标签:des style blog http color io os ar java
JDOM is an in-memory XML model that can be used to read, write, create and modify XML Documents. JDOM is similar to DOM in that they both provide an in-memory XML document model, but while DOM is designed to work the same in multiple languages (C, C++, ECMAScript, Java, JScript, Lingo, PHP, PLSQL, and Python [http://www.w3.org/DOM/Bindings]), JDOM is designed only for Java and uses the natural Java-specific features that the DOM model avoids. For this reason JDOM intentionally does not follow the w3c DOM standard. JDOM is not an XML parser but it can use a SAX, StAX or DOM parser to build the JDOM document. JDOM versions since JDOM 2.0.0 (JDOM2) all use the native language features of Java6 and later like Generics, Enums, var-args, co-variant return types, etc.
In the tutorials listed below we provide you with examples of all key functionalities of JDOM2. However before you start seeing the examples, it would be a good idea to understand the main packages that form part of JDOM2 and the functionalities that each of the packages provide. The first tutorial in the series provides an introduction to the package structure along with important classes in each package. The subsequent tutorials provide examples for each of the key functionalities.
In this tutorial we explore the package structure and important classes for Jdom2.
This package contains the core classes that represent the XML components.
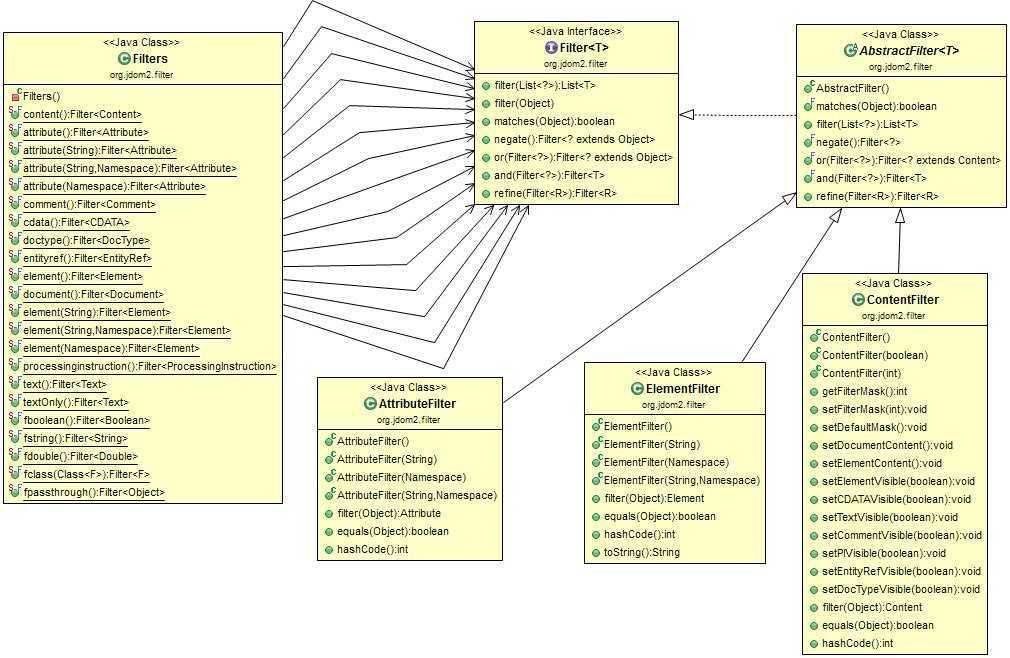
These package has filters that allow filtering based on type, name, value or other parameters. It also allows ANDing, ORing and Negating filters. Filters are used in the public <E extends Content> List<E> getContent(final Filter<E> filter) and public <F extends Content> IteratorIterable<F> getDescendants(final Filter<F> filter) methods of the Element class. Filters are also using in the XPath package of JDom2.
This package has the core classes responsible for building the JDOM2 document from DOM, SAX or StAX. The important classes are
These package has classes to ouput the JDOM2 document to various destinations. The main classes are :
In this tutorial we look at an example of how to build and navigate through a JDOM2 document from an XML source (in this case, a BBC News "Technology" RSS feed). We first use the org.jdom2.input.SAXBuilder class to create the JDOM2 document from the source (more details and options on the SAXBuilder class will be covered in later tutorials). Once we obtain the JDOM2 Document there are various JDOM2 methods used to access the elements, which will be covered in the next section of this tutorial.
