标签:出现 搜索 iter 构建 效率 odi 集合类 access dHash
Java容器可分为两大类:
● Collection
* List
ArrayList
LinkedList
Vector(了解,已过时)
* Set
HashSet
TreeSet
LinkedHashSet
● Map
* HashMap
* TreeMap
LinkedHashMap
ConcurrentHashMap
Hashtable(了解,已过时)
共同点:
区别:
同步性:
扩容大小:
共同点:
区别:
同步性:
是否允许为null:
contains方法
继承不同:
共同点:
不同点:
存储结构不同:
元素是否可重复:
是否有序:
我们知道Set集合实际大都使用的是Map集合的put方法来添加元素。
以HashSet为例,HashSet里的元素不能重复,在源码(HashMap)是这样体现的:
// 1. 如果key 相等
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
e = p;
// 2. 修改对应的value
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
添加元素的时候,如果key(也对应的Set集合的元素)相等,那么则修改value值。而在Set集合中,value值仅仅是一个Object对象罢了(该对象对Set本身而言是无用的)。也就是说:Set集合如果添加的元素相同时,是根本没有插入的(仅修改了一个无用的value值)!从源码(HashMap)中也看出来,==和equals()方法都有使用!
ArrayList的底层是数组,LinkedList的底层是双向链表。
ArrayList的增删未必就是比LinkedList要慢。
如果删除操作的位置是在中间。由于LinkedList的消耗主要是在遍历上,ArrayList的消耗主要是在移动和复制上(底层调用的是arraycopy()方法,是native方法)。
这个我在前面的文章中也没有详细去讲它们,只是大概知道的是:Iterator替代了Enumeration,Enumeration是一个旧的迭代器了。
与Enumeration相比,Iterator更加安全,因为当一个集合正在被遍历的时候,它会阻止其它线程去修改集合。
区别有三点:
Java1.5并发包(java.util.concurrent)包含线程安全集合类,允许在迭代时修改集合。
一部分类为:
需要同时重写该类的hashCode()方法和它的equals()方法。
一般来说,我们会认为:只要两个对象的成员变量的值是相等的,那么我们就认为这两个对象是相等的!因为,Object底层比较的是两个对象的地址,而对我们开发来说这样的意义并不大~这也就为什么我们要重写equals()方法。重写了equals()方法,就要重写hashCode()的方法。因为equals()认定了这两个对象相同,而同一个对象调用hashCode()方法时,是应该返回相同的值的!
确定完我们的集合类型,我们接下来确定使用该集合类型下的哪个子类~我认为可以简单分成几个步骤:
是否需要同步
迭代时是否需要有序(插入顺序有序)
是否需要排序(自然顺序或者手动排序)
ArrayList的默认初始容量为10,要插入大量数据的时候需要不断扩容,而扩容是非常影响性能的。因此,现在明确了10万条数据了,我们可以直接在初始化的时候就设置ArrayList的容量!
这样就可以提高效率了。
将这篇文章作为集合的总结篇,用如下框架图来作为本篇的总结。(图片可保存到本地查看或在新建标签页中打开)
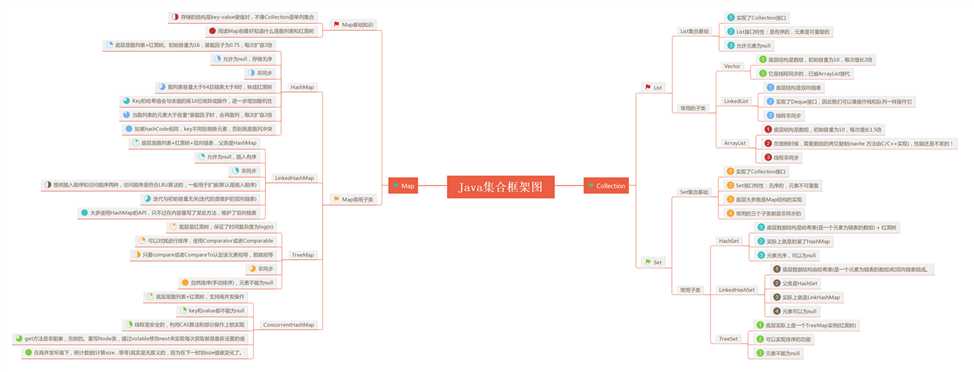
原文参考【Java知音】微信公众号
标签:出现 搜索 iter 构建 效率 odi 集合类 access dHash
原文地址:https://www.cnblogs.com/Kevin-ZhangCG/p/9246634.html