标签:cnn sso 彩色 https 经典的 尺寸 磁盘 nbsp gen
Girshick, Ross, et al. “Rich feature hierarchies for accurate object detection and semantic segmentation.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2014.
R-CNN的全称是Region-CNN,它可以说是第一个成功将深度学习应用到目标检测上的算法。后面要讲到的Fast R-CNN、Faster R-CNN全部都是建立在R-CNN基础上的。
传统的目标检测算法大多数以图像识别为基础。一般可以在图片上使用穷举法或者滑动窗口选出所有物体可能出现的区域框,对这些区域框提取特征并进行使用图像识别分类方法,得到所有分类成功的区域后,通过非极大值抑制输出结果。
R-CNN遵循传统目标检测的思路,同样采用提取框,对每个框提取特征、图像分类、非极大值抑制四个步骤进行目标检测、只不过在进行了部分改进。
在训练时使用两个数据库:
一个较大的识别库(ImageNet ILSVC 2012):标定每张图片中物体的类别。一千万图像,1000类。
一个较小的检测库(PASCAL VOC 2007):标定每张图片中,物体的类别和位置。一万图像,20类。
使用识别库进行预训练,而后用检测库调优参数。最后在检测库上评测。
数据集采用pascal VOC,这个数据集的object一共有20个类别。首先用select search方法在每张图像上选取约2000个region proposal,region proposal就是object有可能出现的位置。然后根据这些region proposal构造训练和测试样本,注意这些region proposal的大小不一,另外样本的类别是21个(包括了背景)。
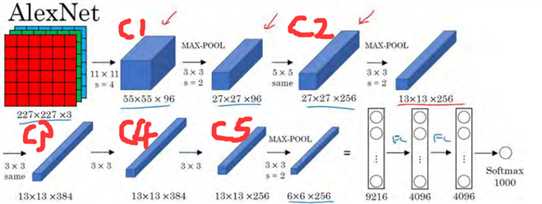
然后是预训练,即在ImageNet数据集下,用AlexNet进行训练。然后再在我们的数据集上fine-tuning,网络结构不变(除了最后一层输出由1000改为21),输入是前面的region proposal进行尺寸变换到一个统一尺寸227*227,保留f7的输出特征2000*4096维。
针对每个类别(一共20类)训练一个SVM分类器,以f7层的输出作为输入,训练SVM的权重4096*20维,所以测试时候会得到2000*20的得分输出,且测试的时候会对这个得分输出做NMS(non-maximun suppression),简单讲就是去掉重复框的过程。同时针对每个类别(一共20类)训练一个回归器,输入是pool5的特征和每个样本对的坐标即长宽。
R-CNN的训练可以分成以下步骤:
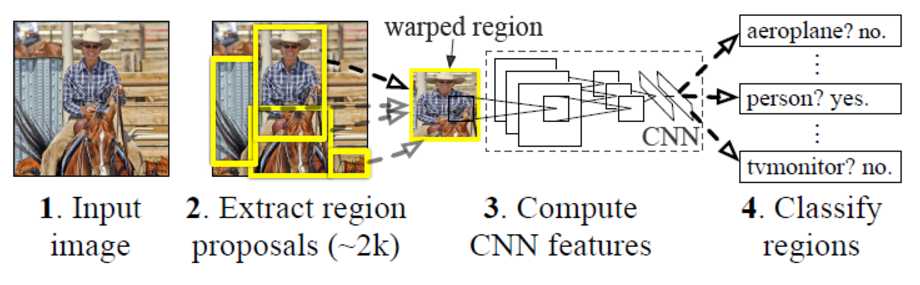
R-CNN的测试可以分成以下步骤:
输入一张图像,利用selective search得到2000个region proposal。
对所有region proposal变换到固定尺寸并作为已训练好的CNN网络的输入,得到f7层的4096维特征,所以f7层的输出是2000*4096。
对每个类别,采用已训练好的这个类别的svm分类器对提取到的特征打分,所以SVM的weight matrix是4096*N,N是类别数,这里一共有20个SVM,N=20注意不是21。得分矩阵是2000*20,表示每个region proposal属于某一类的得分。
采用non-maximun suppression(NMS)对得分矩阵中的每一列中的region proposal进行剔除,就是去掉重复率比较高的几个region proposal,得到该列中得分最高的几个region proposal。NMS的意思是:举个例子,对于2000*20中的某一列得分,找到分数最高的一个region proposal,然后只要该列中其他region proposal和分数最高的IOU超过某一个阈值,则剔除该region proposal。这一轮剔除完后,再从剩下的region proposal找到分数最高的,然后计算别的region proposal和该分数最高的IOU是否超过阈值,超过的继续剔除,直到没有剩下region proposal。对每一列都这样操作,这样最终每一列(即每个类别)都可以得到一些region proposal。
尽管R-CNN的识别框架与传统方法区别不是很大,但是得益于CNN优异的特征提取能力,R-CNN的效果还是比传统方法好很多。如在VOC2007数据集上,传统方法最高的平均精确度mAp为40%左右,而R-CNN的mAp达到了58.5%。
R-CNN的缺点是计算量大。R-CNN流程较多,包括region proposal的选取,训练卷积神经网络(softmax classifier,log loss),训练SVM(hinge loss)和训练 regressor(squared loss),这使得训练时间非常长(84小时),占用磁盘空间也大。在训练卷积神经网络的过程中对每个region proposal都要计算卷积,这其中重复的太多不必要的计算,试想一张图像可以得到2000多个region proposal,大部分都有重叠,因此基于region proposal卷积的计算量太大,而这也正是之后Fast R-CNN主要解决的问题。
标签:cnn sso 彩色 https 经典的 尺寸 磁盘 nbsp gen
原文地址:https://www.cnblogs.com/zyly/p/9246221.html