JDOM2 is a java representation of an XML document. In other words, each XML component is represent as a java object. JDOM2 has convenient methods to access the various components. Here are some of the key use cases (the number in the bracket corresponds to the line number in the example) :
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 | package com.studytrails.xml.jdom; import java.io.IOException;import java.util.List; import org.jdom2.Content;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.JDOMException;import org.jdom2.input.SAXBuilder;import org.jdom2.util.IteratorIterable; public class CreateJdomFromSax { public static void main(String[] args) throws JDOMException, IOException { // the SAXBuilder is the easiest way to create the JDOM2 objects. SAXBuilder jdomBuilder = new SAXBuilder(); // jdomDocument is the JDOM2 Object Document jdomDocument = jdomBuilder.build(xmlSource); // The root element is the root of the document. we print its name System.out.println(jdomDocument.getRootElement().getName()); // prints // "rss" Element rss = jdomDocument.getRootElement(); // The Element class extends Content class which is NamespaceAware. We // see what namespace this element introduces. System.out.println(rss.getNamespacesIntroduced()); /* * prints [[Namespace: prefix "atom" is mapped to URI * "http://www.w3.org/2005/Atom"], [Namespace: prefix "media" is mapped * to URI "http://search.yahoo.com/mrss/"]] */ // the getContent method traverses through the document and gets all the // contents. We print the CType (an enumeration identifying the Content // Type), value and class of the Content. we print only the // first two values, since this is only an example. List<content> rssContents = rss.getContent(); for (int i = 0; i < 2; i++) { Content content = rssContents.get(i); System.out.println("CType " + content.getCType()); System.out.println("Class " + content.getClass()); } Element channel = rss.getChild("channel"); // the getChildren method can be used to obtain the children of the // element List<element> channelChildren = channel.getChildren(); for (int i = 0; i < 2; i++) { Element channelChild = channelChildren.get(i); System.out.println(channelChild.getName());// prints ‘title‘ and // ‘link‘ } // to directly obtain the child node of type Text System.out.println(channel.getChildText("link")); // print the first // link // It is also possible to specify the namespace while obtaining the // child element. In the statement below we // obtain the child with name ‘link‘ but we want that child to be from // the atom namespace. We further use the getAttributeValue method to // get the value of the attribute of the node System.out.println(channel.getChild("link", rss.getNamespace("atom")).getAttributeValue("href")); // Instead of getting all the children of a node we may want to get all // children with a particular name. List<element> items = channel.getChildren("item"); for (int i = 0; i < 2; i++) { System.out.println(items.get(i).getChildText("title")); // prints // the first // two // titles } // iterate through all the descendants and get the url of the thumbnails // (The thumbnails are declared with namespace media) IteratorIterable<content> descendantsOfChannel = channel.getDescendants(); for (Content descendant : descendantsOfChannel) { if (descendant.getCType().equals(Content.CType.Element)) { Element element = (Element) descendant; if (element.getNamespace().equals(rss.getNamespace("media"))) { System.out.println(element.getAttributeValue("url")); // // prints all urls of all thumbnails within the // ‘media‘ namespace } } } }}</content></element></element></content> |
In this tutorial we look at how to build a JDOM2 using a SAXBuilder. To understand how SAXBuilder works and how to configure it look at this tutorial. The example below demonstrates the following
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 | package com.studytrails.xml.jdom;import java.io.File;import java.io.IOException;import org.jdom2.Comment;import org.jdom2.Content;import org.jdom2.Content.CType;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.JDOMException;import org.jdom2.filter.Filters;import org.jdom2.input.SAXBuilder;import org.jdom2.util.IteratorIterable;public class JdomUsingSAXBuilder { private static String file1 = "tomcat-web-dtd.xml"; public static void main(String[] args) throws JDOMException, IOException { // Use a SAX builder SAXBuilder builder = new SAXBuilder(); // build a JDOM2 Document using the SAXBuilder. Document jdomDoc = builder.build(new File(file1)); // get the document type System.out.println(jdomDoc.getDocType()); //get the root element Element web_app = jdomDoc.getRootElement(); System.out.println(web_app.getName()); // get the first child with the name ‘servlet‘ Element servlet = web_app.getChild("servlet"); // iterate through the descendants and print non-Text and non-Comment values IteratorIterable<Content> contents = web_app.getDescendants(); while (contents.hasNext()) { Content web_app_content = contents.next(); if (!web_app_content.getCType().equals(CType.Text) && !web_app_content.getCType().equals(CType.Comment)) { System.out.println(web_app_content.toString()); } } // get comments using a Comment filter IteratorIterable<Comment> comments = web_app.getDescendants(Filters.comment()); while (comments.hasNext()) { Comment comment = comments.next(); System.out.println(comment); } }} |
In this tutorial we look at how to use SAXBuilder to create a JDOM2 Document such that the SAXBuilder validates the XML using the DTD before creating the JDOM2 document. If you are looking for a way to create JDOM2 Document using the SAXBuilder but without any validation then this tutorial explains just that.
