序不需要自己写,有人已经帮我们写好了。
应用层1->传输层1:
HTTP 协议是基于 TCP 协议的,所以它使用面向连接的方式发送请求,通过 stream 二进制流的方式传给对方。当然,到了 TCP 层,它会把二进制流变成一个的报文段发送给服务器。
在发送给每个报文段的时候,都需要对方有一个回应 ACK,来保证报文可靠地到达了对方。如果没有回应,那么 TCP 这一层会进行重新传输,直到可以到达。同一个包有可能被传了好多次,但是 HTTP 这一层不需要知道这一点,因为是 TCP 这一层在埋头苦干。
传输层1->网络层1:
TCP 层发送每一个报文的时候,都需要加上自己的地址(即源地址)和它想要去的地方(即目标地址),将这两个信息放到 IP 头里面,交给 IP 层进行传输。
网络层1->**链路物理链路层**->网络层2:
IP 层需要查看目标地址和自己是否是在同一个局域网。如果是,就发送 ARP 协议来请求这个目标地址对应的 MAC 地址,然后将源 MAC 和目标 MAC 放入 MAC 头,发送出去即可;如果不在同一个局域网,就需要发送到网关,还要需要发送 ARP 协议,来获取网关的 MAC 地址,然后将源 MAC 和网关 MAC 放入 MAC 头,发送出去。
网关收到包发现 MAC 符合,取出目标 IP 地址,根据路由协议找到下一跳的路由器,获取下一跳路由器的 MAC 地址,将包发给下一跳路由器。
这样路由器一跳一跳终于到达目标的局域网。
网络层2->传输层2:
目标的机器发现 MAC 地址符合,就将包收起来;发现 IP 地址符合,根据 IP 头中协议项,知道自己上一层是 TCP 协议,于是解析 TCP 的头,里面有序列号,需要看一看这个序列包是不是我要的,如果是就放入缓存中然后返回一个 ACK,如果不是就丢弃。
传输层2->应用层2:
TCP 头里面还有端口号,HTTP 的服务器正在监听这个端口号。于是,目标机器自然知道是 HTTP 服务器这个进程想要这个包,于是将包发给 HTTP 服务器。HTTP 服务器的进程看到,原来这个请求是要访问一个网页,于是就把这个网页发给客户端。
HTTP 的返回报文也是有一定格式的。这也是基于 HTTP 1.1 的。
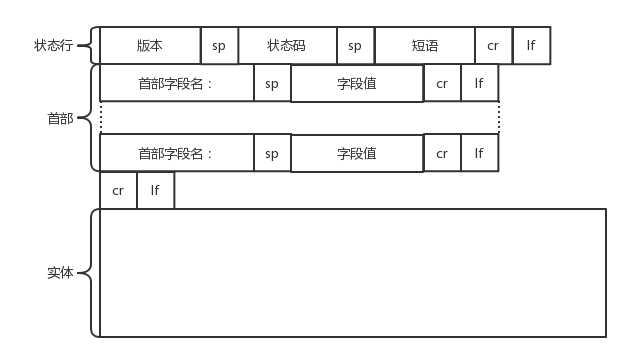
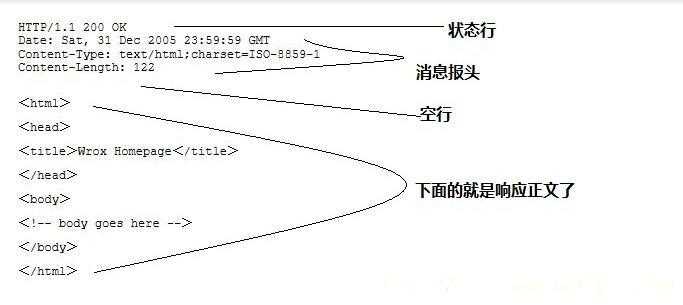
(HTTP/1.1)表明HTTP版本为1.1版本,状态码为200,状态消息为(ok)
状态码会反应 HTTP 请求的结果。“200”意味着大吉大利;而我们最不想见的就是“404”,也就是“服务端无法响应这个请求”
补充内容状态码见:http常见状态码
第二行和第三行为消息报头,即返回首部的key value。
如Date:生成响应的日期和时间;Content-Type:指定了MIME类型的HTML(text/html),编码类型是UTF-8
这里面也会有Content-Type,表示返回的是 HTML,还是 JSON。
空行后面的html部分为响应正文。
构造好了返回的 HTTP 报文,接下来就是把这个报文发送出去。还是交给 Socket 去发送,还是交给 TCP 层,让 TCP 层将返回的 HTML,也分成一个个小的段,并且保证每个段都可靠到达。
这些段加上 TCP 头后会交给 IP 层,然后把刚才的发送过程反向走一遍。虽然两次不一定走相同的路径,但是逻辑过程是一样的,一直到达客户端。
客户端发现 MAC 地址符合、IP 地址符合,于是就会交给 TCP 层。根据序列号看是不是自己要的报文段,如果是,则会根据 TCP 头中的端口号,发给相应的进程。这个进程就是浏览器,浏览器作为客户端也在监听某个端口。
当浏览器拿到了 HTTP 的报文。发现返回“200”,一切正常,于是就从正文中将 HTML 拿出来。HTML 是一个标准的网页格式。浏览器只要根据这个格式,展示出一个绚丽多彩的网页。
当然 HTTP 协议也在不断地进化过程中,在 HTTP1.1 基础上便有了 HTTP 2.0。
HTTP 1.1 在应用层以纯文本的形式进行通信。每次通信都要带完整的 HTTP 的头,而且不考虑 pipeline 模式的话,每次的过程总是像上面描述的那样一去一回。这样在实时性、并发性上都存在问题。
为了解决这些问题,HTTP 2.0
标签:举例 分享 ali api 场景 性能 怎么 完整 请求转发
原文地址:https://www.cnblogs.com/kumata/p/9222359.html