标签:exe log main ice 需要 调用 -o 修改 false
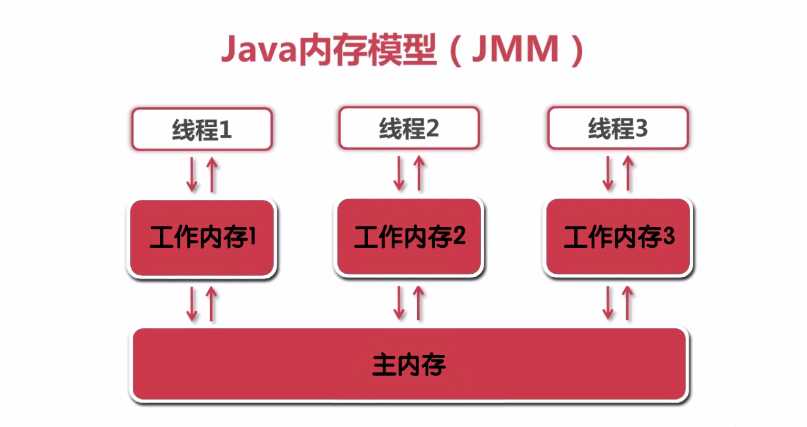
什么是java的内存模型?
1.编译器优化的重排序(编译器优化)
2.指令级并行重排序(处理器优化)
3.内存系统的重排序(处理器优化)
如果两个操作访问同一个变量,且这两个操作中有一个为写操作,此时这两个操作之间就存在数据依赖。数据依赖分下列三种类型:
| 名称 | 代码示例 | 说明 |
| 写后读 | a = 1;b = a; | 写一个变量之后,再读这个位置。 |
| 写后写 | a = 1;a = 2; | 写一个变量之后,再写这个变量。 |
| 读后写 | a = b;b = 1; | 读一个变量之后,再写这个变量。 |
上面三种情况,只要重排序两个操作的执行顺序,程序的执行结果将会被改变。所以,编译器和处理器在重排序时,会遵守数据依赖性,编译器和处理器不会改变存在数据依赖关系的两个操作的执行顺序。也就是说:在单线程环境下,指令执行的最终效果应当与其在顺序执行下的效果一致,否则这种优化便会失去意义。这句话有个专业术语叫做as-if-serial semantics (as-if-serial语义)
int num1=1;//第一行
int num2=2;//第二行
int sum=num1+num;//第三行
导致共享变量在线程间不可见的原因:
答案是:不一定能看到。
由于操作1和操作2没有数据依赖关系,编译器和处理器可以对这两个操作重排序;同样,操作3和操作4没有数据依赖关系,编译器和处理器也可以对这两个操作重排序。让我们先来看看,当操作1和操作2重排序时,可能会产生什么效果?
执行顺序是:2 -> 3 -> 4 -> 1 (这是完全存在并且合理的一种顺序,如果你不能理解,请先了解CPU是如何对多个线程进行时间分配的)操作3和操作4重排序后,因为操作3和操作4存在控制依赖关系。当代码中存在控制依赖性时,会影响指令序列执行的并行度。为此,编译器和处理器会采用猜测(Speculation)执行来克服控制相关性对并行度的影响。以处理器的猜测执行为例,执行线程B的处理器可以提前读取并计算a*a,然后把计算结果临时保存到一个名为重排序缓冲(reorder buffer ROB)的硬件缓存中。当接下来操作3的条件判断为真时,就把该计算结果写入变量i中。
我们可以看出,猜测执行实质上对操作3和4做了重排序。重排序在这里破坏了多线程程序的语义!