We explain the validation using two XML document. The first XML is invalid and therefore fails the validation step. The second XML is valid.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 | package com.studytrails.xml.jdom;import java.io.File;import java.io.IOException;import org.jdom2.DocType;import org.jdom2.Document;import org.jdom2.JDOMException;import org.jdom2.input.SAXBuilder;import org.jdom2.input.sax.XMLReaders;public class JdomUsingSAXBuilderDtdValidating { private static String file1 = "tomcat-web-dtd-bad.xml"; private static String file2 = "tomcat-web-dtd.xml"; public static void main(String[] args) throws JDOMException, IOException { SAXBuilder builder = new SAXBuilder(XMLReaders.DTDVALIDATING); Document jdomDocValidatedFalse = builder.build(new File(file1)); // throws an error since the XML does not validate. We correct it and // then run this again. comment the lines above and run this again. SAXBuilder builder2 = new SAXBuilder(XMLReaders.DTDVALIDATING); Document jdomDocValidatedTrue = builder2.build(new File(file2)); System.out.println(jdomDocValidatedTrue.hasRootElement()); // prints true DocType docType = jdomDocValidatedTrue.getDocType(); System.out.println(docType.getPublicID()); // prints -//Sun Microsystems, Inc.//DTD Web Application 2.3//EN System.out.println(docType.getSystemID()); // prints http://java.sun.com/dtd/web-app_2_3.dtd }} |
In the earlier tutorials we saw how to build a JDOM2 document using SAXBuilder. We also saw how to validate the document using DTD while using the SAXBuilder. In this tutorial we look at how to use the SAXBuilder that validates against an XSD. The example below shows how to use an internally defined XSD. The example after that shows how to define an XSD externally.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 | package com.studytrails.xml.jdom;import java.io.File;import java.io.IOException;import org.jdom2.Document;import org.jdom2.JDOMException;import org.jdom2.input.SAXBuilder;import org.jdom2.input.sax.XMLReaders;public class JdomUsingSAXBuilderXsdValidating { private static String file1 = "tomcat-web-xsd-bad.xml"; private static String file2 = "tomcat-web-xsd.xml"; public static void main(String[] args) throws JDOMException, IOException { // SAXBuilder builder = new SAXBuilder(XMLReaders.XSDVALIDATING); // Document jdomDocValidatedFalse = builder.build(new File(file1)); // throws an error since the XSD validation fails. comment the lines // above and rerun the example SAXBuilder builder2 = new SAXBuilder(XMLReaders.XSDVALIDATING); Document jdomDocValidatedTrue = builder2.build(new File(file2)); System.out.println(builder2.getSAXHandlerFactory().getClass()); // prints class org.jdom2.input.sax.DefaultSAXHandlerFactory System.out.println(builder2.getJDOMFactory().getClass()); // class org.jdom2.DefaultJDOMFactory System.out.println(builder2.getXMLReaderFactory().getClass()); // class org.jdom2.input.sax.XMLReaders }} |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | package com.studytrails.xml.jdom;import java.io.File;import java.io.IOException;import javax.xml.XMLConstants;import javax.xml.validation.Schema;import javax.xml.validation.SchemaFactory;import org.jdom2.Document;import org.jdom2.JDOMException;import org.jdom2.input.SAXBuilder;import org.jdom2.input.sax.XMLReaderJDOMFactory;import org.jdom2.input.sax.XMLReaderSchemaFactory;import