标签:towards seq remember ural oom targe ica ppi asc
Refer to :
https://towardsdatascience.com/the-fall-of-rnn-lstm-2d1594c74ce0
(The fall of RNN / LSTM)
“hierarchical neural attention encoder”, shown in the figure below:
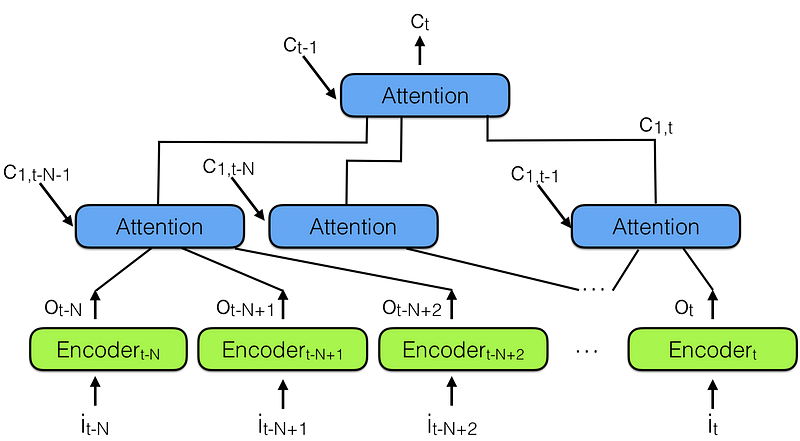
Hierarchical neural attention encoder
A better way to look into the past is to use attention modules to summarize all past encoded vectors into a context vector Ct.
Notice there is a hierarchy of attention modules here, very similar to the hierarchy of neural networks. This is also similar to Temporal convolutional network (TCN), reported in Note 3 below.
In the hierarchical neural attention encoder multiple layers of attention can look at a small portion of recent past, say 100 vectors, while layers above can look at 100 of these attention modules, effectively integrating the information of 100 x 100 vectors. This extends the ability of the hierarchical neural attention encoder to 10,000 past vectors.
This is the way to look back more into the past and be able to influence the future.
But more importantly look at the length of the path needed to propagate a representation vector to the output of the network: in hierarchical networks it is proportional to log(N) where N are the number of hierarchy layers. This is in contrast to the T steps that a RNN needs to do, where T is the maximum length of the sequence to be remembered, and T >> N.
It is easier to remember sequences if you hop 3–4 times, as opposed to hopping 100 times!
The fall of RNN / LSTM-hierarchical neural attention encoder, Temporal convolutional network (TCN)
标签:towards seq remember ural oom targe ica ppi asc
原文地址:https://www.cnblogs.com/quinn-yann/p/9249309.html