package com.xidian.count; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Semaphore; import com.xidian.annotations.ThreadSafe; import lombok.extern.slf4j.Slf4j; @Slf4j @ThreadSafe public class CountExample3 { // 请求总数 public static int clientTotal = 5000; // 同时并发执行的线程数 public static int threadTotal = 200; public static int count = 0; public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); final Semaphore semaphore = new Semaphore(threadTotal); final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal ; i++) { executorService.execute(() -> { try { semaphore.acquire(); add(); semaphore.release(); } catch (Exception e) { log.error("exception", e); } countDownLatch.countDown(); }); } countDownLatch.await(); executorService.shutdown(); log.info("count:{}", count); } private synchronized static void add() { count++; } }
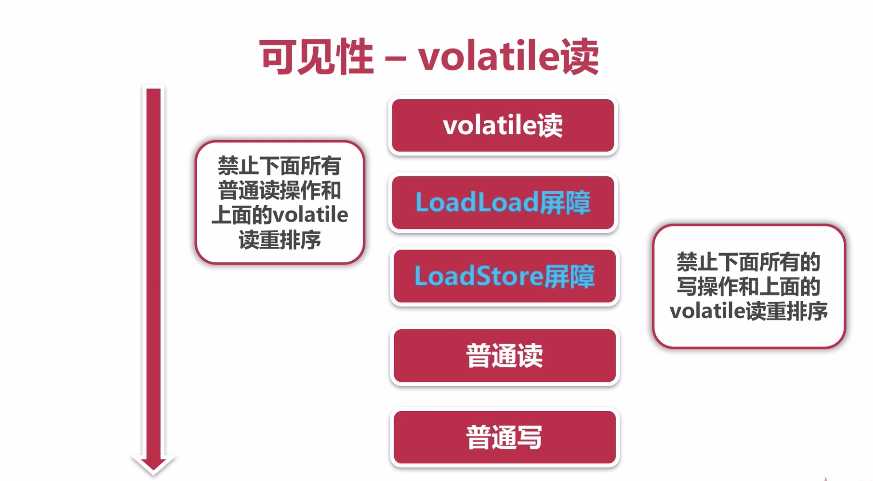
深入来说:通过加入内存屏障和禁止重排序优化来实现的。
对volatile变量执行写操作时,会在写操作后加入一条store屏障指令
对volatile变量执行读操作时,会在读操作前加入一条load屏障指令

package com.xidian.count; import java.util.concurrent.CountDownLatch; import java.util.concurrent.ExecutorService; import java.util.concurrent.Executors; import java.util.concurrent.Semaphore; import com.xidian.annotations.NotThreadSafe; import lombok.extern.slf4j.Slf4j; @Slf4j @NotThreadSafe public class CountExample4 { // 请求总数 public static int clientTotal = 5000; // 同时并发执行的线程数 public static int threadTotal = 200; public static volatile int count = 0; public static void main(String[] args) throws Exception { ExecutorService executorService = Executors.newCachedThreadPool(); final Semaphore semaphore = new Semaphore(threadTotal); final CountDownLatch countDownLatch = new CountDownLatch(clientTotal); for (int i = 0; i < clientTotal ; i++) { executorService.execute(() -> { try { semaphore.acquire(); add(); semaphore.release(); } catch (Exception e) { log.error("exception", e); } countDownLatch.countDown(); }); } countDownLatch.await(); executorService.shutdown(); log.info("count:{}", count); } private static void add() { count++; // 1、count 从主存中取出count的值 // 2、+1 在工作内存中执行+1操作 // 3、count 将count的值写回主存 //及时将count用vilatile修饰,每次从主存中取到的都是最新的值,可是当多个线程同时取到最新的值,执行+1操作,当刷新到主存中的时候会覆盖结果,从而丢失一些+1操作 } }
volatile实现共享变量内存可见性有一个条件,就是对共享变量的操作必须具有原子性。比如 num = 10; 这个操作具有原子性,但是 num++ 或者num--由3步组成,并不具有原子性,所以是不行的。
假如num=5,此时有线程A从主内存中获取num的值,并执行++,但在还未见修改写入主内存中,又有线程B取得num的值,对其进行++操作,造成丢失修改,明明执行了2次++,num的值却只增加了1.
对变量的写入操作不依赖其当前值
该变量没有包含在具有其他变量的不变式中
综上,volatile特别适合用来做线程标记量,如下图

注:由于voaltile比synchronized更加轻量级,所以执行的效率肯定是比synchroized更高。在可以保证原子性操作时,可以尽量的选择使用volatile。在其他不能保证其操作的原子性时,再去考虑使用synchronized。
有序性

Happens-before原则,先天有序性,即不需要任何额外的代码控制即可保证有序性,java内存模型一个列出了八种Happens-before规则,如果两个操作的次序不能从这八种规则中推倒出来,则不能保证有序性。
第一条规则要注意理解,这里只是程序的运行结果看起来像是顺序执行,虽然结果是一样的,jvm会对没有变量值依赖的操作进行重排序,这个规则只能保证单线程下执行的有序性,不能保证多线程下的有序性。
总结

标签:exe log main ice 需要 调用 -o 修改 false
原文地址:https://www.cnblogs.com/xiangkejin/p/9249827.html