org.jdom2.input.sax.XMLReaderXSDFactory;import org.xml.sax.SAXException;public class JdomUsingSAXBuilderExternalXsdValidating { private static String file = "commons-dbcp-pom.xml"; private static String schemaFile = "maven-4.0.0.xsd"; public static void main(String[] args) throws JDOMException, IOException, SAXException { //METHOD 1 // Define a schema factory and a schema SchemaFactory schemaFactory = SchemaFactory.newInstance(XMLConstants.W3C_XML_SCHEMA_NS_URI); Schema schema = schemaFactory.newSchema(new File(schemaFile)); // create an XMLReaderJDOMFactory by passing the schema XMLReaderJDOMFactory factory = new XMLReaderSchemaFactory(schema); // create a SAXBuilder using the XMLReaderJDOMFactory SAXBuilder sb = new SAXBuilder(factory); Document doc = sb.build(new File(file)); System.out.println(doc.getRootElement().getName()); //METHOD 2 File xsd = new File(schemaFile); //Create the XMLReaderJDOMFacotory directly using the schema file instead of ‘Schema‘ XMLReaderJDOMFactory factory2 = new XMLReaderXSDFactory(schemaFile); SAXBuilder sb2 = new SAXBuilder(factory2); Document doc2 = sb2.build(new File(file)); System.out.println(doc2.getRootElement().getName()); }} |
SAXBuilder provides methods to build JDOM2 Documents using a third party SAX Parser. It has three parts
JDOM2 provides a DOMBuilder that can be used to build a JDOM2 Document from a org.w3c.dom.Document. If there are namespace declarations in the xml document then make sure that while parsing the XML document the setNamespaceAware method of the DocumentBuilderFactory is set to true. Before we look at an example note that it is recommended to use a SAXBuilder to build a JDOM2 Document instead of a DOMBuilder since there is no reason to have both the DOM and JDOM2 Document in memory. Lets look at an example now.
package com.studytrails.xml.jdom;
import java.io.IOException;
import java.util.List;
import javax.xml.parsers.DocumentBuilder;
import javax.xml.parsers.DocumentBuilderFactory;
import javax.xml.parsers.ParserConfigurationException;
import org.jdom2.Document;
import org.jdom2.Element;
import org.jdom2.input.DOMBuilder;
import org.xml.sax.SAXException;
public class CreateJdomFromDom {
private static String xmlSource = "http://feeds.bbci.co.uk/news/technology/rss.xml?edition=int";
public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException {
// create the w3c DOM document from which JDOM is to be created
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
// we are interested in making it namespace aware.
factory.setNamespaceAware(true);
DocumentBuilder dombuilder = factory.newDocumentBuilder();
org.w3c.dom.Document w3cDocument = dombuilder.parse(xmlSource);
// w3cDocument is the w3c DOM object. we now build the JDOM2 object
// the DOMBuilder uses the DefaultJDOMFactory to create the JDOM2
// objects.
DOMBuilder jdomBuilder = new DOMBuilder();
// jdomDocument is the JDOM2 Object
Document jdomDocument = jdomBuilder.build(w3cDocument);
// The root element is the root of the document. we print its name
System.out.println(jdomDocument.getRootElement().getName()); // prints
// "rss"
}
}
In the previous examples we saw how to bulid a JDOM2 document from w3c Document. We also saw how to build a JDOM2 Document using a SAXBuilder. In this example we look at how to create a JDOM2 document using a StAXEventBuilder or a StAXStreamBuilder.
StAXEventBuilder builds a JDOM2 document using a StAX based XMLEventReader. We first create an XMLInputFactory. We then use the factory to create an XMLEventReader by passing the XML file. The XMLEventReader is then passed to the StAXEventBuilder. Note that StAXEvenBuilder has no control over the validation process and therefore to create a validating builder set the appropriate property on the XMLInputFactory. Here‘s an example. The XML file can be downloaded from here
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | package com.studytrails.xml.jdom;import java.io.FileNotFoundException;import java.io.FileReader;import javax.xml.stream.XMLEventReader;import javax.xml.stream.XMLInputFactory;import javax.xml.stream.XMLStreamException;import org.jdom2.Document;import org.jdom2.JDOMException;import org.jdom2.input.StAXEventBuilder;public class JdomUsingXMLEventReader { public static void main(String[] args) throws FileNotFoundException, XMLStreamException, JDOMException { XMLInputFactory factory = XMLInputFactory.newFactory(); XMLEventReader reader = factory.createXMLEventReader(new FileReader("bbc.xml")); StAXEventBuilder builder = new StAXEventBuilder(); Document jdomDoc = builder.build(reader); System.out.println(jdomDoc.getRootElement().getName()); // prints "rss" System.out.println(jdomDoc.getRootElement().getNamespacesIntroduced().get(1).getURI()); // prints "http://search.yahoo.com/mrss/" }} |
StAXStreamBuilder builds a JDOM2 document from a StAX based XMLStreamReader. For JDOM2 XMLStreamReader is more efficient then XMLEventReader and should be the first choice. Here‘s an example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 | package com.studytrails.xml.jdom;import java.io.FileNotFoundException;import java.io.FileReader;import javax.xml.stream.XMLInputFactory;import javax.xml.stream.XMLStreamException;import javax.xml.stream.XMLStreamReader;import org.jdom2.Document;import org.jdom2.JDOMException;import org.jdom2.input.StAXStreamBuilder;public class JdomUsingXMLStreamReader { public static void main(String[] args) throws FileNotFoundException, XMLStreamException, JDOMException { XMLInputFactory factory = XMLInputFactory.newFactory(); XMLStreamReader reader = factory.createXMLStreamReader(new FileReader("bbc.xml")); StAXStreamBuilder builder = new StAXStreamBuilder(); Document jdomDoc = builder.build(reader); System.out.println(jdomDoc.getRootElement().getName()); // prints "rss" System.out.println(jdomDoc.getRootElement().getNamespacesIntroduced().get(1).getURI());// prints "http://search.yahoo.com/mrss/" }} |
JDOM2 has three methods that accepts Filters while obtaining data. The three methods are
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 | package com.studytrails.xml.jdom; import java.io.IOException;import java.util.Iterator;import java.util.List;import org.jdom2.Content;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.JDOMException;import org.jdom2.Text;import org.jdom2.filter.ContentFilter;import org.jdom2.filter.Filter;import org.jdom2.filter.Filters;import org.jdom2.input.SAXBuilder;import org.jdom2.util.IteratorIterable; public class FilterJdom2 { public static void main(String[] args) throws JDOMException, IOException { SAXBuilder jdomBuilder = new SAXBuilder(); Document jdomDocument = jdomBuilder.build(xmlSource); Element rss = jdomDocument.getRootElement(); Element channel = rss.getChild("channel"); Element title = channel.getChild("title"); // Content Filter ContentFilter filter = new ContentFilter(ContentFilter.PI); List<content> cDataContents = jdomDocument.getContent(filter); Iterator<content> cDataIterator = cDataContents.iterator(); while (cDataIterator.hasNext()) { Content cdata = cDataIterator.next(); // System.out.println(cdata.getCType()); // System.out.println(cdata.getValue()); } // Text Filter Filter<text> textFilter = Filters.text(); IteratorIterable<text> channelTextList = channel.getDescendants(textFilter); while (channelTextList.hasNext()) { Text channelText = channelTextList.next(); // System.out.println(channelText.getValue()); } // or filter Filter<element> filters = (Filter<element>) Filters.element("thumbnail", rss.getNamespace("media")).or(Filters.element("link")); IteratorIterable<element> thumbnailsAndLinks = channel.getDescendants(filters); while (thumbnailsAndLinks.hasNext()) { Element thumbnailorLink = thumbnailsAndLinks.next(); // System.out.println(thumbnailorLink.getName()); } // negate filter Filter<element> negateFilter = (Filter<element>) Filters.element("link").negate().and(Filters.text().negate()); IteratorIterable<element> nonLinkElements = channel.getDescendants(negateFilter); while (nonLinkElements.hasNext()) { Element nonLinkElement = nonLinkElements.next(); System.out.println(nonLinkElement.getName()); } }}</element></element></element></element></element></element></text></text></content></content> |
JDOM2 handles namespaces very well. However, there are three areas where confusion may arise while using namespaces. In this tutorial we look at them.
While creating new elements in JDOM2, it is possible to pass the namespace to which the element should belong. However, the namespace only applies to the Element and not its children. i.e. the namespace assignment does not cascade. Here‘s an example
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 | package com.studytrails.xml.jdom;import org.jdom2.Attribute;import org.jdom2.Comment;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.Namespace;import org.jdom2.output.Format;import org.jdom2.output.XMLOutputter;public class NewElementAndNamespace { public static void main(String[] args) { // create the jdom Document jdomDoc = new Document(); // create root element Element rootElement = new Element("Root", namespace); jdomDoc.setRootElement(rootElement); // add a comment Comment comment = new Comment("This is a comment"); rootElement.addContent(comment); // add child Element child1 = new Element("child1", namespace); child1.addContent("This is child 1"); // add child 2 Element child2 = new Element("child2"); child2.addContent("This is child 2"); // add attribute Attribute attr1 = new Attribute("key1", "value1"); child1.setAttribute(attr1); rootElement.addContent(child1); rootElement.addContent(child2); // Output as XML // create XMLOutputter XMLOutputter xml = new XMLOutputter(); // we want to format the xml. This is used only for demonstration. // pretty formatting adds extra spaces and is generally not required. xml.setFormat(Format.getPrettyFormat()); System.out.println(xml.outputString(jdomDoc)); }} |
1 2 3 4 5 6 | <!--?xml version="1.0" encoding="UTF-8"?--> <!--This is a comment--> <p:child1 key1="value1">This is child 1</p:child1> <child2>This is child 2</child2></p:root> |
In the next example we read the XML created in the example above. (test.xml) we then search for a child named ‘child1‘, first without specifying a namespace and then after specifying a namespace. In the first case it is not able to find the child, in the second case it does
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 | package com.studytrails.xml.jdom;import java.io.IOException;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.JDOMException;import org.jdom2.Namespace;import org.jdom2.input.SAXBuilder;public class GetChildInANamespace { private static String xmlTestFile = "test.xml"; public static void main(String[] args) throws JDOMException, IOException { SAXBuilder jdomBuilder = new SAXBuilder(); Document jdomDocument = jdomBuilder.build(xmlTestFile); // the root element Element root = jdomDocument.getRootElement(); // lets search for a child named child1 System.out.println(root.getChild("child1")); // prints null // prints [Element: <p:child1 [Namespace: http://namespaceuri]/>] }} |
JDOM2 XPath allows searching for an element with a specific Namespace. If an element is specified in a new Namespace then pass that JDOM2 Namespace object when searching for that element. If the XML defines a new default Namespace then create a new ‘dummy‘ JDOM2 Namespace object with any prefix and the default Namespace URI specified in the XML. Access elements in the XML using the prefix of the ‘dummy‘ JDOM2 Namespace object. . See example for more details. The example uses the following xml
1 2 3 4 5 6 | <!--?xml version="1.0" encoding="UTF-8"?--> <!--This is a comment --> <p:child1>This is child 1</p:child1> <child2>This is child 2</child2></root> |
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 | package com.studytrails.xml.jdom;import java.io.IOException;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.JDOMException;import org.jdom2.Namespace;import org.jdom2.filter.Filters;import org.jdom2.input.SAXBuilder;import org.jdom2.xpath.XPathExpression;import org.jdom2.xpath.XPathFactory;public class XpathAndNamespace { private static String xmlTestFile = "test2.xml"; public static void main(String[] args) throws JDOMException, IOException { // read the XML into a JDOM2 document. SAXBuilder jdomBuilder = new SAXBuilder(); Document jdomDocument = jdomBuilder.build(xmlTestFile); XPathFactory xFactory = XPathFactory.instance(); XPathExpression<element> expr = xFactory.compile("//child2", Filters.element()); Element child2 = expr.evaluateFirst(jdomDocument); System.out.println(child2); // prints null // we create a dummy namespace prefix that points to the default // namespace and then access the element using that namespace XPathExpression<Element> expr2 = xFactory.compile("//a:child2", Filters.element(), null, defaultNs); child2 = expr2.evaluateFirst(jdomDocument); System.out.println(child2); // prints [Element: <child2 [Namespace: http://nondefaulnamespace]/>] // search for a child from another namespace Namespace anotherNS = Namespace.getNamespace("p", "http//anothernamespace"); XPathExpression<Element>> expr3 = xFactory.compile("//p:child1", Filters.element(), null, anotherNS); Element child1 = expr3.evaluateFirst(jdomDocument); System.out.println(child1); // prints [Element: <p:child1 [Namespace: http//anothernamespace]/>] }}</element> |
In the earlier tutorials we looked at how to create a JDOM2 document from SAX ,DOM and StAX. In this tutorial we learn how to output JDOM2 as XML, DOM, SAX, StAXEvent and StaxStream. Lets look at the important classes
Now lets see the outputters in action
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 | package com.studytrails.xml.jdom;import javax.xml.stream.XMLStreamException;import javax.xml.stream.events.XMLEvent;import javax.xml.stream.util.XMLEventConsumer;import org.jdom2.Attribute;import org.jdom2.Comment;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.JDOMException;import org.jdom2.output.DOMOutputter;import org.jdom2.output.Format;import org.jdom2.output.SAXOutputter;import org.jdom2.output.StAXEventOutputter;import org.jdom2.output.XMLOutputter;import org.w3c.dom.Node;import org.w3c.dom.NodeList;import org.xml.sax.Attributes;import org.xml.sax.SAXException;import org.xml.sax.helpers.DefaultHandler;public class JDomOutputterExamples { public static void main(String[] args) throws JDOMException, XMLStreamException { // create the jdom Document jdomDoc = new Document(); // create root element Element rootElement = new Element("Root"); jdomDoc.setRootElement(rootElement); // add a comment Comment comment = new Comment("This is a comment"); rootElement.addContent(comment); // add child Element child1 = new Element("child"); child1.addContent("This is child 1"); // add attribute Attribute attr1 = new Attribute("key1", "value1"); child1.setAttribute(attr1); rootElement.addContent(child1); // Output as XML // create XMLOutputter XMLOutputter xml = new XMLOutputter(); // we want to format the xml. This is used only for demonstration. pretty formatting adds extra spaces and is generally not required. xml.setFormat(Format.getPrettyFormat()); System.out.println(xml.outputString(jdomDoc)); // Output the JDOM2 document as a w3c Document // create the DOM Outputter DOMOutputter domOutputer = new DOMOutputter(); // create the w3c Document from the JDOM2 Document org.w3c.dom.Document dom = domOutputer.output(jdomDoc); System.out.println(dom.getNodeName()); // we iterate through the w3c Document and print the elements org.w3c.dom.Element rootElementDom = dom.getDocumentElement(); System.out.println(rootElementDom.getNodeName()); NodeList children = rootElementDom.getChildNodes(); for (int i = 0; i < children.getLength(); i++) { Node child = children.item(i); System.out.println("Node Name-->" + child.getNodeName()); System.out.println("Node value-->" + child.getNodeValue()); System.out.println("Node Attributes-->" + child.getAttributes()); } // Output the JDOM2 as SAX events. Pass in the ContentHandler that will handle the events. SAXOutputter saxOutputer = new SAXOutputter(new myContentHandler()); saxOutputer.output(jdomDoc); // Output as StaxEvents. Pass in a custom XMLEventConsumer. StAXEventOutputter staxOutputter = new StAXEventOutputter(); staxOutputter.output(jdomDoc, new XMLEventConsumer() { @Override public void add(XMLEvent event) throws XMLStreamException { int eventType = event.getEventType(); if (XMLEvent.COMMENT == eventType) { System.out.println(event.toString()); } if (XMLEvent.START_ELEMENT == eventType) { System.out.println(event.asStartElement().getName()); } } }); } public static class myContentHandler extends DefaultHandler { @Override public void startDocument() throws SAXException { System.out.println("Start Doc"); super.startDocument(); } @Override public void startElement(String uri, String localName, String qName, Attributes attributes) throws SAXException { System.out.println("Start " + localName); super.startElement(uri, localName, qName, attributes); } }} |
JDOM2 has classes that perform XSL transformation of the JDOM2 document. The input to the transformation is the JDOM2 document and an XML stylesheet and the output is whatever transformation the stylesheet specifies. In the example below we look at JDOM2 to do HTML transformation. By default, JDOM2 uses the JAXP TrAX classes for transformation. The important classes are :
com.icl.saxon.TransformerFactoryImplnet.sf.saxon.TransformerFactoryImplorg.apache.xalan.processor.TransformerFactoryImpljd.xml.xslt.trax.TransformerFactoryImploracle.xml.jaxp.JXSAXTransformerFactory1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 | package com.studytrails.xml.jdom;import java.io.IOException;import javax.xml.parsers.DocumentBuilder;import javax.xml.parsers.DocumentBuilderFactory;import javax.xml.parsers.ParserConfigurationException;import javax.xml.transform.Transformer;import javax.xml.transform.TransformerException;import javax.xml.transform.TransformerFactory;import javax.xml.transform.TransformerFactoryConfigurationError;import javax.xml.transform.stream.StreamSource;import org.jdom2.Document;import org.jdom2.input.DOMBuilder;import org.jdom2.output.Format;import org.jdom2.output.XMLOutputter;import org.jdom2.transform.JDOMResult;import org.jdom2.transform.JDOMSource;import org.xml.sax.SAXException;public class JdomTransformationExample { public static void main(String[] args) throws ParserConfigurationException, SAXException, IOException, TransformerFactoryConfigurationError, TransformerException { // read the XML to a JDOM2 document DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance(); factory.setNamespaceAware(true); DocumentBuilder dombuilder = factory.newDocumentBuilder(); org.w3c.dom.Document w3cDocument = dombuilder.parse("bbc.xml"); DOMBuilder jdomBuilder = new DOMBuilder(); Document jdomDocument = jdomBuilder.build(w3cDocument); // create the JDOMSource from JDOM2 document JDOMSource source = new JDOMSource(jdomDocument); // create the transformer Transformer transformer = TransformerFactory.newInstance().newTransformer(new StreamSource("bbc.xsl")); // create the JDOMResult object JDOMResult out = new JDOMResult(); // perform the transformation transformer.transform(source, out); XMLOutputter outputter = new XMLOutputter(Format.getPrettyFormat()); System.out.println(outputter.outputString(out.getDocument())); }} |
Xpath is a query language specification that is used to query an XML path. It provides a language that helps in retrieving specific nodes of an XML document using a query syntax. This tutorial does not explain XPath and assumes that the user is aware of XPath. What we explain here is how to use Xpath to query a JDOM2 document. The default implementation for JDOM2 is jaxen. To run the below examples jaxen needs to be in the classpath. To query the JDOM2 document first compile an XPathExpression using an XPathFactory. Use the expression to then evaluate the JDOM2 document.
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 | package com.studytrails.xml.jdom; import java.io.IOException;import java.util.List;import org.jdom2.Document;import org.jdom2.Element;import org.jdom2.JDOMException;import org.jdom2.Namespace;import org.jdom2.filter.Filters;import org.jdom2.input.SAXBuilder;import org.jdom2.xpath.XPathExpression;import org.jdom2.xpath.XPathFactory; public class XPathExample2 { public static void main(String[] args) throws JDOMException, IOException { // read the XML into a JDOM2 document. SAXBuilder jdomBuilder = new SAXBuilder(); Document jdomDocument = jdomBuilder.build(xmlSource); // use the default implementation XPathFactory xFactory = XPathFactory.instance(); // System.out.println(xFactory.getClass()); // select all links XPathExpression<Element> expr = xFactory.compile("//link", Filters.element()); List<Element> links = expr.evaluate(jdomDocument); for (Element linkElement : links) { System.out.println(linkElement.getValue()); } // select all links in image element expr = xFactory.compile("//image/link", Filters.element()); List<Element> links2 = expr.evaluate(jdomDocument); for (Element linkElement : links2) { System.out.println(linkElement.getValue()); } // get the media namespace Namespace media = jdomDocument.getRootElement().getNamespace("media"); // find all thumbnail elements from the media namespace where the // attribute widht has a value > 60 expr = xFactory.compile("//media:thumbnail[@width>60.00]", Filters.element(), null, media); // find the first element in the document and get its attribute named ‘url‘ System.out.println(expr.evaluateFirst(jdomDocument).getAttributeValue("url")); // find the child element of channel whose name is title. find the // descendant of item with name title. Element firstTitle = xFactory.compile("//channel/child::item/descendant::title", Filters.element()).evaluateFirst(jdomDocument); System.out.println(firstTitle.getValue()); } } |
标签:des style blog http color io os ar java
原文地址:http://www.cnblogs.com/godsay1983/p/4001176.html